AWS Partner Network (APN) Blog
MongoDB Atlas Data Lake Lets Developers Create Value from Rich Modern Data
By Benjamin Flast, Sr. Product Manager, Atlas Data Lake at MongoDB
 |
With the proliferation of cost-effective storage options such as Amazon Simple Storage Service (Amazon S3), there should be no reason you can’t keep your data forever, except that with this much data it can be difficult to create value in a timely and efficient way.
This is why some data lakes have gradually turned into data swamps, providing little utility and accentuating the need for novel ways of analyzing rich multi-structured data created by modern applications, APIs, and devices.
MongoDB’s Atlas Data Lake enables developers to mine their data for insights with more storage options and the speed and agility of the Amazon Web Services (AWS) Cloud.
MongoDB is an AWS Partner Network (APN) Advanced Technology Partner with the AWS Data & Analytics Competency. Our general purpose database platform can unleash the power of software and data for developers and the applications they build. MongoDB is available as a service on AWS via MongoDB Atlas.
MongoDB Cloud Database (Atlas) already addresses diverse online operational and real-time analytics use cases with strict low-latency and geo-distribution requirements. Atlas Data Lake expands MongoDB’s reach into batch and offline workloads, where efficiently processing massive volumes of rapidly changing data is the central problem statement.
Examples include data exploration across historical archives, aggregating data for market research or intelligence products, processing granular Internet of Things (IoT) data as it lands, model training and building, and more.
If you are a developer or data engineer already familiar with the MongoDB Query Language (MQL) and aggregation framework, you can apply the same familiar tools and programming language drivers to tackle a new class of workloads.
Analyze Data Stored in Multiple Formats
Atlas Data Lake allows you to take richly structured data in a variety of formats (including JSON, BSON, CSV, TSV, Avro, and Parquet, with more coming), combine it into logical collections, and query it using MQL.
This allows you to immediately get value from data without complex and time-consuming transformation, predefining a schema, loading it into a table, or metadata management.
Extract, Transform, Load (ETL) is still much of today’s work, and it’s becoming less cost effective to apply this legacy pattern to modern data of diverse shapes and huge volumes. With Atlas Data Lake, you can start exploring your data the minute it’s in Amazon S3 and you’ve configured your stores.
No Infrastructure to Set Up and Manage
Since Atlas Data Lake allows you to bring your own data in its current Amazon S3 structures, there’s no additional infrastructure to manage and no need to ingest your data elsewhere.
As such, we’ve separated compute from storage, which means Atlas Data Lake is an on-demand service where you only pay for what you use. This allows you to seamlessly scale each layer independently as needs change.
To get started, you just need to configure access to your Amazon S3 storage buckets through the intuitive user interface in MongoDB Atlas. Give read-only access if you’re only using the product for queries, or write access if you’d like to output the results of your queries and aggregations back to S3.
Atlas Data Lake is fully integrated with the rest of MongoDB Atlas in terms of billing, monitoring, and user permissioning for additional transparency and operational simplicity.
For users who already have a data lake based on S3, or have created one with AWS Lake Formation, you can still use Atlas Data Lake. Simply set up your storage config to describe what’s been created in AWS Lake Formation, and you can start querying.
Parallelize and Optimize Workloads
Atlas Data Lake’s architecture uses multiple compute nodes to analyze each bucket’s data and parallelizes operations by breaking queries down and then dividing the work across multiple agents.
Atlas Data Lake can automatically optimize your workloads by utilizing compute in the region closest to your data. This is useful for data sovereignty-related needs, granting you the ability to specify which region your data needs to be processed in, and giving you a global view of data with greater security.

Figure 1 – Atlas Data Lake architecture diagram.
Leverage a Rich Ecosystem of Tools
Atlas Data Lake also works with existing MongoDB drivers, the MongoDB shell, MongoDB Compass, and the MongoDB BI Connector for SQL-powered business intelligence. Support for visualization with MongoDB Charts is coming soon.
This means your existing applications written in JavaScript, Python, Java, Ruby, Go, or any other programming language can access Atlas Data Lakes just like they access MongoDB today. For data science and machine learning (ML) workloads, you can use tools like R Studio or Jupyter Notebooks with the MongoDB R and Python drivers or the Spark Connector.
Enable Data Exploration on Historical Archives
To bring Atlas Data Lake to life, I’d like to give you an example of how powerful it can be when combined with the MongoDB Aggregation Framework.
Imagine your company has just acquired a grocery store to add to its existing network of stores. Your boss tells you they want to run a promotion targeted at customers that have historically purchased the most at the new store.
You’re pointed to the data in your Amazon S3 and your boss asks you to pull the Customer IDs of top buyers across all files. The data files exist in a variety of formats, across several years, and they’d like you to focus on customers making purchases over the prior year. That said, the data looks something like this.
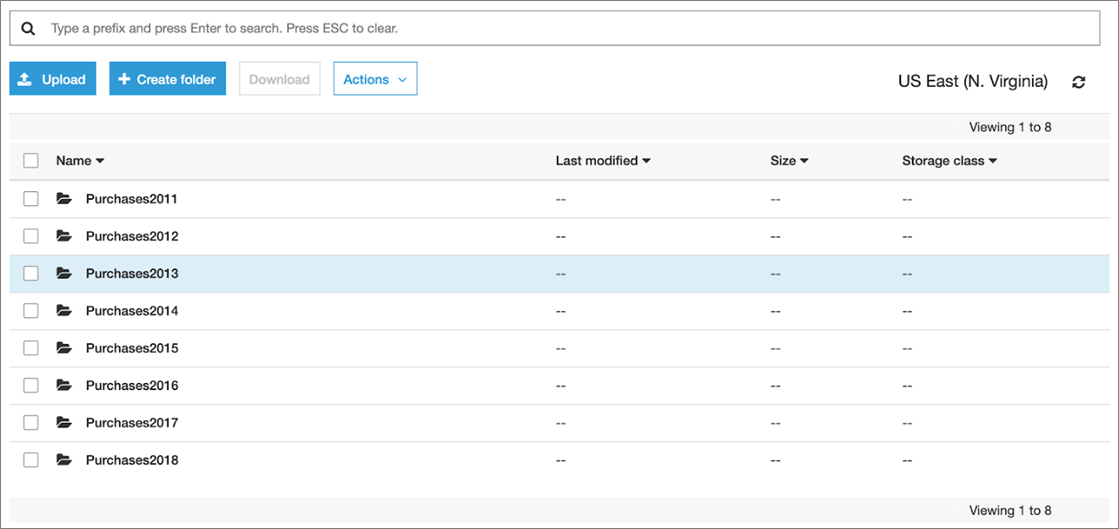
Figure 2 – Sample Amazon S3 bucket data.
Given this request, you decide to use Atlas Data Lake. The first step is to set up a data lake and configuration file.

Figure 3 – Data lake configuration and metrics.
You write your storage configuration to have one collection called ‘purchases’ with a definition that reflects data partitioned by year on Amazon S3. Each partition may contain any number of files of any supported format.
This configuration will enable Atlas Data Lake to only open partitions related to the data your query needs when you utilize the year in the query.
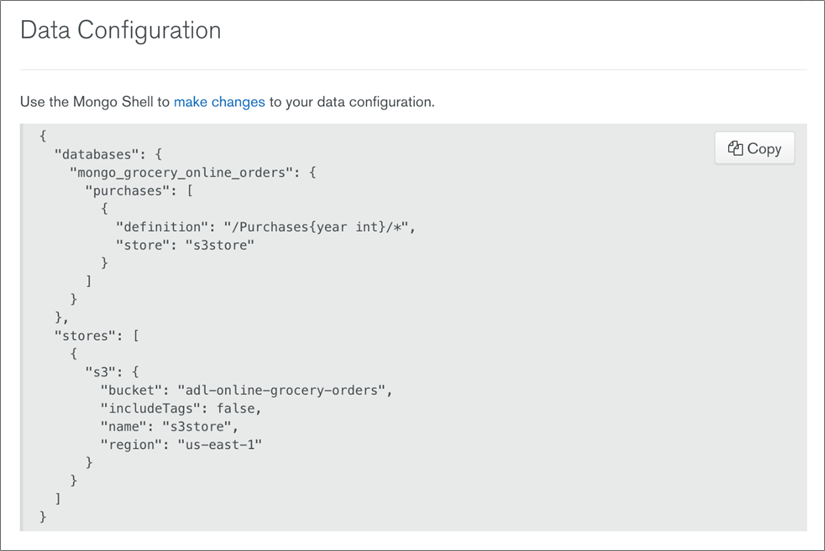
Figure 4 – Storage config example.
Once you’ve set the new storage config, you only need to write up a short aggregation pipeline and run it on your data lake, as shown below.
You match to queries from the year 2018, group individual transactions by CustomerID, sum transactions across quantity ordered and purchase price, sort it, and limit it to six (unfortunately they did not tag all purchases to a Customer ID).
Just like that, you’ve got the top five buyers from the chain you’ve just acquired.

Figure 5 – Results of aggregation pipeline query.
This is a simple example of the power of Atlas Data Lake. As demonstrated in this example, it’s designed to allow you to get the most from your data.
Other ways you can use Atlas Data Lake include providing data exploration capabilities across user communities and tools, creating historical data snapshots, enabling feature engineering for machine learning, and more, with the least amount of upfront work and a low investment.
Summary
Atlas Data Lake provides a serverless parallelized compute platform that gives you a powerful and flexible way to analyze and explore your data on Amazon S3.
As you’ve seen in this post, Atlas Data Lake supports a variety of formats and doesn’t require a predefined schema, or any schema evolution over time. By decoupling compute from storage, we’ve enabled you to scale each as needed. Atlas Data Lake plugs into the MongoDB ecosystem, allowing you to get more from your data lake with the tools you already use.
In my example, I covered how to set up a data lake and connect to your S3 bucket. I also demonstrated how you can configure your data lake to efficiently open partitions of data and keep your queries performant. Finally, using the power of the aggregation pipeline, I ran sophisticated analysis on data stored in S3, demonstrating the potential of using existing queries created for MongoDB.
To learn more, check out the MongoDB data lake product page or read our documentation. You can also sign up for Atlas to get your own data lake up and running in just a few minutes.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.

.
MongoDB – APN Partner Spotlight
MongoDB is an AWS Competency Partner. Their modern, general purpose database platform, designed to unleash the power of software and data for developers and the applications they build.
Contact MongoDB | Solution Overview | AWS Marketplace
*Already worked with MongoDB? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.