AWS Partner Network (APN) Blog
Read/Write Capability Enhancements in Amazon Aurora with Apache ShardingSphere-Proxy
By Lili Ma, Sr. Database Solutions Architect – AWS
By Wenjing Hu, Partner Solutions Architect – AWS
By Juan Pan, CTO – SphereEx
 |
| SphereEx |
 |
Amazon Aurora is a relational database management system (RDBMS) developed by Amazon Web Services (AWS) that gives you the performance and availability of commercial-grade databases with full MySQL and PostgreSQL compatibility.
Aurora supports up to 128 TiB of storage and storage dynamic resizing as your data changes. It supports up to 15 replicas and read replicas auto scaling, and provides a multi-primary architecture with up to four read/write nodes.
Amazon Aurora Serverless v2 allows vertical scaling and and can scale database workloads to hundreds of thousands of transactions in a fraction of a second, while Amazon Aurora Global Database enables a single database cluster to span multiple regions with low latency.
Aurora already provides great scalability with the growth of user data volume and workloads. However, customers may need further extend the scalability of OLTP database such as supporting data volume more than 128 TiB, or supporting more concurrent writes and you may expect little overhead to the application.
ShardingSphere-Proxy includes features for sharding, read/write separation, and dynamic configuration. It can help you achieve this by separating the complex configuration relationship between the application and multiple underlying Aurora clusters.
This post focuses on how to use ShardingSphere-Proxy to build database clusters, covering aspects such as sharding, read/write splitting, and dynamic configuration.
Apache ShardingSphere is an ecosystem of open-source distributed database solutions, including JDBC and Proxy products, which can be deployed either independently or in combination. The commercial edition provides additional data security and data sharding features from AWS Partner SphereEx, which was founded by the core team of Apache ShardingSphere.
Introducing ShardingSphere-Proxy
ShardingSphere-Proxy is transparent to applications and compatible with MySQL and PostgreSQL clients. The sharding and read/write splitting capability supports connecting to different databases which can be homogeneous or heterogeneous.
ShardingSphere-Proxy embeds the connection pool to connect underlying databases, and supports multiple connection pool implementations like Hikari, a widely used connection pool with low performance loss and adopted by SpringBoot as the default connection pool.
ShardingSphere-Proxy supports most MySQL syntax with only a few exceptions of optimizing table, resource group management, user creation and GRANT permission management. You can refer to the latest ShardingSphere-Proxy document for more information.
Deploying ShardingSphere-proxy and Amazon Aurora in your AWS account with the following architecture is recommended.
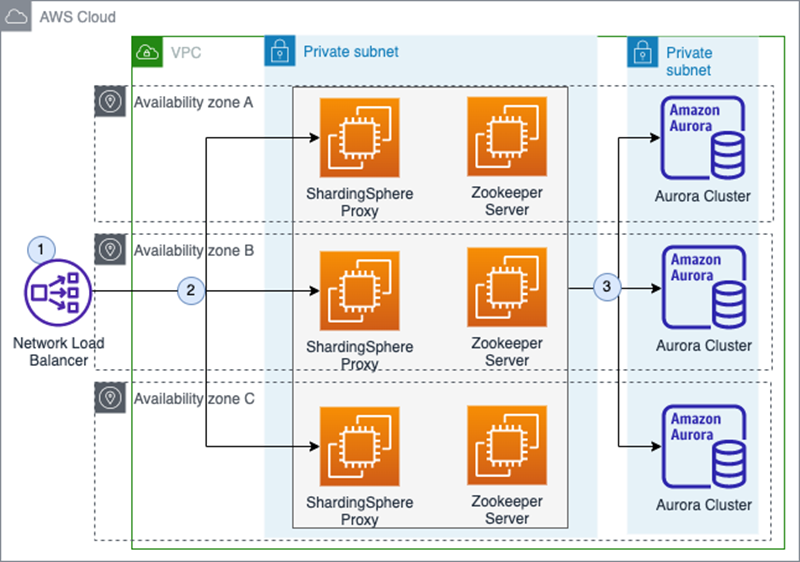
Figure 1 – ShardingSphere-Proxy and Aurora deployment.
The architecture diagram above displays the deployment and network connection for ShardingSphere-Proxy and Aurora clusters in a customer-managed VPC:
- All incoming requests to ShardingSphere-Proxy will be received by the Network Load Balancer.
- ShardingSphere-Proxy has provided the solution of Zookeeper by default, which implements the functions of config center and registry center.
- ShardingSphere-Proxy starts to parse/rewrite/route SQL through sharding core functions to backend Aurora databases and combines the results to reply the request.
In the next sections, let’s look at ShardingSphere-Proxy’s connection to Aurora from several aspects:
- Sharding
- Dynamic scaling
- Read/write splitting
- Database failover
Sharding
ShardingSphere-Proxy supports two methods to create sharding rules and read/write splitting rules: YAML and DistSQL.
DistSQL extends the SQL syntax and supports creating data sources online, and creating and modifying table creation rules, which is more flexible. This post focuses on DistSQL.
Create a Database
Connect to ShardingSphere-Proxy to create a database as a logical distributed database:
Create databases on each Aurora cluster, which are connected as data sources:
Create a Data Source
Run the following DistSQL statement in ShardingSphere-Proxy to create data sources corresponding to different Aurora clusters.
You need change the user and password information to your user/password connecting to Aurora cluster. It’s highly recommended you store the password information in AWS Secrets Manager and fetch it and set the data source connection through code.
Create a Sharding Rule
In this example, let’s specify the sharding rule for the t_order table. The table names used by the sharding rule should be consistent with the names of the tables to be created later. The specific rules are: run hash-based sharding to the table for the underlying three data sources (Aurora cluster) according to order_id and partition the table into six shards.
In addition, the AUTO value generation strategy is used for order_id, using the Snowflake algorithm. ShardingSphere supports two distributed primary key generation strategies: UUID and SNOWFLAKE.
Run the following DistSQL statement in ShardingSphere-Proxy to establish sharding rules:
Create a Table
The table creation statements are consistent with the common MySQL statements for table creation. Run the following statements in ShardingSphere-Proxy to create tables:
Connecting to each of the three Aurora clusters, we find that two tables are created on each of the underlying database clusters for a total of six tables, which are sorted by the table names in the t_order_ numbers. More specifically: t_order_0 and t_order_3 in cluster 1, t_order_1 and t_order_4 in cluster 2 and t_order_2 and t_order_5 in cluster 3.
The insert/select to the logical table on ShardingSphere can effectively operate the tables on the underlying Aurora clusters.
ShardingSphere-Proxy has the ability to create a logical database, connect data sources, create sharding rules, automatically create sub-tables on the underlying database when creating logical tables, and perform query distribution and aggregation.
Dynamic Scaling (Online Scaling and Sharding)
ShardingSphere-Proxy supports online changes to sharding rules. For example, we can run the following DistSQL on ShardingSphere-Proxy to increase the number of shards for the table in the previous example from six to nine:
The above DistSQL can change the sharding rules in ShardingSphere-Proxy successfully. Please note the creation of sub-tables and redistribution of data needs to be done manually in underlying Aurora clusters. You can infer which Aurora cluster the sub_table should be on using the modulo operation of dividing the sub_table suffix ordinal by the number of Aurora clusters.
Join Upon Binding Tables and Broadcast Tables
Although operations in OLTP databases are generally simple, there are cases where multiple table joins can be involved.
ShardingSphere-Proxy supports two kinds of joining: 1) joining between binding tables with the sharding key as the join key, and 2) joining between a sharding table and a broadcast table.
Binding Tables
ShardingSphere-Proxy can bind two tables through the CREATE SHARDING BINDING TABLE RULES in DistSQL. Here, we use the t_order table mentioned earlier and a newly created table, t_order_item, to illustrate.
Connect to ShardingSphere-Proxy and run the following DistSQL and SQL statement:
After we create the two tables and the binding rule, we can do the join upon the sharding key. When looking at the join plan, we find the join is pushed down to the corresponding sub-tables to do the sub-table join.
Broadcast Tables
Each broadcast table has a complete copy in each database. You can specify this parameter using CREATE SHARDING BROADCAST TABLE RULES:
Log in to each Aurora cluster to view the created tables. Unlike the sub-table names of the shard table, which have a number indicating the order at the end, the name of each table in the Aurora cluster is the same as that of the logical table itself.
ShardingSphere-Proxy does the join between the broadcast table and other tables in the local join mode; individual shard does join itself and the proxy is in charge of aggregation.
Read/Write Splitting
ShardingSphere-Proxy supports read/write splitting. As your business grows, the write and read loads on different database nodes can effectively provide the processing capability for the entire database cluster.
Aurora uses a cluster endpoint to meet your requirements to write and read with strong consistency, and a reader endpoint to meet your requirements to read without strong consistency. Aurora’s read and write latency is in milliseconds—much lower than MySQL’s binlog-based logical replication—so there are a lot of loads that can be directed to a reader endpoint.
The read/write splitting feature provided by ShardingSphere-Proxy further encapsulates Aurora’s cluster endpoint and reader endpoint. You can connect directly to the proxy endpoint for automatic read/write splitting.
The processing logic of ShardingSphere-Proxy for special cases is as follows:
- In the same thread and the same database connection, if there’s a write operation the subsequent read operation is read from the writer node.
- You can use
Hintto forcibly send read requests to write node.
Configure a Read/Write Splitting Rule
Create the read/write splitting rules to send write requests to write data sources and read requests to read data sources.
Unlike the sharding rule, which requires that a rule be followed by a table name, the rule here is followed by the name of the data source, which applies to all tables created in the database.
Pre-define the data source write_ds/read_ds to Aurora’s cluster/reader endpoint, and then run the following DistSQL statements on ShardingSphere-Proxy:
When you check the read/write latency of the write node and read node in the Aurora cluster, you can see that write latency occurs only on the write node, and read latency occurs only on the read node. This can indicate that the read/write splitting rules have taken effect.
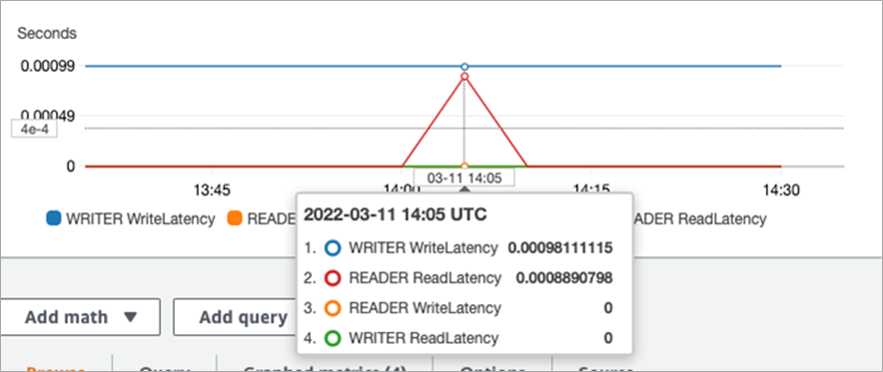
Figure 2 – Verify read write splitting on Aurora.
Although the replication latency between Aurora’s write node and read node is very low (in milliseconds), some applications still have strong consistency requirements that require a read immediately after a write. In this case, you can force a read request to be sent to a write node. ShardingSphere-Proxy supports it with hint.
You can force reading request to the writer node by setting two variables: proxy_hint_enabled and readwrite_splitting hint source in session level via DistSQL.
ShardingSphere-Proxy also supports the combination of both sharding and read/write splitting. For example, if three Aurora clusters are allocated and each cluster needs to provide read/write splitting, we can directly put the data source name (wr_ds) defined by the read/write splitting rule into the data source (ds_0, ds_1, ds_2) specified by sharding rules for each table.
Database Failover
ShardingSphere-Proxy has sensibility for the failover of Aurora clusters. In the event of the active/standby switch of an Aurora cluster, it would be ideal if the proxy could dynamically detect the switch and connect to the new primary database. However, at this time it doesn’t support perfectly.
When Aurora failover occurs, the mapping between the cluster endpoint and the IP address changes, and the connection pool of ShardingSphere isn’t updated to a new IP address automatically.
We can use the following workaround of creating the data source to force ShardingSphere-Proxy to refresh and point to the new write node, namely to recreate the data source. Although the definition of the data source itself hasn’t changed, ShardingSphere-Proxy can run successfully by running alter resource operation to reconstruct the data source and retrieve the updated mapping from the endpoint to the IP.
You need to change the user and password information for your user/password connecting to writing and reading data source. It’s highly recommended you store the password information in AWS Secrets Manager and fetch it and set the data source connection through code:
We can explicitly call the preceding statement when we detect a failover event of Aurora or receive a read-only error. To reduce the impact on the application, we can use AWS Lambda to automate the operation of resetting the data source with failover.
Because the Aurora failover event can be detected, we can write a Lambda function that displays the call to change the resource when the failover is detected.

Figure 3 – Detecting Aurora failover on ShardingSphere.
Conclusion
This post explains the capabilities of Aurora through database middleware ShardingSphere-Proxy.
ShardingSphere-Proxy has a built-in connection pool and strong support for MySQL syntax, and it excels in sharding and read/write splitting. It supports joining multiple tables with the same sharding rules and joining small tables and large tables, essentially meeting the requirements of OLTP scenarios.
In terms of dynamic sharding, ShardingSphere-Proxy supports online changes to sharding rules but requires you to manually create sub-tables and migrate data in the underlying Aurora clusters, which requires a certain amount of work.
In terms of failover, you can enable ShardingSphere-Proxy to work seamlessly with Aurora failover by capturing Aurora failover event and resetting data source using AWS Lambda.
ShardingSphere-Proxy is a good match for Aurora clusters for extending the read/write capability. Equipped with well-designed documents, SphereEx offers ShardingSphere-Proxy with both open-source and enterprise options for customers when considering sharding with Aurora.
.

.
SphereEx – AWS Partner Spotlight
SphereEx is an AWS Partner that was founded by the core team of Apache ShardingSphere, an ecosystem of open-source distributed database solutions, including JDBC and Proxy products, which can be deployed either independently or in combination.