AWS Partner Network (APN) Blog
Accelerate Data Exchange and Collaborative Analytics Within Your Enterprise Using Amazon Redshift
By Susanta Mohanty, Data Engineering Associate Director, Cloud First – Accenture
By Soonam Kurian, Sr. Solutions Architect, Accenture AWS Business Group – AWS
 |
| Accenture |
 |
The data landscape has been evolving over the years—traditionally, enterprises did not have an overall strategy to ingest, transform, govern, secure, and access data. This resulted in data silos and a heterogeneous and disorganized data ecosystem, leading to traditional siloed architectures.
Data governance was an afterthought which led to challenges with data consistency, lack of trust in the data, and performance issues with operational systems, to name a few.
Paradigms eventually shifted, and for many years building a centralized data platform has been a high priority for many large and small enterprises. This enabled organizations to extract insights and add value to their operations while reducing technical debt. It also helped standardize the way data is ingested, transformed, and consumed by having a single enterprise-wide methodology to process data.
This centralized approach often comes at a price, however. It can create bottlenecks and a single point of failure in the architecture, as well as challenges with scaling, ownership, and accounting.
A newer, data-as-a-product paradigm combines the best of both worlds and helps make data more consumable while promoting domain-oriented decentralization of ownership.
In this post, we will provide a perspective on how Accenture helps enterprises implement decentralized domain-driven architectures and deliver data products by leveraging Amazon Web Services (AWS).
In particular, we’ll review how new features in Amazon Redshift, such as data sharing and integration with AWS Data Exchange, can help accelerate time-to-market delivery of data products to increase business value.
Accenture is an AWS Premier Tier Services Partner and leading global professional services company with 20+ AWS Competencies. Accenture is also a member of eight AWS Partner Programs including the AWS Managed Service Provider (MSP) and Well-Architected Partner Programs.
How De-Centralized Patterns Can Help
A distributed domain-driven architecture is built on the concept of decomposing the systems into distributed services built around business domain capabilities. Application of this paradigm in data platform architecture leads to the concept of data mesh as a platform—distributed data products oriented around domains and owned by independent cross-functional teams.
The data mesh approach leaves in place centralized standards and policies, but opens the opportunity to a broader audience to self-serve their data. More importantly, it contributes to the creation, curation, enrichment, and amalgamation of new data products, exposing them to the enterprise in an easy-to-consume way.
A data mesh is built on key principles of domain ownership, offering data as a product, maintaining a self-serve data platform, and federated governance.
This new approach empowers enterprise users to push their data back into the ecosystem for others to benefit from, and they are not limited by centralized teams and their ability to scale to meet the demands of the business.
Implementing De-Centralized Architectures
A modern data architecture on AWS extends the traditional data lake platform. It allows building scalable, cost-effective data lakes but also supports simplified governance and data movement between various data stores.
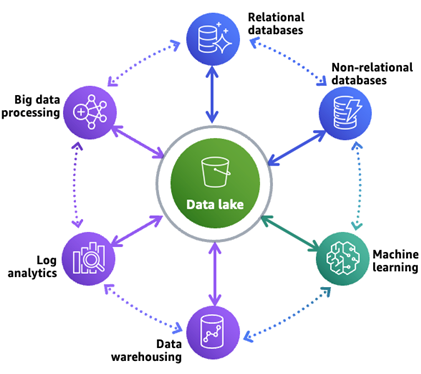
Figure 1 – Modern data architecture on AWS.
As shown in the diagram above, this approach helps organize data in the central data lake as well as in purpose-built data stores that work alongside the data lake.
This design facilitates three patterns of data movement: inside-out, outside-in, and around the perimeter data movement amongst a data lake, a data warehouse, and other purpose-built data stores.
It enables unified governance and seamless data movement, and is characterized by a scalable data lake, data-diversity managed via an array of purpose-built data stores, seamless data movement, unified governance, and performance and cost effectiveness.
A data mesh architecture on AWS marks a welcome architectural and organizational paradigm shift in how organizations manage large analytical datasets. Rather than try to combine multiple domains into a centrally managed data lake, data is intentionally left distributed.
A data mesh is founded on four principles:
- Domain-oriented decentralization of ownership and architecture.
- Data served as a product.
- Federated data governance with centralized audit controls.
- Common access that makes data consumable.
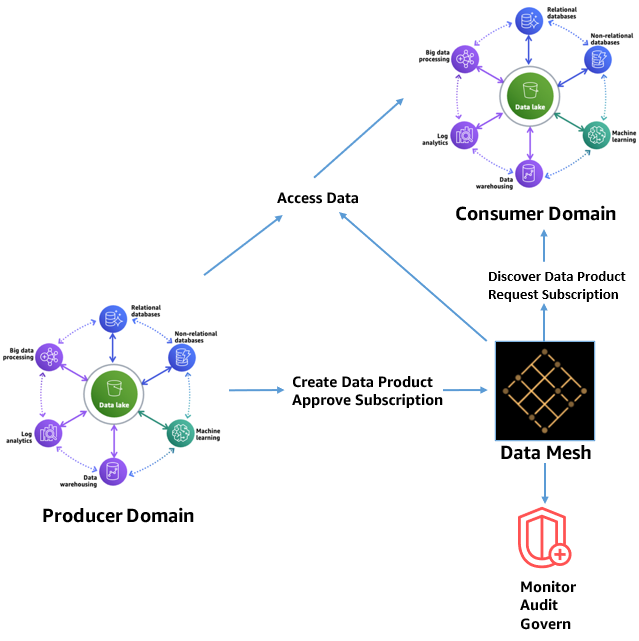
Figure 2 – Data mesh architecture on AWS.
As depicted in the diagram above, a data mesh architecture aims to enable self-service data product creation, discovery and subscription, and allow consumers to transparently access data products. This increases data security and compliance within domains and enables monitoring, auditing, and governance over time.
Accelerate Data Exchange Using Amazon Redshift
Amazon Redshift accelerates your time to insights with fast, easy, and secure cloud data warehousing at scale. It provides multiple features to help analyze data while providing performance at scale at optimized costs.
Included below are a few key features that facilitate faster insights:
- Federated query: This capability enables querying data in operational relational databases, and Amazon Redshift Spectrum allows to query data directly from files on Amazon Simple Storage Service (Amazon S3).
- Data sharing: This is for cross group-collaboration and data as a service.
- AWS Data Exchange for Amazon Redshift: This enables users to find and subscribe to third-party data in AWS Data Exchange that you can query in a Redshift data warehouse in minutes. You can also license your data in Redshift through AWS Data Exchange.
Sample Use Case #1: Enhance Market Visibility
In this section, we will highlight Amazon Redshift’s live data sharing capability and how it can securely share live data between clusters maintained by separate departments.
Let’s review a use case for a retail company that wants to use data residing in individual clusters for ‘Customer360’ and ‘Sales’ transactions to gather insights on sales by customer demography and come up with effective marketing campaigns.
Without data sharing in place, the company would need to run nightly extract, transform, load (ETL) jobs to extract information from the Sales and Customer360 clusters to perform sales analytics. This leads to several challenges, including not having access to live data, complex and costly data movement flows, and data redundancy and duplication across multiple clusters.

Figure 3 – Simplify cross-functional analytics using Redshift data sharing.
With Redshift data sharing in place, the company can eliminate the need for complex data movement and benefit from data shared live securely and instantly between clusters, which promotes cross-group collaboration.
To get started with data sharing, a data share is created in both Customer360 and Sales producer clusters, and objects to be shared are added to the data shares. You may also add optional security restrictions such as creating views on top of shared objects, exposing only the necessary data to the data share.
The Sales Analytics consumer is granted access to the data shares. Analytics can now be run in the Sales Analytics cluster and visualized as required using Amazon QuickSight. In addition, machine learning (ML) models can be created, trained, and deployed using the data residing in Redshift.
Redshift data sharing can be done within the same AWS account or across AWS accounts, with different lines of business or third-party organizations. It democratizes data by promoting self-service access, as data is no longer available only to super users. The extended user community can create their own use cases and perform data analysis with the data already accessible to them, as well as create dashboards in QuickSight for visualization.
Sample Use Case #2: Simplify Workload Isolation and Chargeability
Another great use case for Amazon Redshift data sharing is to achieve workload isolation and chargeability.
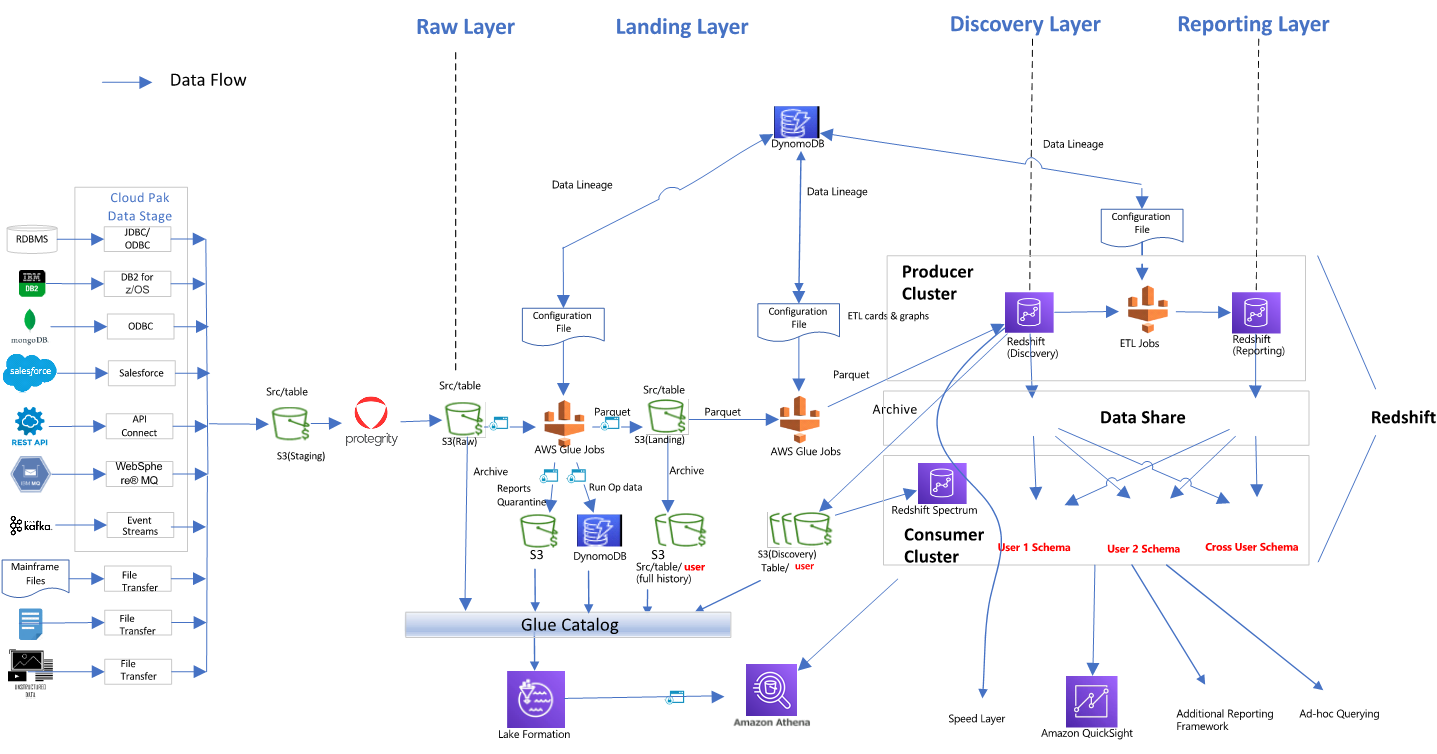
Figure 4 – Simplify workload isolation and chargeability using Redshift data sharing.
The architecture detailed above depicts an end-to-end data pipeline to ingest data from multiple sources and stage, process, and load to a producer ETL Redshift cluster. Data can then be shared with multiple isolated business intelligence (BI) and analytics clusters in a hub-spoke architecture to provide read workload isolation and optional chargeback for costs.
Each consumer cluster can be sized according to its price performance requirements and new workloads can be onboarded easily.
Expanding on Data Sharing Use Cases
With AWS Data Exchange for Amazon Redshift, providers can share access to live, production-ready Redshift tables, with pricing terms and conditions. Providers update their data directly at the source, without having to run ETL jobs or generate new files.
Subscribers can easily stream “live data” from AWS Data Exchange powered Amazon Redshift into AWS-native and non-native services. Subscribers can query datasets provisioned through Redshift across regions, eliminating data pipelines and duplication. Subscribers can also search and request new data sets for provisioning through Redshift.
We can expand sample use case #1 for the retail company to subscribe to Foursquare’s integrated Places (POI) database, accessible as a Redshift data share. The company can use the subscribed location data to perform additional analytics to optimize marketing campaigns, personalization, and improve channel strategy.
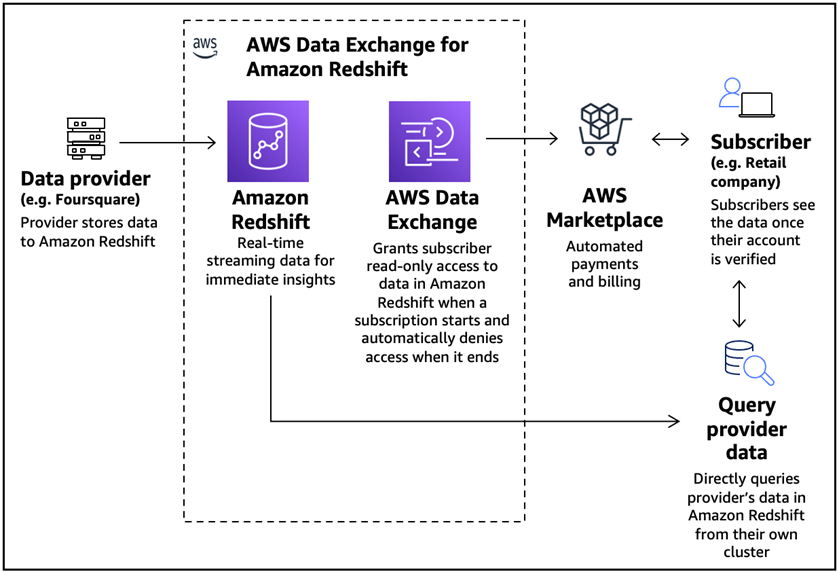
Figure 5 – AWS Data Exchange for Amazon Redshift for marketing optimization.
Depending on specific use case requirements, you can share data from an Amazon Redshift-provisioned cluster to serverless endpoint, and vice versa within the same or in different accounts or in different regions. You can also share data across Redshift serverless endpoints in different AWS accounts or in different regions.
Another great use case for AWS Data Exchange for Amazon Redshift is to build an industry-specific global data ecosystem. Leading players across industries are joining hands to form an open network to create a data ecosystem that’s openly accessible and editable, and shared by anyone.
Such platforms provide the layers and tools to liberate their data and accelerate workflows. With fine-tuned control over business processes, this approach helps reduce silos and gain access to data, creating opportunities for new field discoveries and automation of workloads.
Establishing a collaborative data ecosystem offers scalable solutions to top industry issues, optimizes global value chain, and accelerates innovation. However, flow of data across the entire value chain requires new collaboration models and effortless data exchange between the players. AWS Data Exchange for Amazon Redshift helps reduce friction associated with data onboarding and consumption.
AWS Data Exchange for Amazon Redshift makes it convenient to license access to your Redshift data through AWS Data Exchange. Providers can license data at granular levels and consumers can easily discover and subscribe to data that suits their business needs by browsing the Data Exchange catalog. With its unique capabilities, AWS Data Exchange for Amazon Redshift helps promote data monetization in enterprises.
Implementing a Data Mesh Using Redshift Data Sharing
There a few important considerations when exploring Amazon Redshift data sharing:
- Instance types that support data sharing and regions where data sharing is supported.
- Data sharing across accounts or regions.
- Performance of the queries on shared data.
- Producer and consumer cluster encryption requirements for cross-account and cross-region data sharing use cases.
- Data sharing when clusters are being resized or paused.
- Data sharing when clusters are deleted and restored.
Galvatron Data Migration Suite
Galvatron Data Migration Suite is a joint effort between AWS and Accenture to build, automate, and optimize data migrations to AWS by creating a unique set of offerings that enable clients to realize up to 30% reduction in cost and 2X faster data migrations to the cloud.
It provides integrated solutions and offerings for data lake, database, and data warehouse migrations backed by mature data engineering, accelerators, and governance practices to realize value faster. The pathways cover re-host, re-platform, re-factor, re-architect and retire from the aforementioned workloads to relevant AWS services as shown below.
Galvatron Data Migration Suite has well-defined pathways and related assets to migrate from multiple on-premises data warehouses to Amazon Redshift.
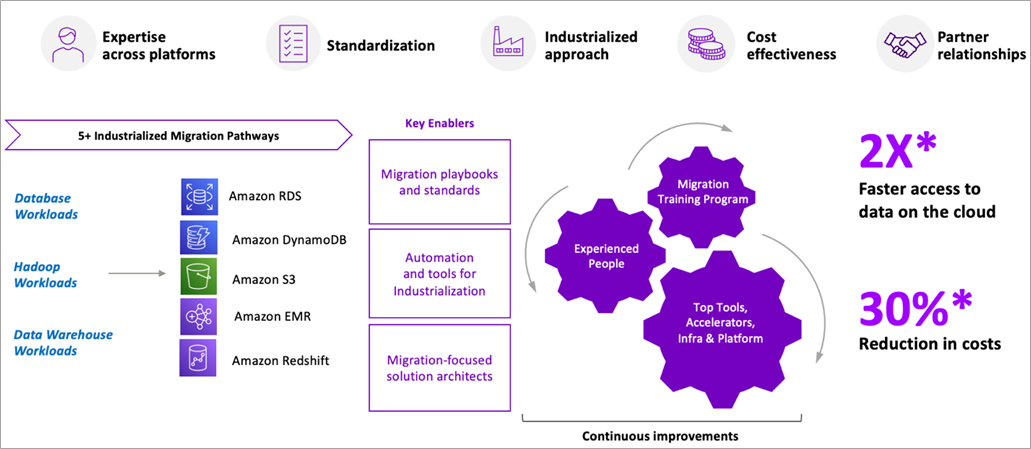
Figure 6 – Galvatron Data Migration Suite accelerate data migrations to AWS.
Galvatron Data Migration Suite offers an accelerated pathway for enterprises to migrate on-premises data warehouses to AWS. Once the data warehouses are migrated to AWS, the Amazon Redshift capabilities discussed in this post can be implemented to promote data sharing within and across organizational boundaries.
Conclusion
Amazon Redshift helps organizations break through data silos and gain real-time and predictive insights on their data in just a few clicks, with no data movement or data transformation.
In this post, we shared how various Redshift features help to implement a decentralized domain-driven architecture and simplify data sharing within and across organizational boundaries. We also discussed several architectural patterns involving Redshift that promote domain ownership, self-serve data platform, and federated governance.
Additionally, the assets available as part of Accenture’s Galvatron Data Migration Suite help accelerate migration and modernization of data warehouses on AWS.
We encourage you to review Amazon Redshift capabilities to further simplify data exchange within and across your organization. Engage Accenture to accelerate your data-led transformation journey to the cloud.
.
 .
.
Accenture – AWS Partner Spotlight
Accenture is an AWS Premier Consulting Partner and MSP. A global professional services company that provides end-to-end solutions to migrate to and manage operations on AWS, Accenture’s staff of 569,000+ people include more than 20,000 AWS-trained technologists with more than 12,000 AWS certifications.