AWS Partner Network (APN) Blog
3 Simple Ways to Use FactSet’s Financial Data in AWS Workflows
By Brian J. Bernstein, Partner Solutions Architect – AWS
By Sonia Greenberg, VP Product Management – FactSet
 |
| FactSet |
 |
Within financial services, companies are looking for ways to create scalable, easy to maintain, and modern infrastructures for their data and applications.
The importance of moving their content consumption to the cloud has increased as a means of achieving this. Key to the technological advantage is access to high-quality data in a timely manner without the need for non-value extract, transform, load (ETL) tasks.
Many institutions in financial services are in the early stages of their cloud journey. While each has their own IT landscape and cloud strategy, one question is common among many organizations: “How can I simplify my data ingest pipelines to increase productivity, time to value, and optimize costs when I migrate to AWS?”
FactSet, an AWS Partner and AWS Marketplace Seller that is a leading provider of financial services market and alternative data, can help consumers access their data in simple and scalable ways, while removing the administrative tasks that do not add value to the business. FactSet provides ways to consume data in a customer’s Amazon Web Services (AWS) account.
In this post, we’ll cover three easy ways FactSet makes its data available to their customers on AWS through Amazon Redshift and Amazon Simple Storage Service (Amazon S3).
How Financial Data is Consumed Traditionally
Financial services companies consume large amounts of data from a number of sources which are fed in through a variety of ways: HTTP, SFTP, email, direct file sharing, and direct streaming. In some cases, data comes in over the internet, while other data may require special hardware and leased connections from an internet provider into the data center.
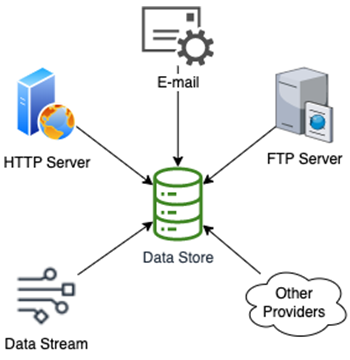
Figure 1 – Traditional data ingress.
Knowing when the data is updated further complicates things, as some providers require changes to be polled by the consumer or get sent via email notification. Once a consumer has the data they need, massaging it into a usable form takes time and processing.
FactSet and AWS come together to optimize the delivery, notification, and storage of datasets that are critical to financial services workflows. Below are three mechanisms which customers of FactSet data can leverage to gain these benefits.
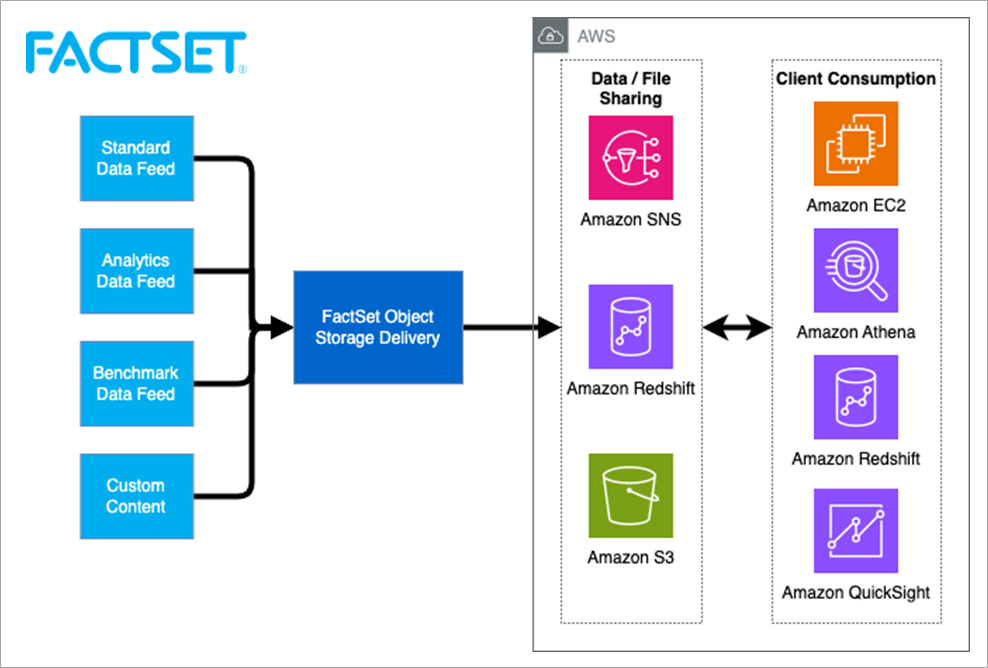
Figure 2 – FactSet delivery solution.
#1 – Zero Copy Share via Amazon Redshift
Amazon Redshift data sharing is a means of securely and easily sharing data across Redshift clusters. This enables a customer to have instant, granular, and high-performance data access to FactSet’s Redshift clusters without the need to copy it into their own cluster—all they have to do is spin compute on that data.
Data sharing also provides live access to data so the customer always sees the most up-to-date and consistent information as it’s updated by FactSet.
FactSet makes 90+ content sets available on Amazon Redshift with a few simple steps. These content sets can be accessed on your AWS account either through bring-your-own-license (BYOL), FactSet’s catalog, or AWS Data Exchange.
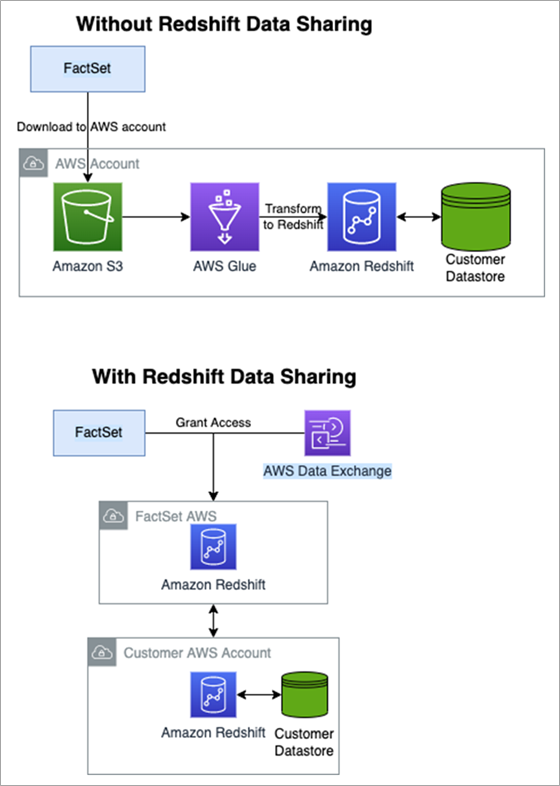
Figure 3 – How FactSet’s structured data is shared with Redshift.
The ability to run SQL queries on FactSet’s data along with a customer’s own data accelerates data-led insights by removing complex ETL and taking advantage of Redshift’s speed and scale alongside the customer’s proprietary data.
Furthermore, a customer can have their cluster located anywhere in the world, as the shared datasets are globally accessible. There are no data movements as a result of data sharing; live and transactional data is shared in-place through Redshift managed storage.
#2 – Object Storage into Your Data Lake
Organizations in many situations have turned to a data lake as a means of solving challenges associated with the traditional data warehouse, such as the ability to store unstructured, semi-structured, and structured data in one cost-efficient location.
Since FactSet’s data offerings include structured and unstructured sets, it may be suitable for an organization to leverage a data lake instead of transforming into a structured data store.
Regardless of which platform is used to create the data lake—AWS Lake Formation, for example— the concept is the same: the customer has several sources of data in their AWS cloud they want to bring together and have a uniform means of joining that data together.
With FactSet’s data offerings, these can be tied into an organization’s data lake as a Redshift source or Amazon S3 access point. The following sample demonstrates how this could look.
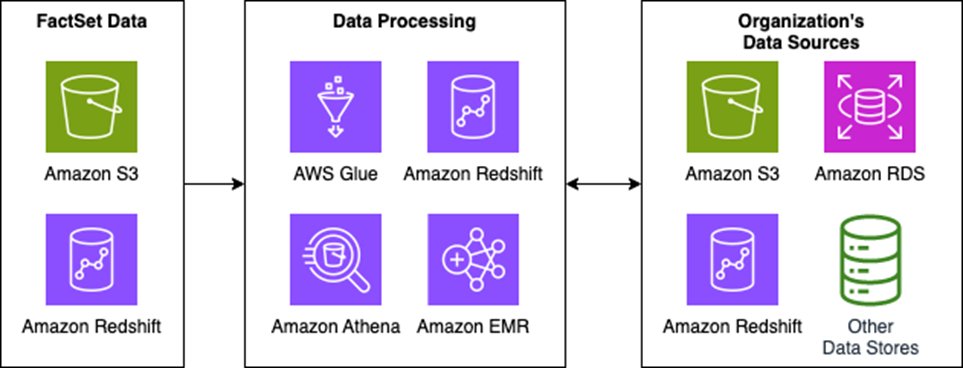
Figure 4 – Redshift, S3, and other data sources into a compute center.
Customers have the ability to copy files into their data lake hosted on their own Amazon S3 storage. However, through the use of S3 access points, FactSet’s data can be used directly by an organization’s data processing infrastructure without having to first copy the data over.
The advantage of having the latest versions of FactSet’s data available for processing the moment it’s available without delay, processing, or extra infrastructure is only made possible in a cloud-native delivery mechanism.
#3 – Querying FactSet Data Directly with Amazon Athena
Some customers may want to consume data directly from FactSet and not store it in their own Amazon S3 or data lake. Whether it’s storage cost, file management, or simply the need to only pull out a relatively small amount of data from a large dataset, customers can query FactSet’s S3 data directly by using Amazon Athena.

Figure 5 – Leveraging FactSet data with Amazon Athena.
Every customer of FactSet data on AWS is provided an S3 access point and access point alias, the latter of which can be used like an S3 bucket name in a variety of AWS services that can source data from S3. This alias, along with a data schema definition in Athena, can be used to deliver query results with Athena SQL.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. For this use case, a customer would use AWS Glue crawlers to discover the FactSet data and define the schema definition for Athena.
Amazon Athena is an interactive query service that makes it easy to analyze data in S3 using standard SQL. In this use case, Athena is used to query and join FactSet data in order to prepare it for integration into a service such as Amazon QuickSight.
AWS Glue and Amazon Athena are key AWS services for asset managers getting started with environmental, social, and governance (ESG) data that can help them overcome the integration barriers highlighted in this post.
Conclusion
Data management can seem daunting, especially when trying to break down huge monolithic infrastructures companies have built over decades. However, the growth of technical users, the need to evaluate new datasets quickly, and ever-growing data require companies to find a better solution.
The collaboration between AWS and FactSet enables instant access to 90+ financial and alternative datasets. Without the need to obtain and transform the data, value can be derived in minutes and the flexibility does not stop there. Browse and purchase FactSet’s data offerings either through FactSet’s catalog or AWS Data Exchange, or leverage the ability to bring your own license (BYOL) you already have through FactSet.
FactSet aims to remove the burden of data management in the AWS ecosystem. If you want to find out more about their data catalog, visit FactSet. You can also learn more about FactSet in AWS Marketplace.
.

.
FactSet – AWS Partner Spotlight
FactSet is an AWS Partner and a leading provider of financial services market and alternative data that helps organizations drive productivity and performance and make better investment decisions.
Contact Partner | Partner Overview | AWS Marketplace | Case Studies