AWS Security Blog
Detecting sensitive data in DynamoDB with Macie
Amazon Macie is a fully managed data security and data privacy service that uses machine learning and pattern matching to discover and protect your sensitive data in Amazon Web Services (AWS). It gives you the ability to automatically scan for sensitive data and get an inventory of your Amazon Simple Storage Service (Amazon S3) buckets. Macie also gives you the added ability to detect which buckets are public, unencrypted, and accessible from other AWS accounts.
In this post, we’ll walk through how to use Macie to detect sensitive data in Amazon DynamoDB tables by exporting the data to Amazon S3 so that Macie can scan the data. An example of why you would deploy a solution like this is if you have potentially sensitive data stored in DynamoDB tables. When we’re finished, you’ll have a solution that can set up on-demand or scheduled Macie discovery jobs to detect sensitive data exported from DynamoDB to S3.
Architecture
In figure 1, you can see an architectural diagram explaining the flow of the solution that you’ll be deploying.
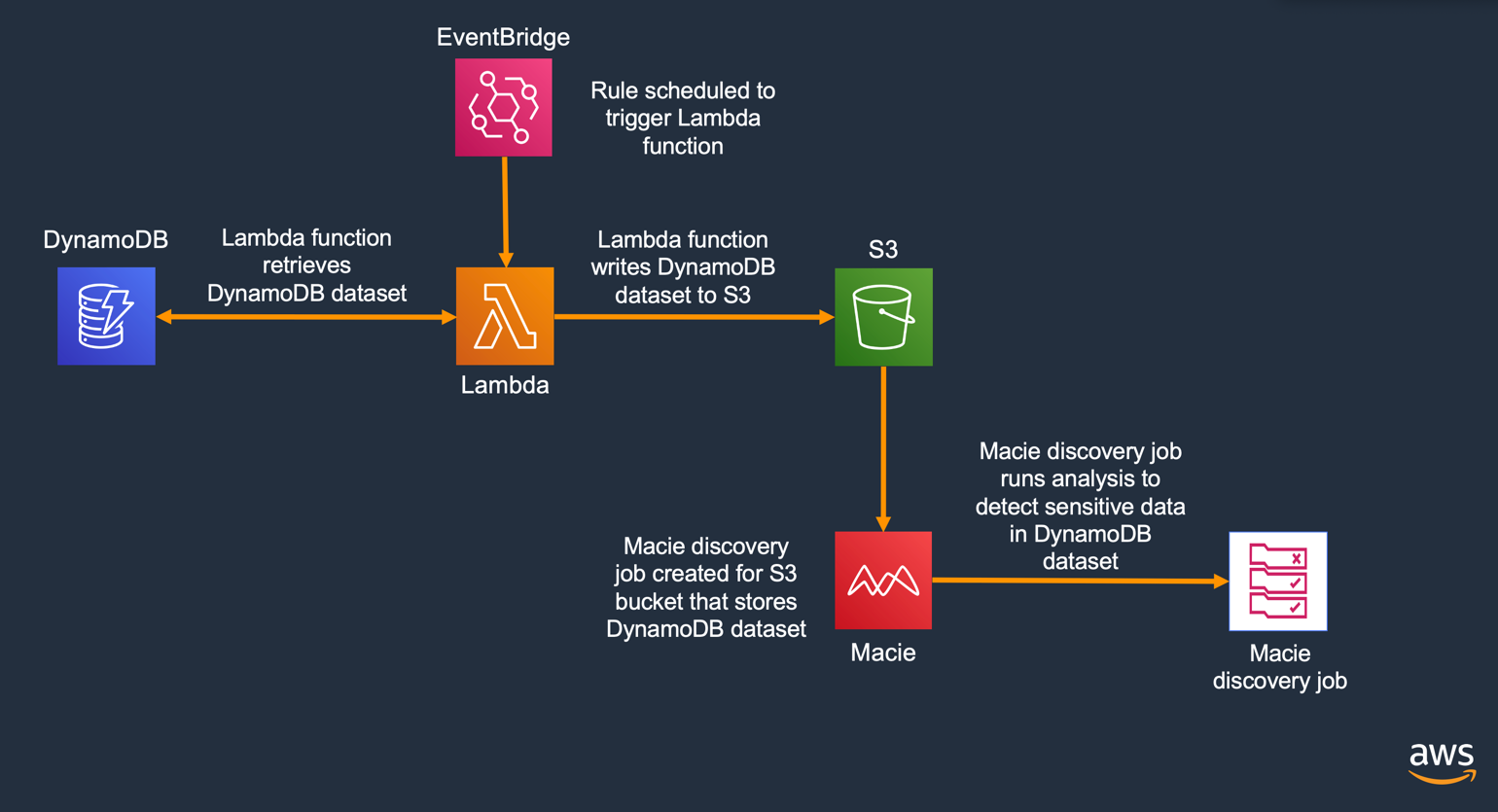
Figure 1: Solution architecture
Here’s a brief overview of the steps that you’ll take to deploy the solution. Some steps you will do manually, while others will be handled by the provided AWS CloudFormation template. The following outline describes the steps taken to extract the data from DynamoDB and store it in S3, which allows Macie to run a discovery job against the data.
- Enable Amazon Macie, if it isn’t already enabled.
- Deploy a test DynamoDB dataset.
- Create an S3 bucket to export DynamoDB data to.
- Configure an AWS Identity and Access Management (IAM) policy and role. (These are used by the Lambda function to access the S3 and DynamoDB tables)
- Deploy an AWS Lambda function to export DynamoDB data to S3.
- Set up an Amazon EventBridge rule to schedule export of the DynamoDB data.
- Create a Macie discovery job to discover sensitive data from the DynamoDB data export.
- View the results of the Macie discovery job.
The goal is that when you finish, you have a solution that you can use to set up either on-demand or scheduled Macie discovery jobs to detect sensitive data that was exported from DynamoDB to S3.
Prerequisite: Enable Macie
If Macie hasn’t been enabled in your account, complete Step 1 in Getting started with Amazon Macie to enable Macie. Once you’ve enabled Macie, you can proceed with the deployment of the CloudFormation template.
Deploy the CloudFormation template
In this section, you start by deploying the CloudFormation template that will deploy all the resources needed for the solution. You can then review the output of the resources that have been deployed.
To deploy the CloudFormation template
- Download the CloudFormation template: https://github.com/aws-samples/macie-dynamodb-blog/blob/main/src/cft.yaml
- Sign in to the AWS Management Console and navigate to the CloudFormation console.
- Choose Upload a template file, and then select the CloudFormation template that you downloaded in the previous step. Choose Next.

Figure 2 – Uploading the CloudFormation template to be deployed
- For Stack Name, name your stack macie-blog, and then choose Next.

Figure 3: Naming your CloudFormation stack
- For Configure stack options, keep the default values and choose Next.
- At the bottom of the Review screen, select the I acknowledge that AWS CloudFormation might create IAM resources check box, and then choose Create stack.

Figure 4: Acknowledging that this CloudFormation template will create IAM roles
You should then see the following screen. It may take several minutes for the CloudFormation template to finish deploying.
Figure 5: CloudFormation stack creation in progress
View CloudFormation output
Once the CloudFormation template has been completely deployed, choose the Outputs tab, and you will see the following screen. Here you’ll find the names and URLs for all the AWS resources that are needed to complete the remainder of the solution.
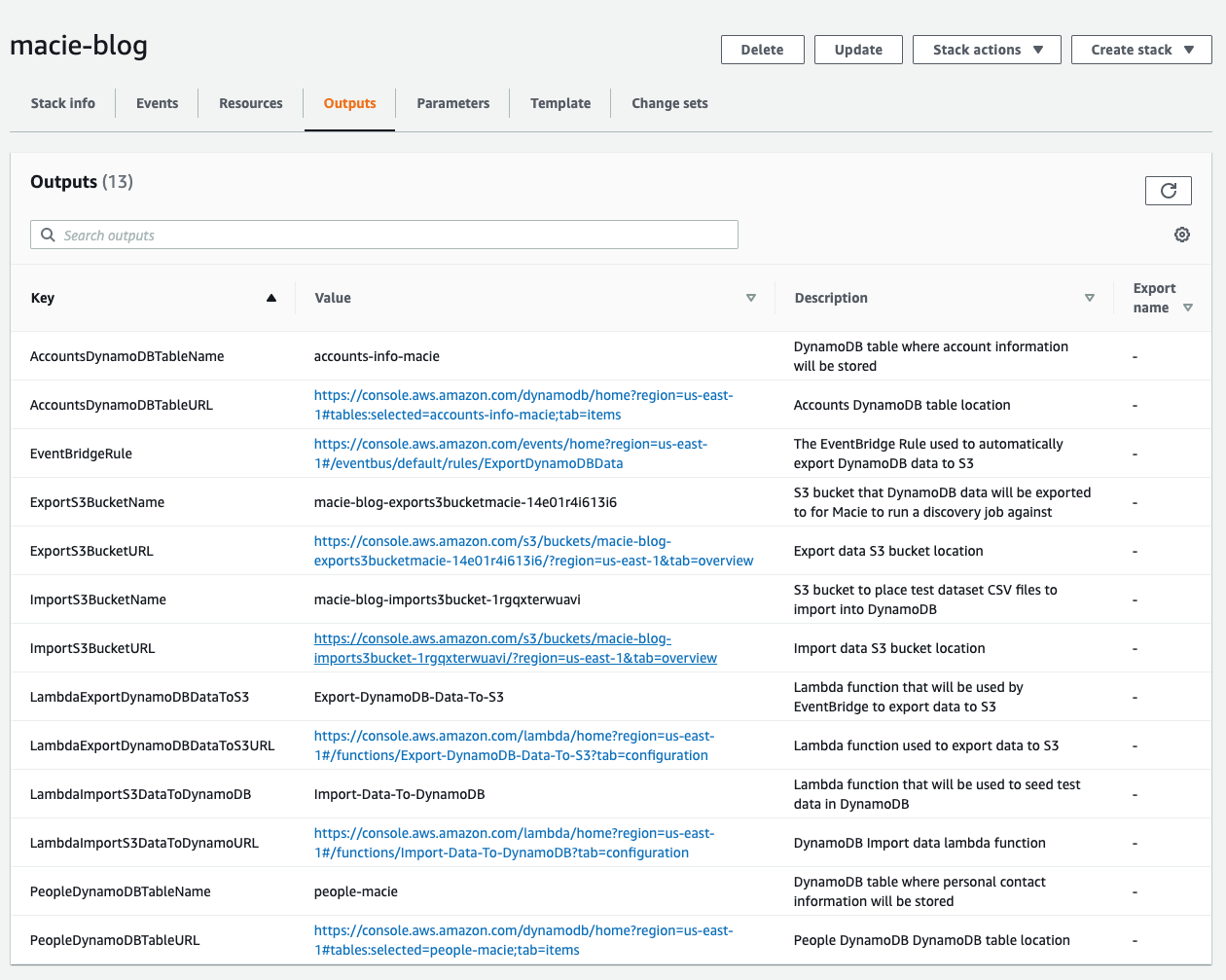
Figure 6: Completed CloudFormation stack output
For easier reference, open a new browser tab to your AWS Management Console and leave this tab open. This will make it easier to quickly copy and paste the resource URLs as you navigate to different resources during this walkthrough.
Import DynamoDB data
In this section, we walk through importing the test dataset to DynamoDB. You first start by downloading the test CSV datasets, then upload those datasets to S3 and run the Lambda function that imports the data to DynamoDB. Finally, you review the data that was imported into DynamoDB.
Test datasets
Download the following test datasets:
- Accounts Info test dataset (accounts.csv): https://github.com/aws-samples/macie-dynamodb-blog/blob/main/datasets/accounts.csv
- People test dataset (people.csv): https://github.com/aws-samples/macie-dynamodb-blog/blob/main/datasets/people.csv
Upload data to the S3 import bucket
Now that you’ve downloaded the test datasets, you’ll need to navigate to the data import S3 bucket and upload the data.
To upload the datasets to the S3 import bucket
- Navigate to the CloudFormation Outputs tab, where you’ll find the bucket information.

Figure 7: S3 bucket output values for the CloudFormation stack
- Copy the ImportS3BucketURL link and navigate to the URL.
- Upload the two test CSV datasets, people.csv and accounts.csv, to your S3 bucket.
- After the upload is complete, you should see the two CSV files in the S3 bucket. You’ll use these files as your test DynamoDB data.

Figure 8: Test S3 datasets in the S3 bucket
View the data import Lambda function
Now that you have your test data staged for loading, you’ll import it into DynamoDB by using a Lambda function that was deployed with the CloudFormation template. To start, navigate to the CloudFormation console and get the URL to the Lambda function that will handle the data import to DynamoDB, as shown in figure 9.

Figure 9: CloudFormation output information for the People DynamoDB table
To run the data import Lambda function
- Copy the LambdaImportS3DataToDynamoURL link and navigate to the URL. You will see the Import-Data-To-DynamoDB Lambda function, as shown in figure 10.

Figure 10: The Lambda function that imports data to DynamoDB
- Choose the Test button in the upper right-hand corner. In the dialog screen, for Event name, enter Test and replace the value with {}.
- Your screen should now look as shown in figure 11. Choose Create.

Figure 11: Configuring a test event to manually run the Lambda function
- Choose the Test button again in the upper right-hand corner. You should now see the Lambda function running, as shown in figure 12.

Figure 12: View of the Lambda function running
- Once the Lambda function is finished running, you can expand the Details section. You should see a screen similar to the one in figure 13. When you see this screen, the test datasets have successfully been imported into the DynamoDB tables.

Figure 13: View of the data import Lambda function after it runs successfully
View the DynamoDB test dataset
Now that you have the datasets imported, you can look at the data in the console.
To view the test dataset
- Navigate to the two DynamoDB tables. You can do this by getting the URL values from the CloudFormation Outputs tab. Figure 14 shows the URL for the accounts tables.

Figure 14: Output values for CloudFormation stack DynamoDB account tables
Figure 15 shows the URL for the people tables.

Figure 15: Output values for CloudFormation stack DynamoDB people tables
- Copy the AccountsDynamoDBTableURL link value and navigate to it in the browser. Then choose the Items tab.

Figure 16: View of DynamoDB account-info-macie table data
You should now see a screen showing data similar to the screen in figure 16. This DynamoDB table stores the test account data that you will use to run a Macie discovery job against after the data has been exported to S3.
- Navigate to the PeopleDynamoDBTableURL link that is in the CloudFormation output. Then choose the Items tab.

Figure 17: View of DynamoDB people table data
You should now see a screen showing data similar to the screen in figure 17. This DynamoDB table stores the test people data that you will use to run a Macie discovery job against after the data has been exported to S3.
Export DynamoDB data to S3
In the previous section, you set everything up and staged the data to DynamoDB. In this section, you will export data from DynamoDB to S3.
View the EventBridge rule
The EventBridge rule that was deployed earlier allows you to automatically schedule the export of DynamoDB data to S3. You will can export data in hours, in minutes, or in days. The purpose of the EventBridge rule is to allow you to set up an automated data pipeline from DynamoDB to S3. For demonstration purposes, you’ll run the Lambda function that the EventBridge rule uses manually, so that you can see the data be exported to S3 without having to wait.
To view the EventBridge rule
- Navigate to the CloudFormation Outputs tab for the CloudFormation stack you deployed earlier.

Figure 18: CloudFormation output information for the EventBridge rule
- Navigate to the EventBridgeRule link. You should see the following screen.

Figure 19: EventBridge rule configuration details page
On this screen, you can see that we’ve set the event schedule to run every hour. The interval can be changed to fit your business needs. We have set it for 1 hour for demonstration purposes only. To make changes to the interval, you can choose the Edit button to make changes and then save the rule.
In the Target(s) section, we’ve configured a Lambda function named Export-DynamoDB-Data-To-S3 to handle the process of exporting data to the S3 bucket the Macie discovery job will run against. We will cover the Lambda function that handles the export of the data from DynamoDB next.
View the data export Lambda function
In this section, you’ll take a look at the Lambda function that handles the exporting of DynamoDB data to the S3 bucket that Macie will run its discovery job against.
To view the Lambda function
- Navigate to the CloudFormation Outputs tab for the CloudFormation stack you deployed earlier.

Figure 20: CloudFormation output information for the Lambda function that exports DynamoDB data to S3
- Copy the link value for LambdaExportDynamoDBDataToS3URL and navigate to the URL in your browser. You should see the Python code that will handle the exporting of data to S3. The code has been commented so that you can easily follow it and refactor it for your needs.
- Scroll to the Environment variables section.

Figure 21: Environment variables used by the Lambda function
You will see two environment variables:
- bucket_to_export_to – This environment variable is used by the function as the S3 bucket location to save the DynamoDB data to. This is the bucket that the Macie discovery will run against.
- dynamo_db_tables – This environment variable is a comma-delimited list of DynamoDB tables that will be read and have data exported to S3. If there was another table that you wanted to export data from, you would simply add it to the comma-delimited list and it would be part of the export.
Export DynamoDB data
In this section, you will manually run the Lambda function to export the DynamoDB tables data to S3. As stated previously, you would normally allow the EventBridge rule to handle the automated export of the data to S3. In order to see the export in action, you’re going to manually run the function.
To run the export Lambda function
- In the console, scroll back to the top of the screen and choose the Test button.
- Name the test dynamoDBExportTest, and for the test data create an empty JSON object “{}” as shown in figure 22.

Figure 22: Configuring a test event to manually test the data export Lambda function
- Choose Create.
- Choose the Test button again to run the Lambda function to export the DynamoDB data to S3.

Figure 23: View of the screen where you run the Lambda function to export data
- It could take about one minute to export the data from DynamoDB to S3. Once the Lambda function exports the data, you should see a screen similar to the following one.

Figure 24: The result after you successfully run the data export Lambda function
View the exported DynamoDB data
Now that the DynamoDB data has been exported for Macie to run discovery jobs against, you can navigate to S3 to verify that the files exported to the bucket.
To view the data, navigate to the CloudFormation stack Output tab. Find the ExportS3BucketURL, shown in figure 25, and navigate to the link.

Figure 25: CloudFormation output information for the S3 buckets that the DynamoDB data was exported to
You should then see two different JSON files for the two DynamoDB tables that data was exported from, as shown in figure 26.

Figure 26: View of S3 objects that were exported to S3
This is the file naming convention that’s used for the files:
Next, you’ll create a Macie discovery job to run against the files in this S3 bucket to discover sensitive data.
Create the Macie discovery job
In this section, you’ll create a Macie discovery job and view the results after the job has finished running.
To create the discovery job
- In the AWS Management Console, navigate to Macie. In the left-hand menu, choose Jobs.

Figure 27: Navigation menu to Macie discovery jobs
- Choose the Create job button.

Figure 28: Macie discovery job list screen
- Using the Bucket Name filter, search for the S3 bucket that the DynamoDB data was exported to. This can be found in the CloudFormation stack output, as shown in figure 29.

Figure 29: CloudFormation stack output
- Select the value you see for ExportS3BucketName, as shown in figure 30.
Note: The value you see for your bucket name will be slightly different, based on the random characters added to the end of the bucket name generated by CloudFormation.

Figure 30: Selecting the S3 bucket to include in the Macie discovery job
- Once you’ve found the S3 bucket, select the check box next to it, and then choose Next.
- On the Review S3 Buckets screen, if you’re satisfied with the selected buckets, choose Next.
Following are some important options when setting up Macie data discovery jobs.
Scheduling
You have the following scheduling options for the data discovery job:
- Daily
- Weekly
- Monthly
Data Sampling
This allows you to randomly sample a percentage of the data that the Macie discovery job will run against.
Object criteria
This enables you to target objects based on certain metadata values. The values are:
- Tags – Target objects with certain tags.
- Last modified – Target objects based on when they were last modified.
- File extensions – Target objects based on file extensions.
- Object size – Target objects based on the file size.
You can include or exclude objects based on these object criteria filters.
Set the discovery job scope
For demonstration purposes, this will be a one-time discovery job.
To set the discovery job scope
- On the Scope page that appears after you create the job, set the following options for the job scope:
- Select the One-time job option.
- Leave Sampling depth set to 100%, and choose Next.

Figure 31: Selecting the objects that should be in scope for this discovery job
- On the Custom data identifiers screen, select account_number, and then choose Next.With the custom identifier, you can create custom business logic to look for certain patterns in files stored in S3. In this example, the job generates a finding for any file that contains data with the following format:
Account Number Format: Starts with “XYZ-” followed by 11 numbers
The logic to create a custom data identifier can be found in the CloudFormation template.

Figure 32: Custom data identifiers
- Give your discovery job the name dynamodb-macie-discovery-job. For Description, enter Discovery job to detect sensitive data exported from DynamoDB, and choose Next.

Figure 33: Giving the Macie discovery job a name and description
You will then see the Review and create screen, as shown in figure 34.

Figure 34: The Macie discovery job review screen
Note: Macie must have proper permissions to decrypt objects that are part of the Macie discovery job. The CloudFormation template that you deployed during the initial setup has already deployed an AWS Key Management Service (AWS KMS) key with the proper permissions.
For this proof of concept you won’t store the results, so you can select the check box next to Override this requirement. If you wanted to store detailed results of the discovery job long term, you would configure a repository for data discovery results. To view detailed steps for setting this up, see Storing and retaining discovery results with Amazon Macie.
Submit the discovery job
Next, you can submit the discovery job. On the Review and create screen, choose the Submit button to start the discovery job. You should see a screen similar to the following.
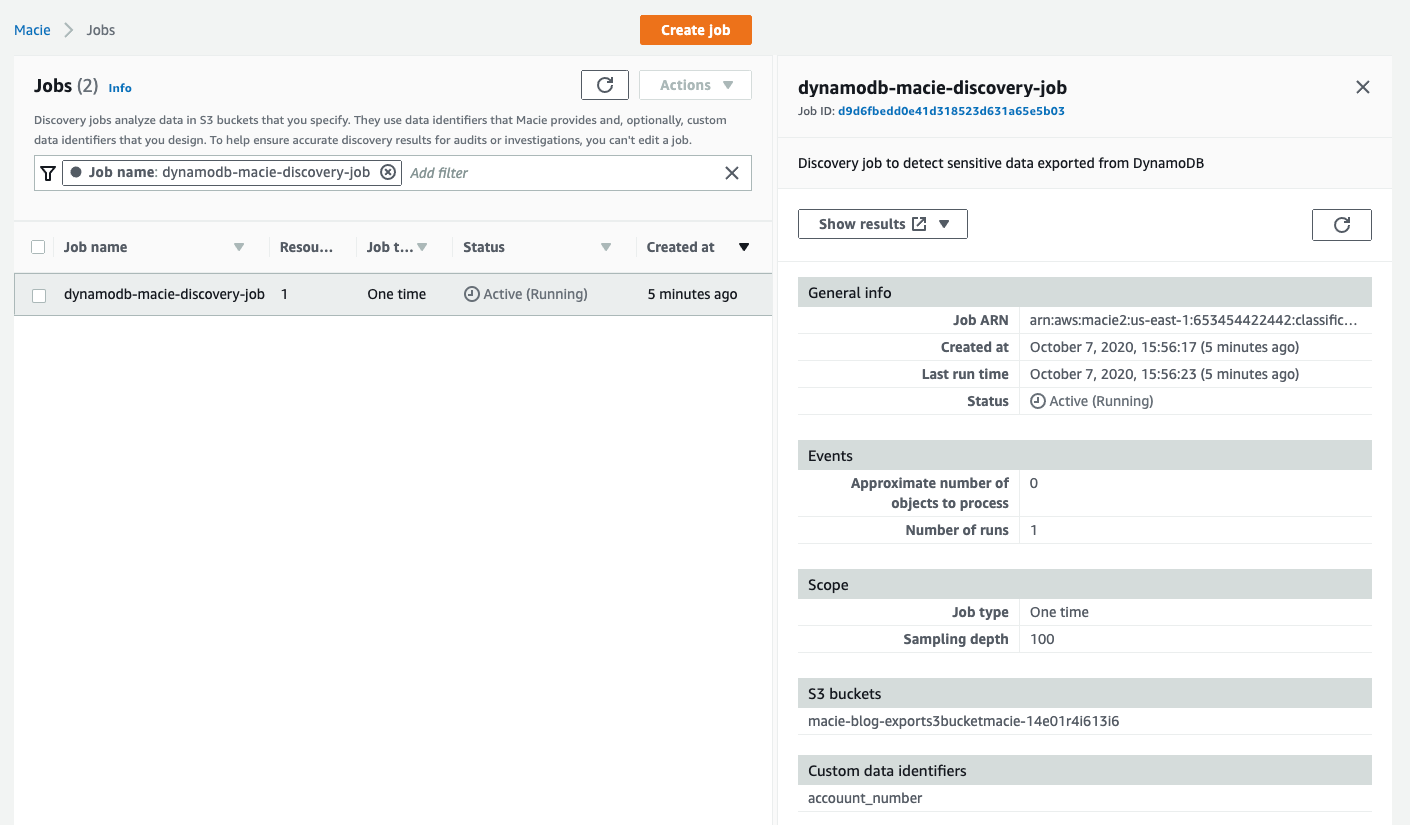
Figure 35: A Macie discovery job run that is in progress
The amount of data that is being scanned dictates how long the job will take to run. You can choose the Refresh button at the top of the screen to see the updated status of the job. This job, based on the size of the test dataset, will take about seven minutes to complete.
Review the job results
Now that the Macie discovery job has run, you can review the results to see what sensitive data was discovered in the data exported from DynamoDB.
You should see the following screen once the job has successfully run.
Figure 36: View of the completed Macie discovery job
On the right, you should see another pane with more information related to the discovery job. The pane should look like the following screen.
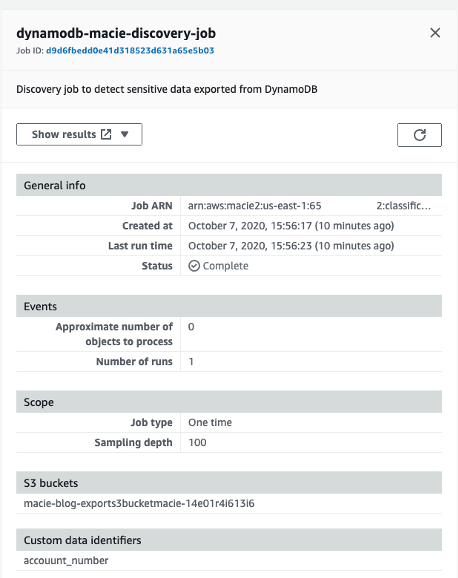
Figure 37: Summary showing which S3 bucket the discovery job ran against and start and complete time
Note: If you don’t see this pane, choose on the discovery job to have this information displayed.
To review the job results
- On the page for the discovery job, in the Show Results list, select Show findings.

Figure 38: Option to view discovery job findings
- The Findings screen appears, as follows.

Figure 39: Viewing the list of findings generated by the Macie discovery job
The discovery job that you ran has two different “High Severity” finding types:
SensitiveData:S3Object/Personal – The object contains personal information, such as full names or identification numbers.
SensitiveData:S3Object/Multiple – The object contains more than one type of sensitive data.
- Choose the SensitiveData:S3Object/Personal finding type, and you will see an information pane appear to the right, as shown in figure 40.Some of the key information that you can find here:
Severity – What the severity of the finding is: Low, Medium, or High.
Resource – The S3 bucket where the S3 object exists that caused the finding to be generated.
Region – The Region where the S3 bucket exists.
Figure 40: Viewing the severity of the discovery job finding
Since the finding is based on the detection of personal information in the S3 object, you get the number of times and type of personal data that was discovered, as shown in figure 41.

Figure 41: Viewing the number of social security numbers that were discovered in the finding
Here you can see that 10 names were detected in the data that you exported from the DynamoDB table. Occurrences of name equals 10 line ranges, which tells you that the names were found on 10 different lines in the file. If you choose the 10 line ranges link, you are given the starting line and column in the document where the name was discovered.
The S3 object that triggered the finding is displayed in the Resource affected section, as shown in figure 42.

Figure 42: The S3 object that generated the Macie finding
Now that you know which S3 object contains the sensitive data, you can investigate further to take appropriate action to protect the data.
View the Macie finding details
In this section, you will walk through how to read and download the objects related to the Macie discovery job.
To download and view the S3 object that contains the finding
- In the Overview section of the finding details, select the value for the Resource link. You will then be taken to the object in the S3 bucket.

Figure 43: Viewing the S3 bucket where the object is located that generated the Macie finding
- You can then download the S3 object from the S3 bucket to view the file content and further investigate the file content for sensitive data. Select the check box next to the S3 object, and choose the Download button at the top of the screen.Next, we will look at the SensitiveData:S3Object/Multiple finding type that was generated. This finding type lets us know that there are multiple types of potentially sensitive data related to an object stored in S3.
- In the left navigation menu, navigate back to the Jobs menu.
- Choose the job that you created in the previous steps. In the Show Results list, select Show Findings.
- Select the SensitiveData:S3Object/Multiple finding type. An information pane appears to the right. As with the previous finding, you will see the severity, Region, S3 bucket location, and other relevant information about the finding. For this finding, we will focus on the Custom data identifiers and Personal info sections.

Figure 44: Details about the sensitive data that was discovered by the Macie discovery job
Here you can see that the discovery job found 10 names on 10 different lines in the file. Also, you can see that 10 account numbers were discovered on 10 different lines in the file, based on the custom identifier that was included as part of the discovery job.
This finding demonstrates how you can use the built-in Macie identifiers, such as names, and also include custom business logic based on your organization’s needs by using Macie custom data identifiers.
To view the data and investigate further, follow the same steps as in the previous finding you investigated.
- Navigate to the top of the screen and in the Overview section, locate the Resource.

Figure 45: Viewing the S3 bucket where the object is located that generated the Macie finding
- Choose Resource, which will take you to the S3 object to download. You can now view the contents of the file and investigate further.
You’ve now created a Macie discovery job to scan for sensitive data stored in an S3 bucket that originated in DynamoDB. You can also automate this solution further by using EventBridge rules to detect Macie findings to take actions against those objects with sensitive data.
Solution cleanup
In order to clean up the solution that you just deployed, complete the following steps. Note that you need to do these steps to stop data from being exported from DynamoDB to S3 every 1 hour.
To perform cleanup
- Navigate to the S3 buckets used to import and export data. You can find the bucket names in the CloudFormation Outputs tab in the console, as shown in figure 7 and figure 25.
- After you’ve navigated to each of the buckets, delete all objects from the bucket.
- Navigate to the CloudFormation console, and then delete the CloudFormation stack named macie-blog. After the stack is deleted, the solution will no longer be deployed in your AWS account.
Summary
After deploying the solution, we hope you have a better understanding of how you can use Macie to detect sensitive from other data sources, such as DynamoDB, as outlined in this post. The following are links to resources that you can use to further expand your knowledge of Amazon Macie capabilities and features.
Additional resources
- Types of Amazon Macie findings
- Storing and retaining discovery results with Amazon Macie
- Analyzing encrypted S3 objects with Amazon Macie
- Supported file and storage formats in Amazon Macie
- Managing multiple accounts in Amazon Macie
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.