AWS Partner Network (APN) Blog
Enabling Data Trust with Collibra Data Intelligence Cloud on AWS
By Dilip Rajan, Sr. Partner Solutions Architect – AWS
By Koen Van Duyse, VP, Partner Success – Collibra
 |
| Collibra |
 |
The frequently heard phrase that “data is the new oil” means data can unlock revenue opportunities for organizations in different ways. Data in any format is valuable as long as you know how to use it effectively; however, such data monetization is only possible if you also trust your data.
In today’s fast-paced world, where data is rapidly produced, stored, and consumed, many organizations struggle to organize, find, and utilize their data skillfully and successfully.
To help organizations effectively manage their data, Collibra delivers an end-to-end, integrated platform that’s purpose built to automate data flows and provide trusted insights based on data governance principles.
Collibra’s Data Intelligence Cloud includes products such as:
- Data Governance helps enterprises understand and find meaning in their data.
- Data Catalogs empowers business users to drive value by quickly discovering and understanding their data.
- Data Lineage provides complete transparency into data by mapping relationships to show how data flows from system to system and how data sets are built, aggregated, sourced, and used.
Collibra’s data lineage, access control, and data cataloging capabilities powered by Amazon Web Services (AWS) are a valuable asset in terms of analyst productivity for data discovery and research.
In this post, we’ll explain how Collibra integrates with AWS services and provide a sample workflow on how to register an AWS Glue metadata catalog in Collibra for building a business catalog. Collibra is an AWS Competency Partner that gives teams powerful tools that make it easy to consume data across the enterprise.
Architecture
To start, let’s look at how Collibra works. As shown in Figure 1, Collibra’s Data Intelligence Cloud accesses an “edge site” compute environment in a customer’s Amazon Virtual Private Cloud (Amazon VPC) or on-premises data center to process information and return only the results of this processing back to the platform.
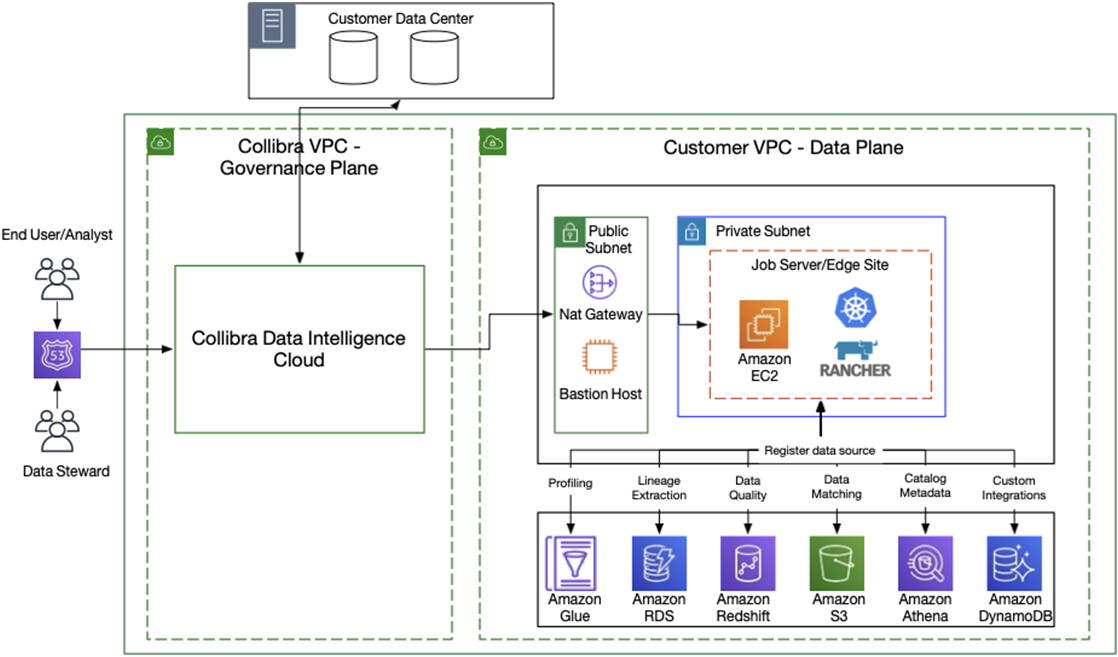
Figure 1 – Collibra Data Intelligence Cloud reference architecture.
The latest edge site from Collibra is a compute runtime that’s also installed as a separate component, for accessing and processing data close to where the data resides. This component has benefits that include the ability to tackle specific use cases on top of customers’ data along with the resource management, parallel execution, and information preprocessing.
We’ll walk you through the key benefits of the edge site in this post, and look at why to consider using this new paradigm for your deployment option.
Edge Site
Below, Figure 2 outlines the benefits of this edge site approach, including:
- Enhanced data security.
- Lays a foundation to support more scalable capabilities.
- Improved ingestion and profiling performance.
- No manual updates, as edge updates are included in Collibra Data Intelligence Cloud releases.

Figure 2 – Benefits of the Collibra edge site.
The edge site is based on a distributed runtime (Kubernetes), allowing the compute environment to scale out with high availability and built-in resource management. Collibra also provides a software development kit (SDK) for adding new capabilities and is portable to a hybrid environment on AWS and on-premises.
The edge site also includes a data-processing operation as a scheduled job around a common use case, such as metadata ingestion or technical lineage extraction from a standard data source type.
This component typically creates an edge connection that identifies a customer data source, such as a database, file share, or REST service. For example, using Java Database Connectivity (JDBC), the edge site offers a connectivity from its user interface, and capabilities don’t have to resolve different ways to authenticate to a JDBC source.
The edge site feature went live in May 2021 with Kubernetes management provided by Rancher, with plans to provide native integrations with Amazon Elastic Kubernetes Service (Amazon EKS) in upcoming releases.
Additionally, support for Amazon Simple Storage Service (Amazon S3) will be coming soon. Therefore, migration from job server to edge site at this point should weigh the current feature set against what will be released in the upcoming months.
With full JDBC support, job server features correspond to multiple edge capabilities, with each capability developed and deployed independently. There will also be a script for migrating from job server to edge as applicable.
Edge Site Deployment
Installing the edge site is fairly straightforward and is recommended to be deployed on a Red Hat Enterprise Linux (RHEL) 7 on Amazon Elastic Compute Cloud (Amazon EC2) virtual machine with 64 GB to 512 GB of RAM. M5.4xlarge is good fit for the edge site with a blend of price and performance.
Once you have obtained the Collibra Data Intelligence Cloud-based license keys from Collibra sales and support via Zendesk, please follow the instructions outlined in the edge installation Collibra page.
Once the edge site has been installed, Secure Shell (SSH) into the virtual machine to ensure the edge site is healthy using the following command:
sudo /usr/local/bin/kubectl get pods –all-namespaces
Now that we’ve discussed the benefits of the edge component, let’s go through the process of setting up a catalog from Amazon S3.
Amazon S3 Metadata Ingestion
Suppose you want to set up a connection between the Collibra Data Catalog and AWS. You can start this process by importing metadata from Amazon S3 with the registration of the S3 filesystem in Collibra Catalog.
This is done by creating a new connection in the catalog and then choosing the Register System option with Collibra’s Data Governance.
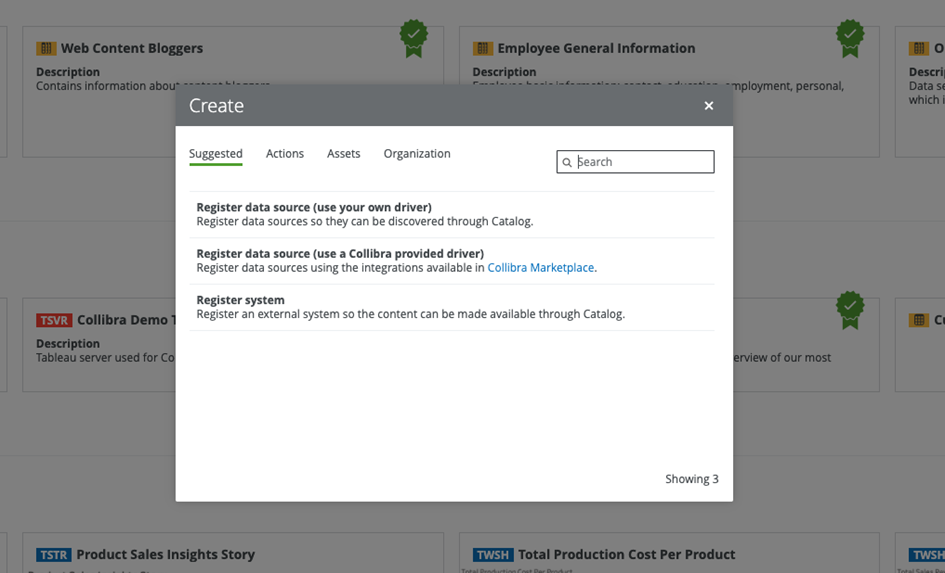
Figure 3 – Create a new connection.
Next, choose Amazon S3.
Once in the Register system tab, provide the Community name into which the S3 file system is registered along with the File system name. This can be any name that can be used to identify the asset in the catalog.

Figure 4 – Provide file system name.
The next step is to provide the connection details for the S3 connection. These details include the AWS key ID (the access key ID of the programmatic AWS user), Secret access key (the secret access key of the programmatic AWS user), and the IAM role (the IAM role to be assigned to the crawlers that will created in AWS).
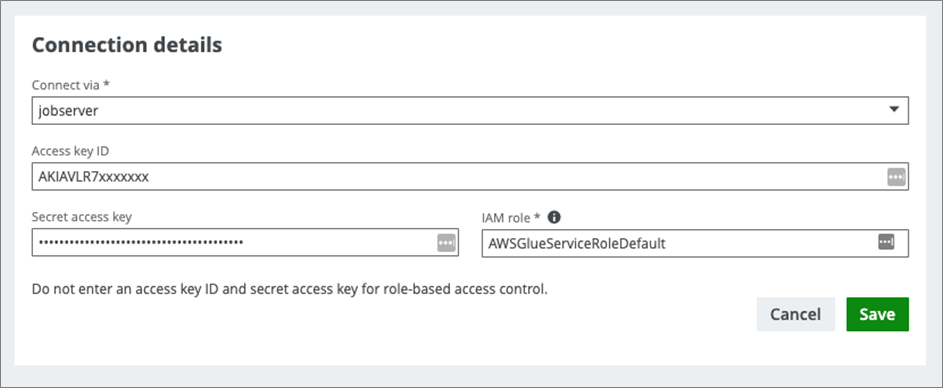
Figure 5 – Connection details.
After providing the connection details, you can now define the AWS Glue crawlers that will be created on behalf of the IAM user in AWS. The crawlers profile data that’s in the folder specified in the Include path. Certain files can also be omitted by the crawler by using the Exclude patterns option.
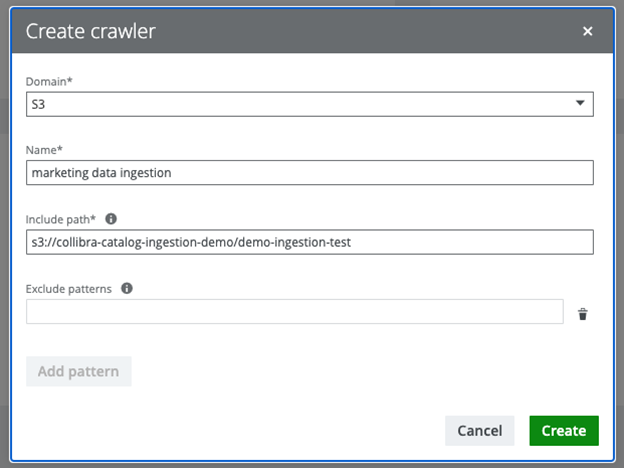
Figure 6 – Define crawlers.
After the crawler definition is complete, you can select Synchronize Now to start the metadata ingestion from the Glue catalog.
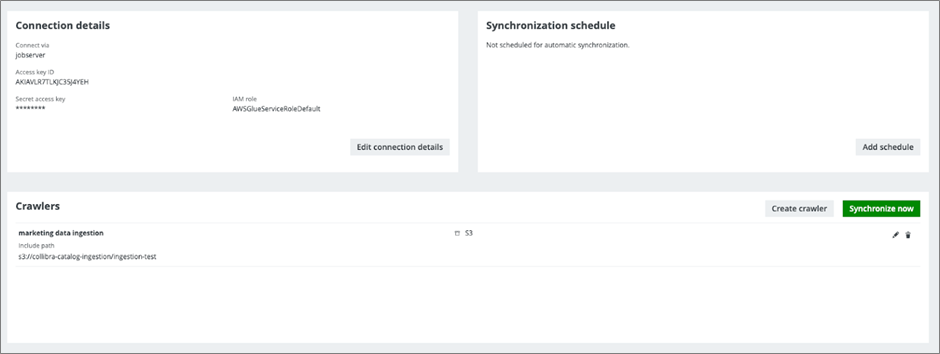
Figure 7 – Start synchronization.
The synchronization job will be shown running under Activities.
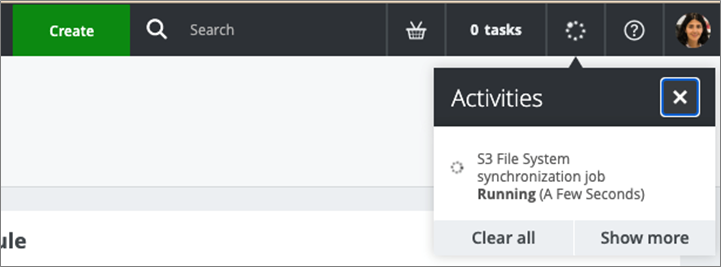
Figure 8 – Synchronization job running.
Once the synchronization is complete, you can view the ingested metadata in the Catalog, which lists the S3 bucket and the underlying folders and files, and the Columns, which represent the fields in the respective files.
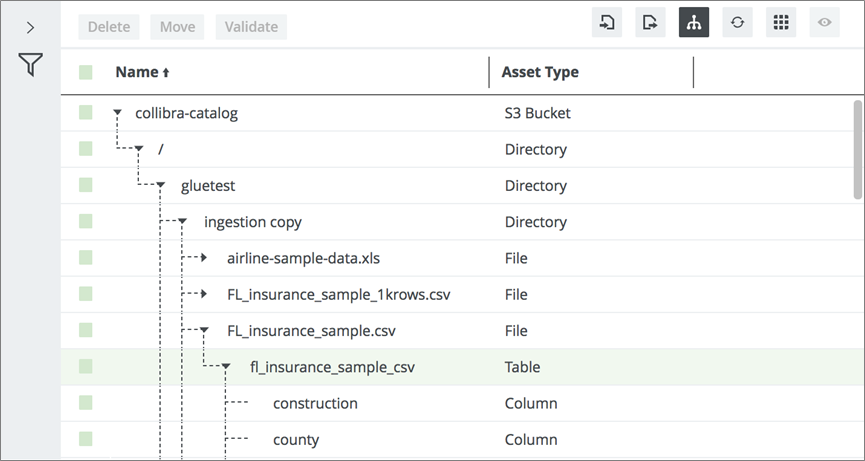
Figure 9 – View ingested metadata.
The above process for importing metadata from Amazon S3 was fairly straightforward; however, where Collibra really shines is in its range of AWS, hybrid, and multi-cloud data source connectors.
Collibra’s ecosystem of connectors includes:
- Collibra-provided drivers: This option includes support for AWS Glue, Amazon Athena, Amazon DynamoDB, Snowflake, MongoDB, and more.
- Use your own driver: This option requires setup of the JDBC driver of your source. Check out the various paid and vendor-supported drivers on Collibra Marketplace.
For a detailed list of all connectors, visit the Collibra community page.
Conclusion
In this post, we showed you how to set up a connection between the Collibra Data Catalog and AWS to import metadata from Amazon S3. With Collibra, organizations can easily catalog S3 data so that business analysts can find, understand, access, and trust their data.
More specifically, the Collibra Data Catalog helps add the necessary business context to the data in the AWS Glue catalog so analysts can effectively and efficiently use this data to make business decisions.
Collibra is looking to build broader integration with the Glue catalog that brings in metadata beyond S3. Customers will then be able to augment information they already have in Collibra Data Catalog, and view business and technical metadata and lineage across all data sources in their organization.
This integration will ultimately expand the capabilities so organizations can make insightful and impactful data-driven decisions.
To learn more about the integration or Collibra, register on Collibra University and check out the AWS Marketplace listing for Collibra Data Intelligence Cloud.
.

.
Collibra – AWS Partner Spotlight
Collibra is an AWS Competency Partner that gives teams powerful tools that make it easy to consume data across the enterprise.
Contact Collibra | Partner Overview | AWS Marketplace
*Already worked with Collibra? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.