AWS Partner Network (APN) Blog
Secure and Flexible Self-Service Analytics with Cloudera Data Warehouse and Amazon EKS
By Jobin George, Sr. Partner Solutions Architect at AWS
By Colin Bookman, Sr. Solutions Architect at AWS
By Ali Bajwa, Director, Partner Engineering at Cloudera
By Nijjwol Lamsal, Partner Solutions Engineering at Cloudera
 |
The demands of modern data warehousing spans analysis across all data—those that originate from traditional backend business systems to those that come from sensors at the edge.
The expectations from data warehousing solutions have gone up significantly, raising questions like:
- How do we manage the data tsunami while shortening the data warehouse lifecycle?
- How do we support hundreds of new use cases that arise from making this data available?
- How do we cost-effectively scale, dynamically, across a choice of environments, spanning the data center and the cloud?
Cloudera is an AWS Partner Network (APN) Advanced Technology Partner with the AWS Data & Analytics Competency.
Cloudera Data Platform (CDP) delivers powerful self-service analytics across hybrid and multi-cloud environments, along with sophisticated and granular security and governance policies that IT and data leaders demand.
In this post, we’ll provide an overview of how CDP’s integration with Amazon Elastic Kubernetes Service (Amazon EKS) enables customers to auto scale compute up and down as workload demand changes. Amazon EKS makes it easy to deploy, manage, and scale containerized applications using Kubernetes on Amazon Web Services (AWS).
Cloudera Data Platform (CDP)
Cloudera Data Platform (CDP) combines the best of Hortonworks and Cloudera technologies to deliver an enterprise data cloud that includes a unified control plane to manage infrastructure, data, and analytic workloads across environments.
CDP Cloud consists of a number of cloud services designed to address specific enterprise data cloud use cases. This includes Data Hub powered by Cloudera Runtime, self-service apps (Data Warehouse and Machine Learning), the administrative layer (Management Console), and SDX services (Data Lake, Data Catalog, Replication Manager, and Workload Manager).
CDP can enforce consistent data security, governance, and control that safeguards data privacy, regulatory compliance, and prevents cybersecurity threats across these environments.

Figure 1 – Overview of CDP services and components.
It’s an integrated data platform that is easy to deploy, manage, and use. By simplifying operations, CDP reduces the time to onboard new use cases across the organization. It uses machine learning (ML) to intelligently auto scale workloads up and down for more cost-effective use of cloud infrastructure.
Key Components and Services in CDP
Cloudera Data Platform control plane provides the common set of tools like Workload Manager, Replication Manager, Data Catalog, and Management Console.
The architecture in Figure 2 shows how CDP Control Plane or Management Console interact and manage lifecycle of resources in the customer account. Cross-account roles help the console with permissions to control the resources in the account.
Amazon Elastic Compute Cloud (Amazon EC2) instances are used by CDP environments, Data Lake and Data Hub services to run the clusters, while Data Warehouse and Machine Learning experiences leverage Amazon EKS clusters to run the pods.
Both Data Lake and Data Warehouse experiences uses Amazon Relational Database Service (Amazon RDS) to store metadata. Amazon Simple Storage Service (Amazon S3) serves as the storage layer for all the services and components with in CDP, as shown below.

Figure 2 – High-level architecture of Cloudera Data Platform on AWS.
Let’s take a look at the key components and services of CDP.
Shared Data Experience (SDX)
Shared Data Experience (SDX) is a suite of technologies that make it possible for enterprises to pull all of their data into one place. This enables you to share that data with different teams and services in a secure and governed manner.
Data security, governance, and control policies are set once and consistently enforced everywhere, reducing operational costs and business risks while also enabling complete infrastructure choice and flexibility.
There are four discrete services within SDX technologies:
- Data Lake: A set of functionalities for creating safe, secure, and governed data lakes that provide a protective ring around the data wherever it’s stored, be that in cloud object storage or Hadoop Distributed File System (HDFS).
- Data Catalog: A service for searching, organizing, securing, and governing data within the enterprise data cloud.
- Replication Manager: A service for copying, migrating, snapshotting, and restoring data between environments within the enterprise data cloud. This service is used by administrators and data stewards to move, copy, backup, replicate, and restore data in or between data lakes.
- Workload Manager: A service for analyzing and optimizing workloads within the enterprise data cloud.
Management Console
The Management Console is a general service used by CDP administrators to manage, monitor, and orchestrate all of the CDP services from a single pane of glass across all environments.
If you have deployments in your data center as well as in multiple public clouds, you can manage them all in one place—creating, monitoring, provisioning, and destroying services. The following concepts, along with SDX, are key to understanding the Management Console service and CDP in general.
- Environments: In CDP, an environment is a logical subset of your cloud provider account including a specific virtual network. You can register as many environments as you require.
- Classic clusters: These are on-premises Cloudera Distribution of Hadoop (CDH) or CDP Data Center (CDP-DC) clusters registered in CDP.
- Data Hub clusters: Powered by Cloudera Runtime, these can be created and managed from the Management Console.
- Machine Learning workspace: These can be created from the Management Console and accessed by end users (data scientists) from the machine learning service.
- Data Warehouse clusters: These can be created from the Management Console and accessed by end users (data analysts) from the Data Warehouse service.
We will cover Cloudera Data Warehouse (CDW) in the remainder of this post, including a brief introduction of CDW, prerequisites, major components, how to setup CDW, and how we leverage Amazon EKS for this container-based CDP experience.
Cloudera Data Warehouse (CDW)
Data Warehouse is a CDP service for self-service creation of independent data warehouses and data marts that auto scale up and down to meet your varying workload demands. CDW provides isolated compute instances for each data warehouse/mart, automatic optimization, and enables you to save costs while meeting SLAs.
In the CDW service, data is stored in an object store in a data lake that resides in a specific cloud environment. The service is composed of:
Database Catalogs
A logical collection of metadata definitions for managed data with its associated data context. The data context is comprised of table and view definitions, transient user and workload contexts from the virtual warehouse, security permissions, and governance artifacts that support functions such as auditing.
One database catalog can be queried by multiple virtual warehouses.
Virtual Warehouses
An instance of compute resources that is equivalent to a cluster. A virtual warehouse provides access to the data in tables and views in the data lake that correlates to a specific database catalog.
Virtual warehouses bind compute and storage by executing queries on tables and views that are accessible through the database catalog that they have been configured to access.

Figure 3 – Creating Database Catalogs and Virtual Warehouses in a CDP environment.
The CDW service provides data warehouses and data marts that are:
- Automatically configured and isolated/
- Optimized for your existing workloads when you move them to the cloud/
- Auto scaled up and down to meet your workloads’ varying demands.
- Auto-suspended and resumed to allow optimal usage of resources to save costs.
- Compliant with the security controls associated with your data lake/SDX.
Prerequisites
Here are the steps to create CDW on AWS:
- Prerequisites for AWS environments in place.
- Access to Cloudera control plane (obtain this from your account team).
- Register an AWS environment and create a data lake.
Setting Up a Data Warehouse in CDP on AWS
From the Cloudera Management Console, click on Data Warehouse on the left side navigation panel.
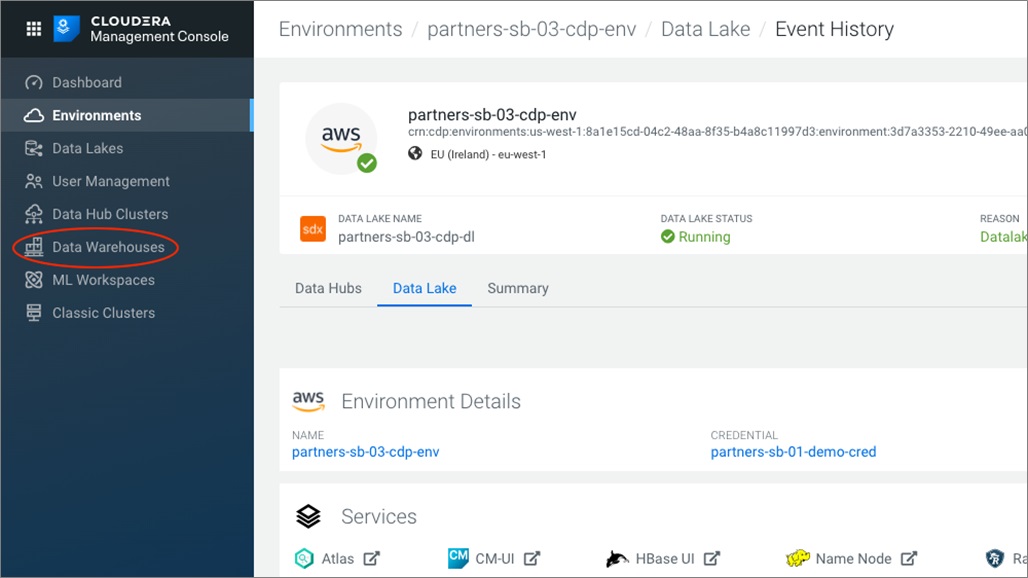
Next, click the + sign to create a new database catalog. Select the correct environment from the Environments drop-down, and then name your database catalog.

Once the database catalog is created, click the + sign to create a new virtual warehouse. Select the correct database catalog (the one you just created in the previous step) from the drop-down, and then name your virtual warehouse.
Select the Virtual Warehouse Size from one of the pre-set sizes available.

After you click on the virtual warehouse size you want, advanced configuration will become available, so scroll down.
Now, set the desired Auto-Suspend Timeout in seconds and the minimum and maximum nodes that can be used when auto scaling the virtual warehouse due to the load.

Demonstrate Auto Scaling Leveraging Amazon EKS
To increase workload flexibility in Cloudera Data Warehouse, start out with the newly-created virtual warehouse and notice NODE COUNT, TOTAL CORES, and TOTAL MEMORY values.
In the example below, 0 NODES, 11 CORES, and 48GB of MEMORY are allocated.

Here is a screenshot showing the Amazon EKS cluster in the AWS Console. Note the name of the Amazon EKS cluster env-g6bmcj-dwx-stack-eks from the example to use it in the next step.
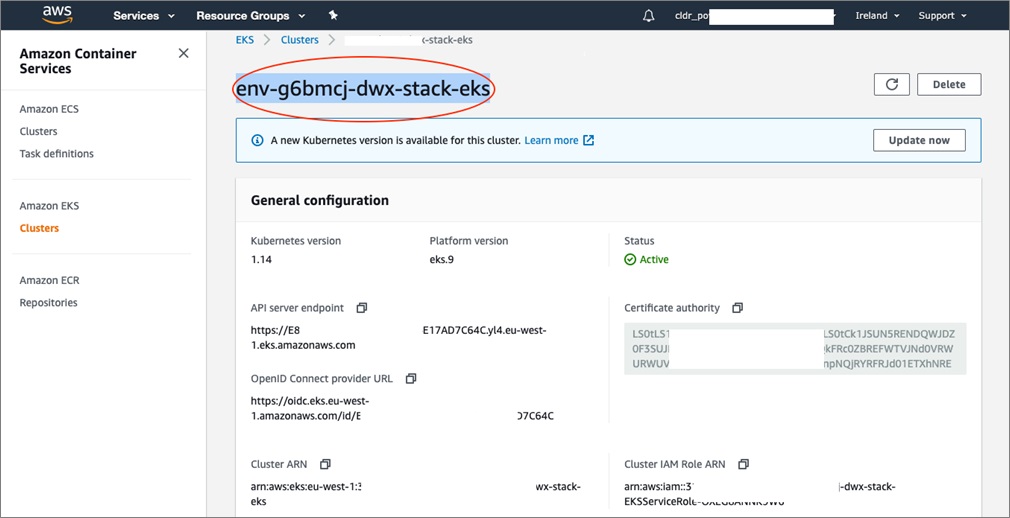
Click on the Services drop-down at the top of your AWS console and go to Amazon Elastic Compute Cloud (Amazon EC2).
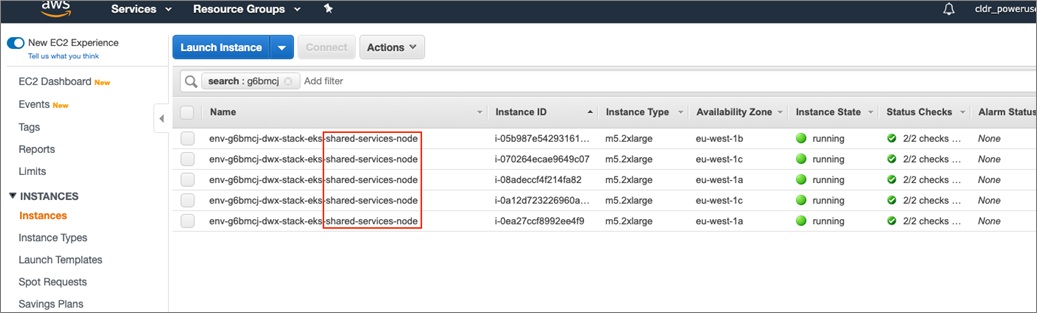
Once in the EC2 console, search for instances that contain the Amazon EKS string from above. Note there are no “compute” clusters connected with the Kubernetes environment. This is because there are no workloads running on the virtual warehouse.
In the CDW console, click on the three dots in the upper right corner of the virtual warehouse created earlier.
In the drop-down, you can see options to Stop or Start (depending on its current status), Clone, Delete, or Edit. There are various ways to connect to the warehouse.
End users access data warehouses via JDBC, HUE, DAS, and standard business intelligence tools such as Tableau, PowerBI, and Cloudera’s Data Analytics Studio (DAS) are used to illustrate the example below.

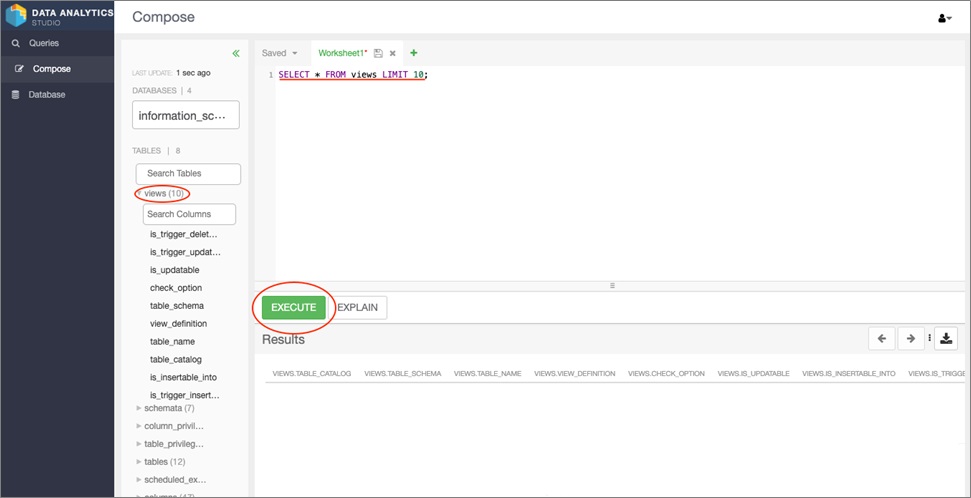
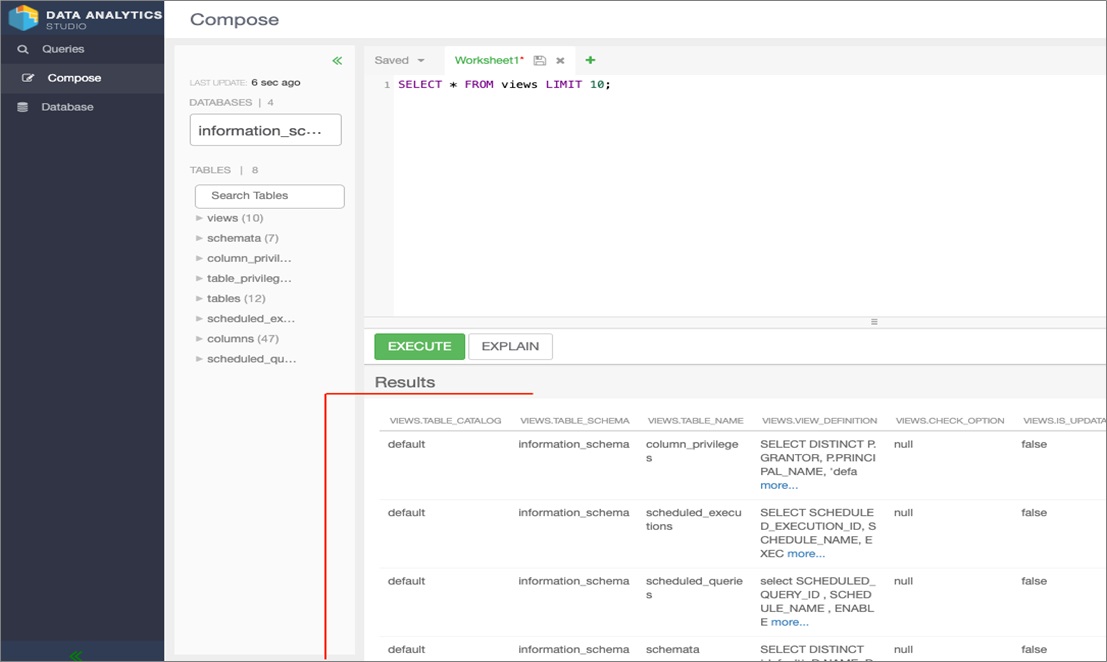
Data Analytics Studio allows users to run queries against the data warehouse data. Here, we run a simple SELECT * FROM views LIMIT 10. Then, click EXECUTE.
Return to the virtual warehouse status in the CDW console and notice NODE COUNT, TOTAL CORES, and TOTAL MEMORY values now that the query is running.
In our example, 2 NODES, 39 CORES, and 284GB of MEMORY are allocated.

Return to the AWS console to see how the Amazon EKS cluster starts ramping up. Two COMPUTE nodes that have been provisioned to handle the increased from the query.
Initializing:

Running:

Finally, back in the DAS, the query results are shown.
One last look at our Amazon EC2 console and we can see the compute nodes used to run this job auto-terminated, and the CDW compute reverts back to its resting state.

Summary
The steps outlined in this post show how Cloudera Data Platform (CDP) leverages Amazon EKS to enable customers to create self-service, independent data warehouses that auto scale up and down to meet workload flexibility.
Cloudera’s data warehouse (CDW) service on Amazon EKS provides isolated, secure, and compliant compute instances for each data warehouse/mart, automatic optimization, and enables customers to save costs while meeting SLAs
To get started with Cloudera Data Platform, sign up for a free trial and contact Cloudera for a demo.
.

.
Cloudera – APN Partner Spotlight
Cloudera is an AWS Competency Partner. Cloudera Data Platform (CDP) delivers powerful self-service analytics across hybrid and multi-cloud environments, along with sophisticated and granular security and governance policies that IT and data leaders demand.
Contact Cloudera | Solution Overview | AWS Marketplace
*Already worked with Cloudera? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.