AWS Partner Network (APN) Blog
Complexities and Best Practices for AWS Lambda Logging
By Aaron Lieberman, Cloud Practice Manager and Architect – Big Compass
 |
| Big Compass |
 |
It’s easy to get excited about serverless because of its many benefits. It’s also easy to understand why technology like AWS Lambda is the logical next step in microservices architecture and use. It makes sense to use on-demand serverless architecture for a growing set of use cases in the marketplace.
Both API security and logging are crucial for long-term success in any system to avoid headaches down the road. An API security breach can often cost more than the solution to protect your APIs. Similarly, a system outage with no logging visibility can outweigh the cost of implementing logging best practices.
With an exciting technology like AWS Lambda, however, and a desire to move forward, API security and logging can get lost in the shuffle.
At Big Compass, an AWS Lambda Service Delivery Partner, we’ve talked at some length about the need for API security and how to mitigate the challenges associated with it. It’s time, now, to look at the other commonly overlooked facet of a mature system: logging in AWS Lambda.
Whether it’s the reason for our engagement or not, logging quickly appears as a need at nearly every client we work with. We have helped numerous clients with their logging use cases.
For instance, while assisting a client in breaking their monolithic application into many different microservices to enhance stability, the addition of standardized logging provided more visibility into their system and decreased support costs.
What’s important to note is how ubiquitous the need for logging is, and how often it’s set aside for other priorities. At the end of the day, ignoring or de-prioritizing logging will leave you with little to go on when problems arise, which can quickly make support costs the number one ongoing cost your organization incurs.
Serverless Logging Pain Points
The evolution of microservices, serverless, and APIs has given us a lot of positives. Simultaneously, it’s become more challenging to log as modern, distributed architectures have become more prevalent in the IT industry.
Monolithic applications are being broken out into tens or hundreds of microservices. Logging needs are the same as they were for a single application, but the number of functions and services has increased 10-100x.
Monolithic applications have inherent problems, but on a positive note it’s easy to log and operate them. Lambda functions increase the volume of logs by magnitudes. Plus, Lambda logs can happen at any time from anywhere, resulting in a high volume of concurrent logs coming in from various Lambda functions.
 |
Logging from many distributed microservices resembles boxes scattered about a warehouse that need to get organized to be shipped to a destination.
On the other hand, monolithic application logging resembles an orderly assembly line of logs that are ready to be shipped from the conveyor belt to the destination.
Not only is there more to log, but microservices and serverless footprints expand rapidly. Because of this, logging pain points becomes amplified.
Instead of creating one nice assembly line of logs for a single, large application, organizations are faced with a need for visibility and traceability across tens or hundreds of Lambdas.
One common trap a business can fall into is replicating a logging framework to every Lambda in their AWS ecosystem. This causes extreme headache and maintenance issues when an update is needed in the logging code or a bug is found. The age old “don’t replicate your code” best practice applies here too. Read on to find out how to mitigate this common mistake.
The bottom line is that monolithic applications and microservices share the need for visibility, supportability, and traceability. But the distributed nature of AWS Lambda makes covering those needs a monumental challenge. Without logging, your organization faces problems being able to debug issues and increased support costs.
Below is a comparison of traditional logging architecture vs. serverless and microservices-based logging architecture.
Traditional Logging
As depicted in the diagram below, traditional logging from a monolithic application is simple. Logs all come from one location and get delivered to one location, which makes it a straightforward solution to implement.
For example, you can write logs to the Amazon Elastic Compute Cloud (Amazon EC2) disk, and then periodically ship them to Amazon OpenSearch Service.
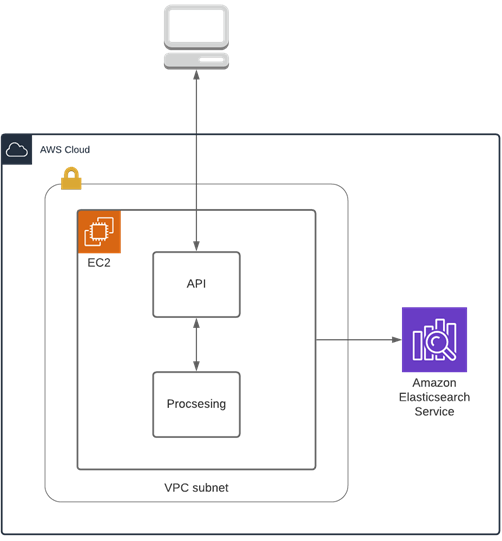
Figure 1 – Traditional logging architecture of a monolithic application deployed on EC2.
Serverless Logging
In the figure below, you can see how straightforward logging from a monolithic application can be when compared to the larger footprint of serverless AWS Lambdas. With Lambda and microservices, logs come from many different locations and need to be consolidated in one target logging location, like Elasticsearch.
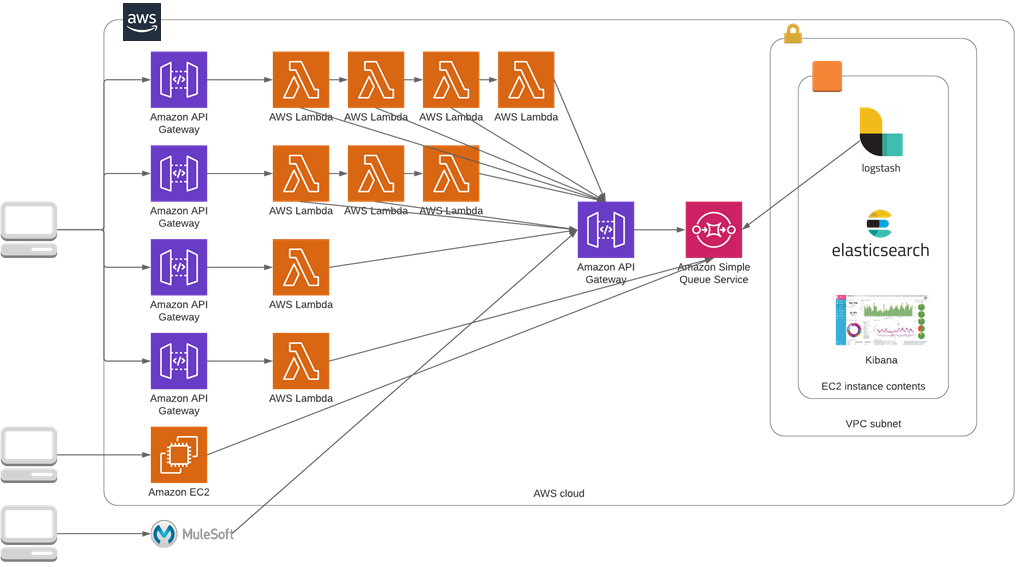
Figure 2 – Modern logging architecture using microservices.
Enforcing AWS Lambda Logging Standards
In our blog post on the topic, several logging best practices are defined. Yet, logging best practices are easier said and taught than enforced. And enforcement, unfortunately, is a key element for logging success.
Enforcement means going beyond just understanding best practices to defining which you’ll use and how you’ll use them, implementing them, and then enforcing them consistently across all of the teams building out serverless microservices.
If you’re relying on developers to implement Lambda logs without structure or guidance, you’re setting yourself up for problems down the road. For instance, Developer A implements their logs in plain text to go to Amazon CloudWatch, like this: console.log(‘Developer A logs A’);
Without defined standards, however, Developer B decides to use a JSON log:
Neither approach is wrong, but the problem is that when you consolidate these logs in CloudWatch, all of the logs look different. This decreases visibility and traceability of your system.
Logging standards need to be defined and enforced from early on for all of teams developing on AWS Lambda whenever possible. If you’re already well into using serverless, remember the best time to start enforcing logging was when you began using Lambdas. The second best time is now.
Options for Enforcing Logging Best Practices
The recommended approach is to create an AWS Lambda Layer, a decoupled dependency you can include in all of your Lambda functions, for reusable logging across your entire Lambda footprint. This allows you to use consistent logging across your serverless implementations by installing a simple Lambda Layer dependency that contains your logging logic.
This best part about this approach is this single Lambda Layer can be maintained and versioned separately from your code. It can be treated as your logging framework, allowing you to implement your business logic in Lambda completely separate from your logging framework.
When implemented in a Lambda Layer, the logging framework can be enhanced and deployed without impact to your applications.
You can use one of two logging solutions within your Lambda Layer.
Out-of-the-Box Solutions
Many out-of-the-box solutions can be used for your Lambda logging, and these solutions span a variety of coding languages.
A few of the ones we recommend include:
If a pre-built solution meets your needs, use it! There’s no reason to re-invent the wheel, and it will save you the time and headache of developing and maintaining your own solution. If an existing framework is close to what you need, you might consider forking that solution on GitHub and creating your own version.
Create Your Own Solution or Methodology
Maybe you’re not using NodeJS or Java. Or perhaps you have specialized needs that existing logging solutions can’t meet. If that’s the case, it’s probably time to consider building your own solution.
Using the basic principles of the existing solutions, you could develop your own framework in your chosen language. From there, your framework can be installed as a dependency as a Lambda layer, similar to the above solution.
Incorporating and Enforcing Logging in Your Process
Whichever path you decide to take, you’ll need to incorporate your AWS Lambda logging standards into your SDLC. The alignment helps enforce its use and supports developers as they adopt the new logging standards.
Start with code reviews. Logging should be included as a checklist item in code review. This is a crucial first step and checkpoint for enforcement.
These standards should also be incorporated into your DevOps and CI/CD process. This, too, will help with adherence and enforcement.
Ideally, you’ll manage your logging framework separately from your business logic, as we’ve recommended in a Lambda Layer. That way, you can manage the SDLC of your logging framework on its own and let your Lambdas and their associated business logic be managed on their own.
Conclusion
Make no mistake, logging from distributed AWS Lambdas and microservices is tough and nuanced. You’re taking many different functions and pumping those logs into a centralized system, planning for the aggregated logs to all line up.
This is yet another area in stark contrast between monolithic applications and microservices. Monolithic apps lean on the organization and process of an assembly line. Each part is placed precisely down the line.
Logging from AWS Lambda is more like an artistic, creative process. Elements that make up the log come from any number of sources. It requires thought and vision to bring together the pieces and assemble them into something organized and functional.
With proper planning, and by following the best practices in this post, you can make your Lambda logs a work of art that gives you a successful logging strategy. Using AWS Lambda Layers, you’ll have a logging implementation that creates an excellent experience for your application users while minimizing your organization’s costs and issues.
To start with an easy-to-use logging framework that can be installed in a Lambda Layer and help you enforce all of the logging best practices we have discussed, check out the Big Compass Serverless Logging Framework. This makes logging simple, easy, and effective for developers so developers can focus on development instead of spending valuable time on the intricacies of logging.
The Big Compass Serverless Logging Framework is also a validated AWS solution. The GitHub README will take you through easy steps to install the framework as a dependency in your applications.
This will help standardize logs across teams, business units, and AWS Lambdas, and ultimately ease the burden of implementing a complicated logging framework.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
Big Compass – AWS Partner Spotlight
Big Compass is an AWS Select Consulting Partner with the AWS Lambda service delivery designation that delivers integration as a competitive advantage.