AWS Partner Network (APN) Blog
How to Improve Customer Performance with an Amazon EC2 Instance Upgrade
 |
 |
By Rob Janney, Technical Architect at WP Engine
At WP Engine, we’re constantly looking for new ways to improve our platform and offer additional value to customers. We do this in a variety of ways, from helping people migrate to WordPress for the first time, all the way to assisting seasoned web developers with mission-critical challenges.
Last year, when some of our customers who had invested in high availability infrastructure began looking for even faster speed and response times, our engineers undertook the rather extensive task of upgrading our Amazon Elastic Compute Cloud (Amazon EC2) instances from fourth-generation M4 and C4 instances to the most recent M5 and C5 instances.
In doing so, we replaced thousands of traffic-serving instances, and thanks to the new hypervisors provided in M5 and C5 instances, we significantly reduced network latency.
WP Engine is an AWS Partner Network (APN) Advanced Technology Partner with the AWS Digital Customer Experience Competency. Our WordPress digital experience platform gives enterprises and agencies the agility, performance, intelligence, and integrations they need to drive their business forward faster.
In this post, I will describe how we automated our M5 and C5 instance upgrade process to get the most of our Amazon Web Services (AWS) environment.
Getting Started
To begin this process, we identified WP Engine customers who were still using the outdated instances and got to work writing automation to help us incrementally replace each one. We wanted to do this while verifying success every step of the way, without creating downtime or significant performance impacts to our platform.
WP Engine offers highly available WordPress clusters that span multiple Availability Zones (AZs) within a single AWS Region. Each tier of the stack involves Amazon EC2 instances across multiple AZs to ensure the cluster maintains availability in the event of a single node or AZ failure.
Using AWS tools such as the AWS Software Developer Kit for Python (Boto3), Auto Scaling Groups, and Amazon CloudFormation, we were able to write automation that let us transition a single node per customer cluster at a time, while simultaneously doing it for many clusters within a single region.
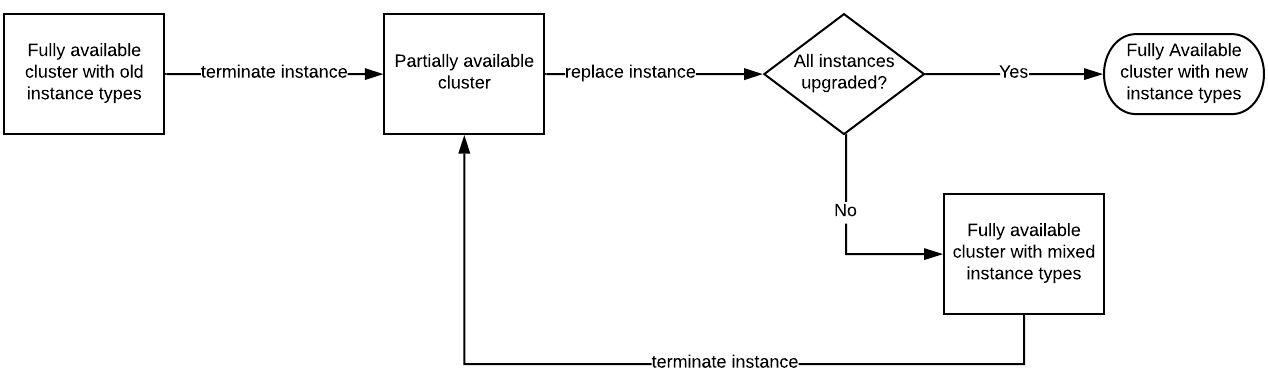
Figure 1 – A single cluster diagram.
The diagram in Figure 1 shows the step-by-step upgrade process from the view of a single WordPress cluster. Starting from the cluster running old instances, we transitioned by terminating one at a time. The Auto Scaling Group automatically replaced instances with the new instance type.
Note that this is a linear process, and you can explore Figure 3 later in this post to learn how the overall flow ensures greater throughput via parallelization.
Hitting Go
We created constraints that helped our program decide which nodes to replace, and we automated it so that it would keep replacing nodes as fast as possible, while only replacing a certain amount at a time (typically 20). We also made sure the program wouldn’t replace more than one node at a time in a particular environment, until the previous node successfully completed the upgrade.
We set these limits to ensure that if we ran into an issue, we’d be able to limit the scope of any problems that might result. We also insisted on keeping our program focused on one node per environment to ensure we maintained high availability for each cluster. In addition to those limits, we stipulated that if an environment didn’t become healthy again, within a configured amount of time, it would escalate via monitoring.
After we hit go, we quickly upgraded the first target group of customers, but we exposed a previously undiscovered corner case with our Elastic Load Balancing (ELB) health check that resulted in a brief hiccup for a small volume of traffic. We were able to improve the health check and incorporate additional validation to our upgrade process to ensure that all further upgrades went off without a hitch.
Here’s a look at three functions (simplified and extracted) that pertain to validating the health of a cluster before we started or continued upgrading it.
We used this code to ensure that a cluster was fully healthy before continuing to replace instances. The code relies on boto3 APIs provided for Auto Scaling Groups and Elastic Load Balancers to ensure the number of healthy instances in the ELB are at least the same as the desired instances in the Auto Scaling Group.
Watching it All Unfold
Looking at New Relic, a fellow AWS Competency Partner and the tool we use for performance analytics, we were able to see the impact of the upgrade immediately, and in almost every case we saw a dramatic reduction of latency. On our home page, for example, our average response time was cut in half. We saw similar results for many of our customers, including a 50 percent reduction of PHP runtime for many sites, as well as a 50 percent reduction in total response time for others.
While the latency reduction on a single operation was relatively small, the reductions added up with the number of network requests required in a highly available environment that spans multiple Amazon EC2 instances and AZs.
Our team was certainly pleased with the end result. We felt as though we had gone through a productive process of identifying a customer need, finding a way to solve it, and then executing on it successfully. Yes, there were some minor issues that came up at the zero hour, but even then we were pleased with how our team reacted and ultimately remedied those issues quickly.
All of that said, none of this would have been possible without our partners at AWS, including our Technical Account Manager (TAM) and AWS Support team. They helped us out immensely with scheduling and prioritizing so that we could get the right number of instances reserved for the upgrade.
For one of our largest regions, we were dealing with thousands of machines, and without the help of our AWS team we would have had to delay and split up the rollout of an upgrade to the region that supports the majority of our customers.
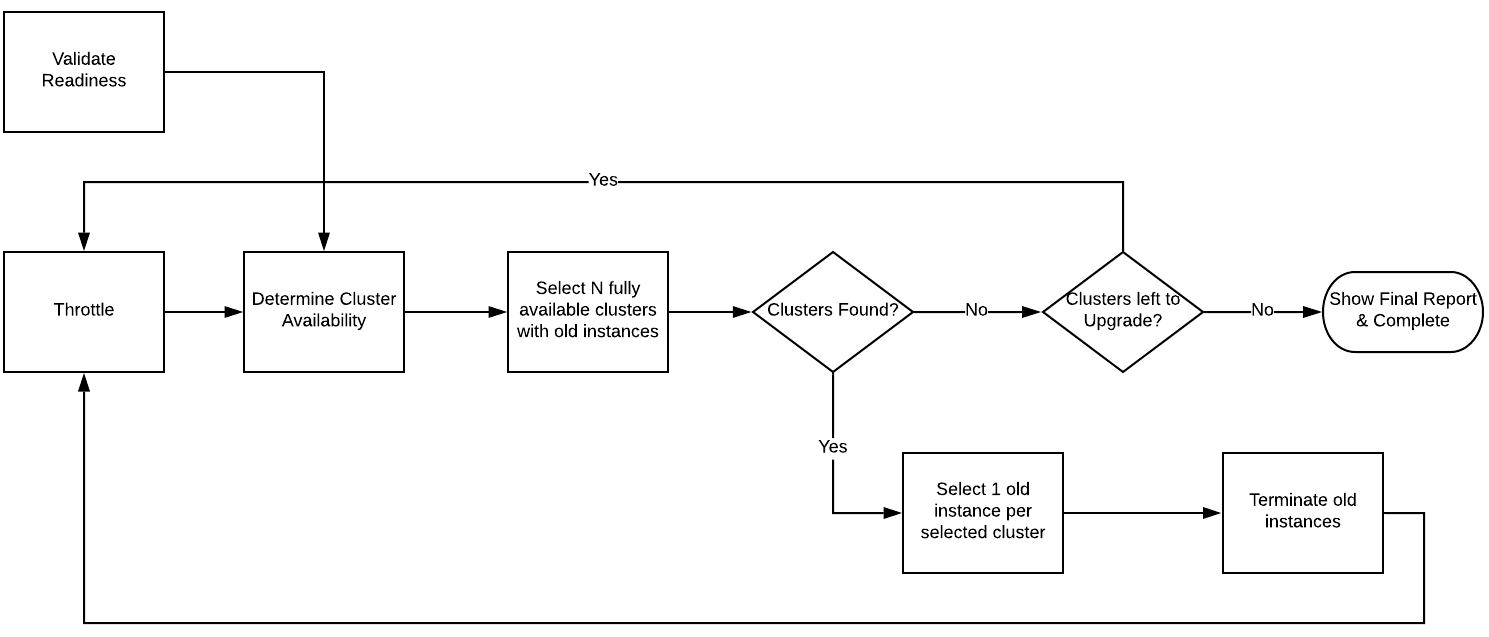
Figure 2 – Overall flow for our instance migration.
Results and Next Steps
We had messages of thanks that made it all the way to the developer team, which is not always a common occurrence. By and large, they were pleased with the upgrade and many customers told us their sites were running faster than ever. Other stakeholders were impressed we were able to make this improvement without any downtime or noticeable consequence on their end.
Given the outcome, we’ll likely pursue a similar process when it’s time for another upgrade. We wrote this process with that idea in mind, and now that we’ve shown we can do it without customer downtime, we’re confident we’ll be able to provide this service again and again, as customer needs arise.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.
|
WP Engine – APN Partner Spotlight
WP Engine is an AWS Competency Partner. Its WordPress digital experience platform gives enterprises and agencies the agility, performance, intelligence, and integrations they need to drive their business forward faster.
Contact WP Engine | Solution Overview
*Already worked with WP Engine? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.