Artificial Intelligence
Apache MXNet Release Adds Support for New NVIDIA Volta GPUs and Sparse Tensor
We are excited about the availability of Apache MXNet version 0.12. Contributors in the MXNet community have collaborated to bring new feature enhancements to users. With this release, MXNet adds two new important features:
- Support for NVIDIA Volta GPUs, which enable users to dramatically reduce the training and inference time for a neural network model.
- Support for Sparse Tensors, which enable users to train a model with sparse matrices in a storage- and compute-efficient manner.
Support for NVIDIA Volta GPU architecture
The MXNet v0.12 release adds support for NVIDIA Volta V100 GPUs, enabling customers to train convolutional neural networks up to 3.5 times faster than on the Pascal GPUs. Training a neural network involves trillions of floating-point (FP) multiplications and additions. These calculations have typically been done using single precision (FP32) to achieve high accuracy. However, recent research has shown that users can achieve the same accuracy with training using half-precision (FP16) data types as they can with training using FP32 data types.
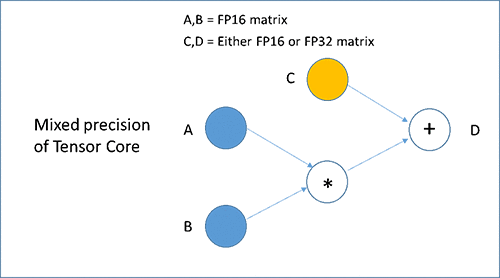
The Volta GPU architecture introduces Tensor Cores. Each Tensor Core can execute 64 fuse-multiply-add ops per clock, which roughly quadruples the CUDA core FLOPS per clock per core. Each Tensor Core performs D = A x B + C as shown below, where A and B are half-precision matrices, while C and D can be either half or single-precision matrices, thereby performing mixed precision training. The new mixed-precision training allows users to achieve optimal training performance without sacrificing accuracy by using FP16 for most of the layers of a network and using higher precision data types only when necessary.
MXNet makes it easy for users to train a model using FP16 to take advantage of the Volta Tensor Cores. For example, you can simply enable FP16 training in MXNet by passing the following command option to the train_imagenet.py script.
Recently we announced a new set of AWS Deep Learning AMIs, which come pre-installed with various deep learning frameworks including MXNet v0.12, optimized for the NVIDIA Volta V100 GPUs in the Amazon EC2 P3 instance family. You can start with just one click from the AWS Marketplace, or you can follow this step-by-step guide to get started with your first notebook.
Sparse tensor support
MXNet v0.12 adds support for sparse tensors to efficiently store and compute tensors for which the majority of elements are zeros. We’re all familiar with recommendations on Amazon based on your past purchasing history, and with show recommendations on Netflix based on your past viewing history and the ratings you’ve given to other shows. Such deep-learning-based recommendation engines for millions of people involve multiplications and additions of sparse matrices for which the majority of elements are zeros. Performing trillions of matrix operations between sparse matrices in the same way that these operations are performed between dense matrices is not efficient in terms of storage and compute. Storing and manipulating such sparse matrices with many zero elements in the default dense structure results in wasted memory and unnecessary processing on the zeros.
To address such pain points, MXNet enables sparse tensor support that allows MXNet users to perform sparse matrix operations in a storage and compute-efficient manner and train deep learning models faster. MXNet v0.12 supports two major sparse data formats:. Compressed Sparse Row (CSR) and Row Sparse (RSP). The CSR format is optimized to represent matrices with a large number of columns where each row has only a few non-zero elements. The RSP format is optimized to represent matrices with a huge number of rows where most of the row slices are completely zeros. For example, the CSR format can be used to encode the feature vectors of input data for a recommendation engine, whereas the RSP format can be used to perform the sparse gradient updates during training. This release enables sparse support on CPUs for most commonly used operators, such as matrix dot product and element-wise operators. Sparse support for more operators will be added in future releases.
The following code snippet demonstrates how you can convert a scipy CSR matrix to an MXNet CSR format and perform a sparse matrix-vector multiplication of it with a vector of ones. To learn more about using the new sparse operators in MXNet, see these tutorials.
Next steps
Getting started with MXNet is simple. A full list of the changes in this release can be found in the release notes. If you have questions or suggestions, please leave a comment.
About the Author
 Sukwon Kim is a Senior Product Manager for AWS Deep Learning. He works on products that make it easier for customers to use deep learning engines with a specific focus on the open source Apache MXNet engine. In his spare time, he enjoys hiking and traveling.
Sukwon Kim is a Senior Product Manager for AWS Deep Learning. He works on products that make it easier for customers to use deep learning engines with a specific focus on the open source Apache MXNet engine. In his spare time, he enjoys hiking and traveling.