AWS Partner Network (APN) Blog
Accelerating Machine Learning with Qubole and Amazon SageMaker Integration
By Chaitanya Hazarey, Machine Learning Specialist PSA at AWS
By José Villacís, Sr. Director, Product Marketing at Qubole
By Jorge Villamariona, Sr. Technical Marketing Engineer at Qubole
 |
Data scientists creating enterprise machine learning (ML) models to process large volumes of data spend a significant portion of their time managing the infrastructure required to process the data, rather than exploring the data and building ML models.
You can reduce this overhead by running Qubole data processing tools and Amazon SageMaker.
An open data lake platform, Qubole is an AWS Partner Network (APN) Advanced Technology Partner with AWS Competencies in Machine Learning and Data & Analytics. It automates the administration and management of your resources on Amazon Web Services (AWS).
By using optimized versions of data processing and orchestration technologies like Apache Spark and Apache Airflow on Qubole, you can explore, clean, and prepare data in the format required by ML algorithms, and then use it to train ML models in Amazon SageMaker.
In this post, we will discuss how to use Apache Spark and Airflow on Qubole, explain the benefits of integrating them with Amazon SageMaker, and walk you through the steps to do it.
Qubole Helps You Deliver Value Faster and at Lower Cost
Qubole automates and optimizes many administrative and maintenance tasks, freeing data scientists from the complexity of managing the infrastructure required to run their workloads.
The Qubole platform delivers this through capabilities like workload-aware auto scaling, intelligent Spot management, automated cluster lifecycle management, and heterogeneous cluster configuration.
Qubole analyzes and learns from usage patterns through a combination of heuristics and machine learning. From those patterns, it provides insights and recommendations that improve performance, reduce cost, and increase the reliability of your big data workloads.
You can query the data through the web-based Workbench, build integrated products using the RESTful APIs, build applications with Qubole’s software developer kit (SDK), prepare and transform data, train ML models, and connect to third-party business intelligence (BI) tools through ODBC/JDBC connectors.
These capabilities allow data scientists to focus on other valuable tasks while delivering cost savings and cost avoidance.
About Running Apache Spark on Qubole
Apache Spark is a distributed data processing engine that has become a widely adopted framework for machine learning, stream data processing, complex analytics, and other big data projects.
Qubole has provided an optimized version of Spark as a managed service since 2014, and has contributed several major projects (SparkLens) and optimizations (RubiX) back to the open-source community.
Qubole combines the scalability, processing speed, and language flexibility of Spark with an enterprise-ready data platform built to handle petabyte scale data volumes. With Apache Spark on Qubole, you can use your interface of choice—Notebooks, web console, SDK, or API—to build applications using Scala, Java, Python, or R.
Qubole runs some of the largest and most efficient Spark clusters in the cloud, scaling from 10 to 1,000 nodes and back down in minutes.
About Apache Airflow on Qubole
Apache Airflow is an open-source tool to programmatically author, schedule, and monitor data workflows or pipelines. With Airflow, you can author workflows as directed acyclic graphs (DAGs) of tasks. A DAG is the set of tasks needed to complete a pipeline, organized to reflect their relationships and interdependencies.
Qubole provides an optimized version of Airflow as a managed service that’s easy to use and scale for data engineering needs. You can use Airflow to schedule and orchestrate data pipelines—the sequencing, coordination, scheduling, and management of complex data pipelines from diverse sources.
These data pipelines deliver datasets that are ready for consumption either by BI applications and/or data science ML models that support big data applications.
One-click start and stop eliminates the complexity of spinning up and managing Airflow clusters. Seamless integrations with Github and Amazon Simple Storage Service (Amazon S3) ensure your data pipeline runs as smoothly as possible.
You can also use Airflow for model training. It gives you better control of training task execution, including monitoring and restarting model training tasks, as well as pinpointing when and where a retraining task failed.
Because Apache Airflow workflows are defined as code (see the procedure below), they become easier to maintain, version-control, test, and integrate with. Qubole-contributed features such as the Airflow QuboleOperator API, give you the ability to submit workflow instructions as commands to Qubole.
Learn more about Qubole’s implementation of Apache Airflow.
Two Approaches for Integrating Qubole and Amazon SageMaker
You can take two different approaches to integrate Qubole with Amazon SageMaker; both are described below.
Approach A: Prepare and initiate training from Qubole
This approach prepares data and initiates ML model training from Qubole, as shown in Figure 1. Qubole loads data from multiple data sources, including transactional databases, data warehouses, streaming data, interaction data like clickstreams, social media feeds, sensor data, log files, and more.
You can read your data into Apache Spark on Qubole data frames, and use Qubole Jupyter Notebooks to transform, cleanse, and prepare the data.
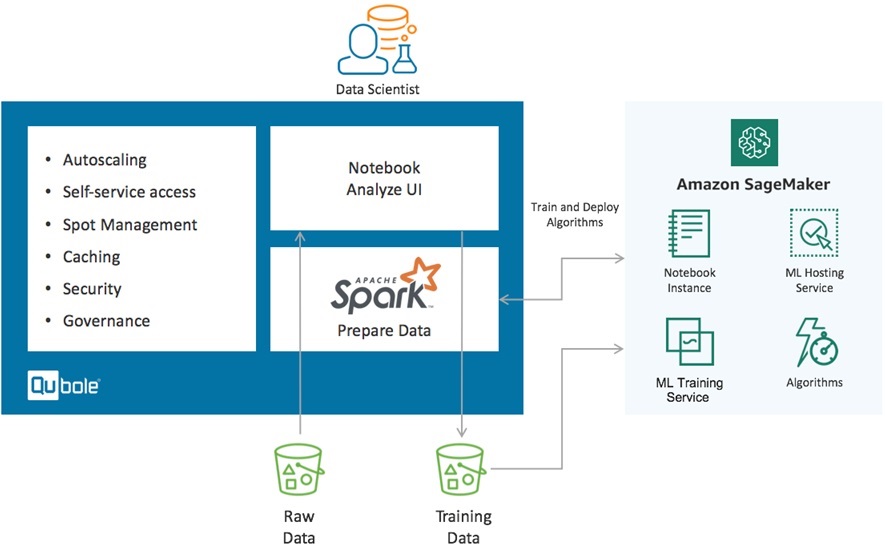
Figure 1 – Initiating ML model training from Qubole.
Once the data is stored back on Amazon S3, you can initiate model training from Qubole using the estimator in the Amazon SageMaker Spark library. Doing this initiates ML training in Amazon SageMaker, builds the model, and creates the endpoint to host that model.
Approach B: Connect an Amazon SageMaker Notebook instance to Qubole
Alternatively, you can enhance the Amazon SageMaker data processing capabilities by connecting an Amazon SageMaker Notebook instance to Qubole, as shown in Figure 2. You would use Qubole to cleanse and prepare the data (transform, featurize, join) prior to ML training in Amazon SageMaker.
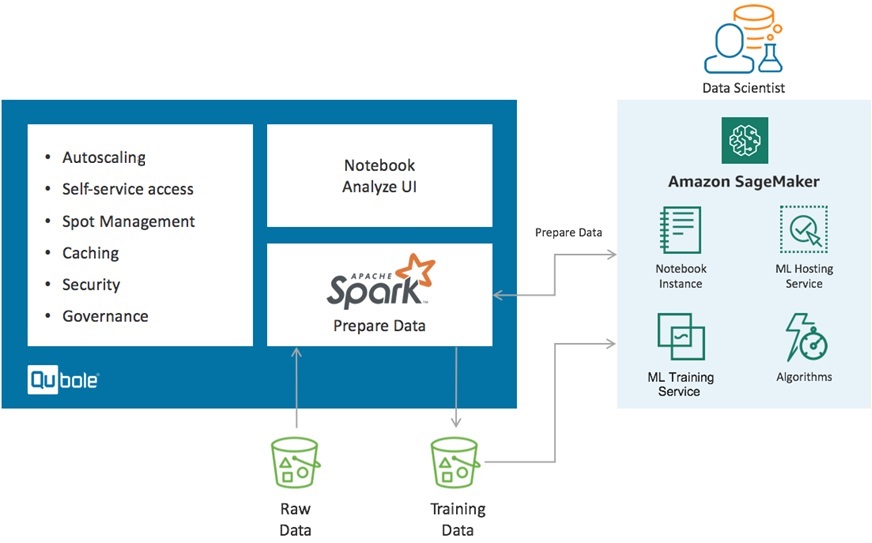
Figure 2 – Initiating ML model training from Amazon SageMaker.
Steps to Integrate Qubole with Amazon SageMaker
The Qubole-Amazon SageMaker integration process has three major steps:
- Create and configure a Qubole account.
- Configure Qubole to work with Amazon SageMaker.
- Set up a ML DAG using Python.
Step 1: Create and configure a Qubole account
Follow the Qubole sign-up instructions.
Step 2: Configure Qubole to work with Amazon SageMaker
To get a live, hands-on walk through of the configuration, request a session with a Qubole solutions architect.
Alternatively, you can follow this self-guided example of Qubole working with Amazon SageMaker.
Step 3: Set up a Machine Learning DAG using Python
The graphical representation in Figure 3 shows the DAG you will create in Airflow on Qubole with the code shared later in this post.

Figure 3 – The DAG the code snippet creates.
As explained previously, a DAG (directed acyclic graph) is the set of tasks needed to complete a pipeline organized to reflect their relationships and interdependencies.
This is the Python code that creates the DAG shown in Figure 3:
Nauto Improves Data Scientist Productivity, Accelerates Product Development
Nauto is an artificial intelligence company improving the safety of commercial vehicle fleets today and the autonomous fleets of tomorrow.
Its intelligent driver safety system—combining dual-facing cameras, computer vision, and proprietary algorithms—assesses how drivers interact with their vehicle and the road ahead, to reduce distracted driving, prevent collisions and save lives.
Nauto uses Qubole and Amazon SageMaker to integrate its data, improve data scientist productivity, and accelerate product development. They can now prepare data and define a model in Qubole, and then automatically push it to Amazon SageMaker to train the model and make it available immediately.
Previously, Nauto’s engineers spent many hours in data cleanup, maintenance, and management, including manual spreadsheet-based data processing to tune algorithms. Qubole has largely automated these processes and cut the typical time to provide actionable insights from 1-2 weeks to 2-3 days.
“Qubole’s integration with Amazon SageMaker streamlines data processing and machine learning,” says Lei Pan, Director of Engineering, Cloud Infrastructure at Nauto. “The savings from Qubole makes our data engineering team much more productive. They moved away from doing routine maintenance and management work to focusing on serving our customers’ needs and road safety.”
Read the full Qubole-Nauto case study >>
Conclusion
Integrating Qubole with Amazon SageMaker frees data scientists from the administrative overhead of managing and orchestrating the compute and storage resources they need. It also improves their ability to build, train, and deploy machine learning models quickly and efficiently.
.

.
Qubole – APN Partner Spotlight
Qubole is an AWS Machine Learning Competency Partner that simplifies the provisioning, management, and scaling of big data analytics workloads leveraging data stored on AWS.
Contact Qubole | Solution Overview | AWS Marketplace
*Already worked with Qubole? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.