AWS Partner Network (APN) Blog
How Provectus and GoCheck Kids Built ML Infrastructure for Improved Usability During Vision Screening
By Rinat Gareev, ML Engineer at Provectus
 |
According to the MIT Sloan Management Review and BCG survey, 93 percent of executives worldwide expect to get some value from artificial intelligence (AI) and machine learning (ML). To do so, they need a secure and compliant machine learning infrastructure that involves ML, DevOps, and data engineering.
Such infrastructure is critical because vast amounts of experimentation is needed to make ML solutions work with high accuracy and efficiency.
It speeds deployment to production, accelerates feedback loops, and enables re-experimentation. It also allows data scientists and ML engineers to focus on understanding their data, building models, and moving them to production.
For businesses like GoCheck Kids, machine learning infrastructure is vital. The company has developed a next-generation, ML-driven pediatric vision screening platform that enables healthcare practitioners to screen for vision risks in children in a fast and easy way by utilizing GoCheck Kids’ smartphone app.
It’s critical for the company to ensure its solution is powered by highly accurate image classification models. This can reduce the number of eye screens sent for manual review, lower readmission rates, and increase satisfaction with the app.
GoCheck Kids teamed up with Provectus—an AWS Premier Consulting Partner with the AWS Machine Learning Competency—to build a secure, auditable, and reproducible ML infrastructure on Amazon Web Services (AWS).
The goal was to enable data scientists and ML engineers to run multiple experiments on a dataset of 150,000+ images, allowing them to compare and deploy highly accurate models.
The Project
The GoCheck Kids solution consists of a smartphone app to perform vision screening and a processing engine hosted on AWS.
To screen a child for vision disorders, a user snaps a photo of the child’s eyes at a fixed distance in a dim environment. The app evaluates the image in real-time to check if it’s acceptable for assessing vision risks, and then analyzes the image and provides a recommendation “Risk Factor Identified” or “No Risk Factor Identified.”
Otherwise, the application instructs the user to retake the image. Possible reasons for rejecting an image are: child not looking straight at the camera, exposure not adequate, motion blur, or extraneous light sources. If the app indicates “Risk Factor Identified,” the child is referred to an ophthalmologist.
For the application to work as intended, highly accurate image analysis and classification algorithms must be part of the platform’s processing engine.
GoCheck Kids’ original image processing algorithm (IPA) performed on par with competing vision screening technologies. It used OpenCV to identify such features in an eye image as limbus, pupil, corneal reflex, and crescent. IPA’s accuracy lagged behind when a child did not look directly into the camera. There were challenges related to the identification and measurement of specific features of the eye.
Because of that, a team of trained clinicians had to manually review a significant portion of images flagged as “Risk Factor Identified” to ensure better accuracy. Human reviewers were better at identifying gaze errors, recognizing noises caused by extraneous light sources and motion blurs, and at identifying eye features.
The team had to review more than 50,000 images per month, which was costly and inefficient in the long run. Inaccurate image processing caused readmissions, which added up to 20 percent of overhead cost while negatively impacting satisfaction with the application.
With this in mind, the goal of the GoCheck Kids team was to improve the accuracy of the application’s automated image analysis to match that of manual review.
By working closely with GoCheck Kids’ business stakeholders and domain experts, Provectus reviewed IPA and other models to identify the gap in performance was caused by two types of images:
- Images where the child was not looking straight into the camera.
- Images from children with strabismus (i.e. a child who cannot align both eyes simultaneously under normal conditions).
Detection of such images was framed as a classification problem. Thus, when given an input image with additional attributes, an ML model should be able to produce one of the predefined labels: (a) child is looking properly into the camera; (b) child is not looking properly into the camera; (c) child with strabismus.
Based on the label, the mobile application should either instruct the user to retake the photo, or pass it on for further processing.
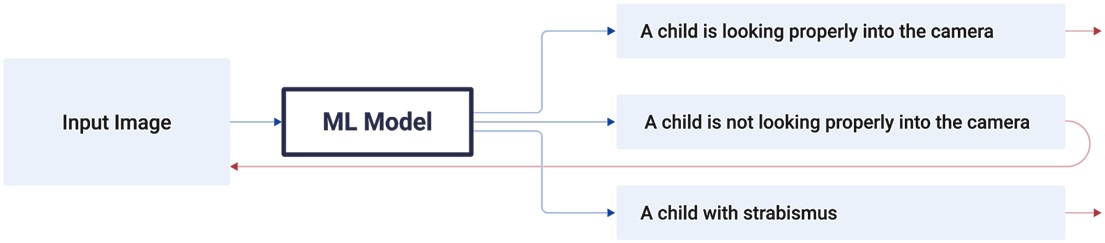
Figure 1 – Classification of input images by the ML model.
The Challenges
There are plenty of deep neural network architectures for image classification, and extensive experimentation is often needed to figure out which one is the best.
The model search space can also be expanded by the following variables:
- Input definition, including how images are represented, prepared, and fed into a model. Should they be grayscaled, resized, cropped, or split (one image per eye or one image with both eyes)?
- Feature generation backbone, such as ResNet, MobileNet, EfficientNet, and Inception.
- Specifics of how to combine image features with features from preliminary IPA steps (eye landmark coordinates).
- Multiple tweaks with loss functions.
- Transfer learning options where a model can be trained from scratch. A feature generation backbone that’s pre-trained on conventional datasets (ImageNet, for example) can be used, or it can be pre-trained on a synthetic dataset for the particular task.
- Combining different models.
All of these can be combined to run dozens of experiments. Bear in mind that GoCheck Kids’ final image analysis model must be deployable into a mobile device, and it must provide reasonable computational performance.
There are several challenges related to labelled data itself:
- Volume – There are about 150,000 images in the ground truth dataset of GoCheck Kids’ in-house annotation platform. Their pre-processing and model training might take several hours even on a powerful GPU instance.
.
Given the amount of experimentation, this necessitates a dedicated environment for compute-intensive jobs (model training, data pre-processing). It needs to allow the sharing of intermediate outputs between experiments to facilitate faster experimentation.
. - Data sensitivity – The use of medical data imposes additional security and privacy requirements on the team.
. - Ground truth labels – Given the evolving nature of the dataset, subjectivity of human reviewers on edge cases, and bias introduced by the existing IPA, it’s natural to assume there are a few errors that can affect model training and evaluation.
The project required DevOps expertise, processes, and technologies, and also automation of experiments and model building. A robust framework that would allow us to decouple these activities and enable collaboration between data scientists, data engineers, ML engineers, and DevOps was necessary.
The Solution
Such a framework must include three important constituents: ML infrastructure, pipelines, and models. In this post, we’ll cover the first two.
ML Infrastructure
Upon review of the project, Provectus and GoCheck Kids decided to proceed with an architecture of machine learning infrastructure that features AWS services and open source tools.
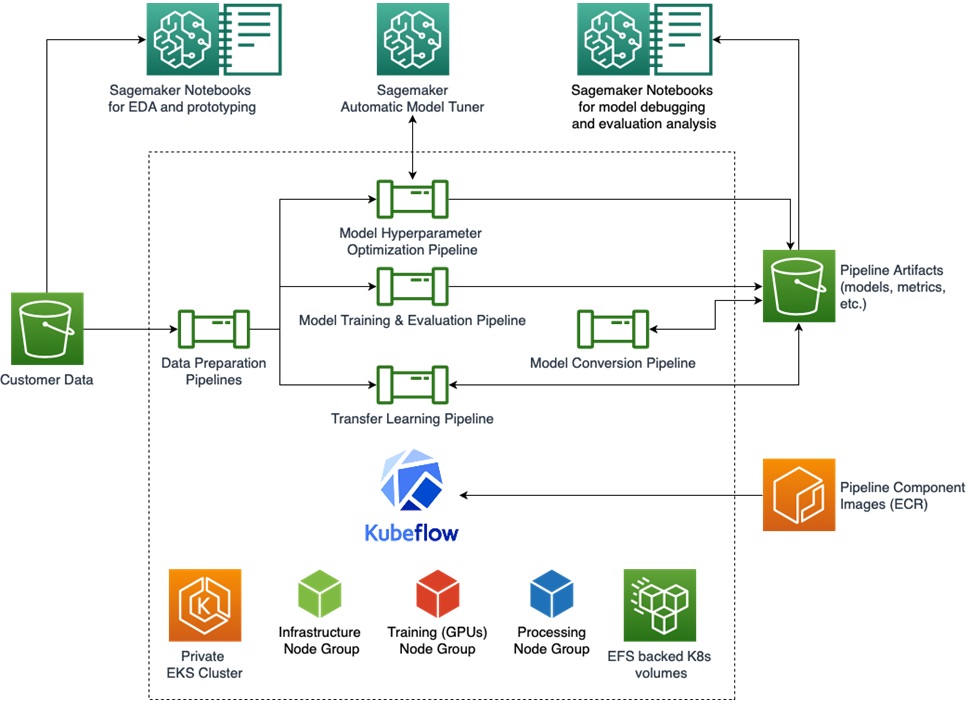
Figure 2 – Machine learning infrastructure designed and built for GoCheck Kids.
Computational instances are provisioned either in the Amazon Elastic Kubernetes Service (Amazon EKS) cluster, or by Amazon SageMaker jobs. If a pipeline doesn’t use Amazon SageMaker Automatic Model Tuner for training job management, it launches the jobs inside the cluster on top of the auto scalable GPU node group.
The Amazon EKS cluster is secured and is accessible from two bastion instances:
- Bastion instance with limited permissions to access Kubeflow services, including user interface (UI).
- Bastion instance for cluster administration.
Note that access to bastion instances is based on allowlists.
Kubeflow is deployed on top of the EKS cluster. An open-source, Kubernetes-based machine learning platform, Kubeflow Pipelines is used as an ML workflow orchestrator and as an experiment tracker.
The benefits of Kubeflow Pipelines use includes:
- Convenient DSL to describe pipeline steps and their connection to each other.
- Decoupling configurations of an execution flow and its underlying infrastructure
- Built-in instrumentation of individual steps, which allows to avoid boilerplate code.
Original datasets are stored in Amazon Simple Storage Service (Amazon S3). Their preprocessed versions also reside on S3, but several pipelines duplicate them on Kubernetes volumes, backed by Amazon Elastic File System (Amazon EFS), to ensure performance efficiency.
Note that as an alternative, you can use Amazon SageMaker Training Jobs with data sources backed by EFS or Amazon FSx for Lustre.
ML Engineer Environment
When ML engineers want to introduce a new pipeline component or debug an existing one, they don’t need to be overwhelmed by the variety of options brought by modern DevOps into the infrastructure.
For example, no matter what underlying data source implementation is used, in both Kubeflow Pipelines components and Amazon SageMaker Training or Processing Jobs, the component code can access it as an ordinary local filesystem. The chosen orchestrator ensures this by working behind the curtain.
The same principle applies for other aspects, such as GPU provisioning and access management. In Figure 3 below, development environment of an ML engineer is summarized.
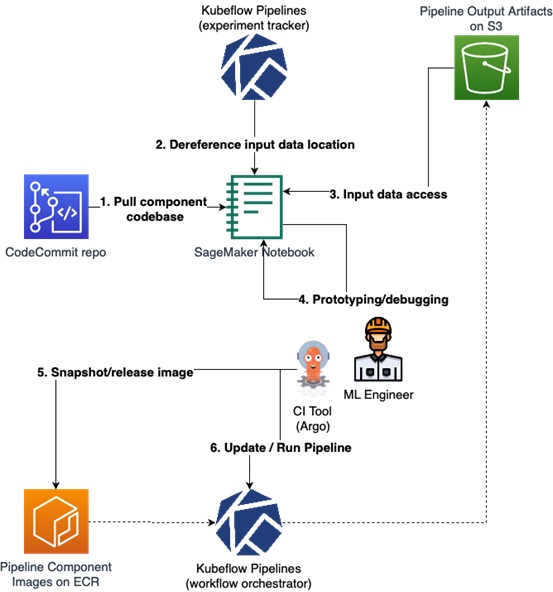
Figure 3 – Development environment of a regular ML engineer.
Faster Iterations on Model Building
Several model training pipelines are introduced to facilitate model building. They are decoupled from the data preprocessing pipeline, as the latter is changed and runs less frequently.
Training pipelines are designed with the following use cases in mind:
- ML engineer evaluates different hyperparameter configurations with other settings remaining the same.
- ML engineer evaluates a new model.
- ML engineer evaluates an existing model after improvements or bug fixing.
- ML engineer derives learning curve for a model by varying the size of the training set.
With a proper design, half of these use cases can be performed by running the pipeline with different parameters while the workflow orchestrator, Kubeflow Pipelines, with Amazon SageMaker, do the rest. They provision and configure resources, manage data flow between components, track logs, metrics, and other artifacts.
The effort required to evaluate changes in a model’s code is reduced by integrating continuous integration tools that operate Docker images of pipeline components.
The training pipeline components and its data flow are:
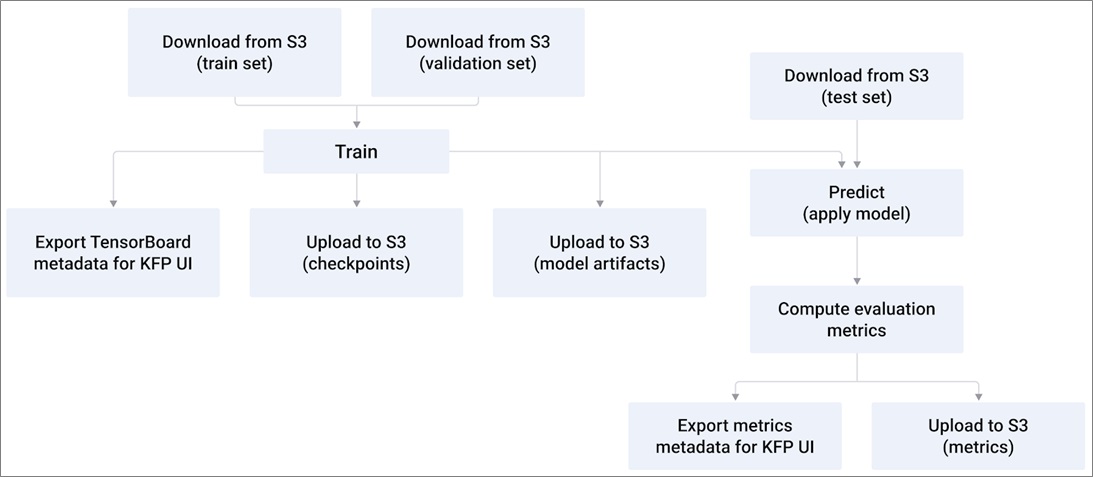
Figure 4 — Training pipelines and data flow for GoCheck Kids’ infrastructure.
Most of the components are not task-specific and can be reused across different ML projects, reducing the initial burden to establish pipelines. The recently released service Amazon SageMaker Components for Kubeflow Pipelines can also help with that.
Restoring a model in a separate environment allows you to implicitly test it for further deployment, which mitigates risks caused by dependencies mismatch and to get metric values that are reproducible. This approach is radically different from a single-messy-Jupyter-notebook approach.
Model Optimization
When a promising model is evaluated, the limits of its quality can be estimated using the techniques of hyperparameter optimization.
For GoCheck Kids, we implemented it using Amazon SageMaker Automatic Model Tuner. Its pipeline doesn’t differ much from the one illustrated above: “Train” is replaced by “Tune Hyperparameters.” They share the same contract: given training and validation set output a model.
This component uses the Amazon SageMaker SDK to create Hyperparameter Tuning Job, waits for its completion, and extracts the best model with its artifacts.
Continuous Predictions Analysis
In addition to pipeline orchestration, Kubeflow Pipelines acts as an experiment tracker—all pipeline runs will be tracked and enriched with metadata. This comes handy for several practical use cases.
Reproducibility
If you store code version (Git commit, Docker image) as a pipeline artifact or part of its definition, your input datasets are versioned and immutable. When combining this with metadata from the experiment tracker, you can reproduce results that you first got a while ago.
Learning Curve
All pipeline runs get unique identifiers, and they can be grouped logically using Experiments (a concept in the Kubeflow Pipelines). Kubeflow Pipelines provide an API to query run metadata and its outputs. You can use these to automate construction of a learning curve—get training and testing error metrics for different runs with the same model on the incrementally growing training set. The learning curve is a useful tool for model diagnostics.
Model Comparison
The same toolset can be utilized to compare different models on the same test set. Kubeflow Pipelines UI allows you to compare result metrics and artifact visualization side-by-side for chosen runs, but more sophisticated use cases can be implemented using run metadata. For example, when given two training run identifiers, you can implement a report-like notebook where differences in predictions are highlighted.
Data Curation
The experiment tracking allowed us to automate data relabeling workflow. Since careful reviewing of the entire dataset was not feasible, the following candidate selection schema was implemented.
Five different train/validation/test dataset splits were introduced, where test parts from different splits covered the entirety of the dataset. Then, various good quality models were trained and tested on all splits. By running the images stored in the test sets through a combination of several models, the incorrect labels were identified and selected as candidates for relabeling.
Here, we made an assumption that these “hard to deal with” images may contain labelling errors. That was mostly confirmed after manual review by GoCheck Kids’ clinicians. The ML models actually delivered correct predictions, which led to the boost in evaluation metrics.
Without an experiment tracker, this process would be more error-prone and time consuming, since you have to deal with at least (number of data splits) x (number of models) experiments altogether.
Model Deployment
Another additional pipeline was designed to deal with model preparation for deployment on iOS devices. It operates in two steps.
- First, it converts an original TensorFlow Model into TensorFlow Lite form that can be used with the TensorFlow Lite interpreter for inference inside the Swift / Objective-C app.
. - Second, it performs some sanity checks to find out if a resulting model combined with its preprocessing works as expected after the conversion. For many target architectures, including mobile or edge devices, this pipeline can also include SageMaker Neo Compiler.
ML Infrastructure Foundation
The Provectus Machine Learning Infrastructure was used as a robust foundation for GoCheck Kids’ infrastructure and pipelines. It comes in with all must-have elements to kick off an AI solution, including feature store with data versioning and lineage features, reproducible ML pipelines, model versioning, model monitoring, and concept drift detection. The infrastructure is FDA- and SOC2-compliant.

Figure 5 — The ins and outs of Provectus ML Infrastructure.
The Machine Learning Infrastructure enabled Provectus to apply MLOps automation to the ML workflow, achieve enterprise readiness and compliance of ML models, and establish reproducible and scalable ML processes much faster and cost-efficiently.
Conclusion
Designing and building a secure, auditable, and reproducible machine learning infrastructure takes time and effort. Yet, it’s a must-have for small ML shops and enterprises, to accelerate time to value for their AI initiatives and increase trust from the business.
It eliminates hand-off between data scientists and ML engineers, gives them more time to handle data, build ML models, and deploy them to production, and also minimizes technical debt in ML projects.
Through close collaboration with Provectus, GoCheck Kids has received an advanced infrastructure for machine learning on AWS, which features a robust environment for experimentation with experiment tracking and model versioning. The infrastructure is secure and FDA compliant.
By using the infrastructure, three ML engineers were able to conduct over 100 large-scale experiments in less than three weeks, test various improvement hypotheses, and re-run quality hypotheses to determine the best hyperparameters.
More efficient data preparation and faster ML experimentation enabled Provectus to train and tune multiple ML models and select those with the best precision and recall. While GoCheck Kids’ original IPA correctly caught “Child Not Looking” cases with recall of ~25 percent (at 50 percent precision), Provectus’ new model increased the recall to 91 percent, while preserving the initial model’s precision.
For GoCheck Kids, more accurate image analysis in their application means fewer readmissions and less manual review. This translates into cost savings and increased customer satisfaction. From a technology perspective, it also ensures a consistent standard of quality, reliability, and agility of its processes.
Explore the capabilities and features of Machine Learning Infrastructure, designed and built by Provectus, and learn more about our exclusive ML Infrastructure Acceleration Program for businesses looking to embark on the AI journey.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
Provectus – AWS Partner Spotlight
Provectus is an AWS Premier Consulting Partner that helps companies in healthcare and life sciences, retail and CPG, media and entertainment, and manufacturing achieve their objectives through AI.
Contact Provectus | Partner Overview
*Already worked with Provectus? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.