AWS Partner Network (APN) Blog
Understanding Amazon SQS and AWS Lambda Event Source Mapping for Efficient Message Processing
By Tushar Sharma, Staff Serverless Developer – Serverless Guru
By Shaun Wang, Sr. Partner Solutions Architect – AWS
 |
| Serverless Guru |
 |
The integration between Amazon Simple Queue Service (SQS) and AWS Lambda is a major part of the architecture Serverless Guru uses for clients. To make the best use of a SQS-Lambda integration using event source mapping, it’s important to understand how the integration works.
For example, if you’ve ever worked with an SQS-Lambda integration, you may have had a use case where you want to set the maximum number of Lambda functions that will be invoked, but no such option was available.
In this post, we will share why that is and look at a solution to this limitation. Serverless Guru is an AWS Advanced Tier Services Partner that helps companies build, migrate, and train teams on Amazon Web Services (AWS) serverless development. Serverless Guru holds the AWS Lambda service delivery specialization.
Amazon SQS-AWS Lambda Event Source Mapping
Let’s say we have an SQS queue called user-clicks and want to process the click events in our Lambda function, so we configure an event source mapping between our SQS queue and the Lambda function, which we’ll call user-clicks-consumer.
Here’s what AWS does behind the scenes to provide this integration:

Figure 1 – SQS-Lambda event source mapping.
As shown in the diagram above, AWS has at most 1,000 (only five are shown here) parallel threads per region polling the SQS queue for messages. Each thread will poll our SQS queue, and if messages are available it will receive a batch of messages from the queue.
It then synchronously invokes a Lambda function with this batch. If the Lambda function returns successfully, the thread deletes the messages that were in the batch from the queue. If the Lambda function returns an error (not a throttling error), the thread doesn’t do anything and the messages appear in the queue again after the visibility timeout is over.
Configuring the SQS-Lambda Integration
AWS provides the following options to configure this type of integration:
- Batch size: The number of records to send to the function in each batch. For a standard queue, this can be up to 10,000 records.
- Batch window: The maximum amount of time (in seconds) for which AWS will poll the SQS queue before invoking the Lambda function.
The options provided do give some control over how you want AWS to handle the polling and invocations for you.
Scaling the SQS-Lambda Integration
AWS can launch up to 1,000 parallel threads polling the queue at any given time if the queue size is large. This might sound great as it would help empty the queue pretty fast, but you have to consider if the downstream services can take that load.
Let’s go through a few scenarios to understand that use case.
Handling Large Queues
Scenario #1: If you have a large queue, you can increase the batch size and keep the batch window short. This way, the polling threads are quickly dequeuing messages from SQS and sending them to your Lambda functions. This approach fits well if you want to drain your queues as fast as possible.
Handling Small to Medium Size Queues
Scenario #2: If you have a small size queue, you can adjust the batch size to be smaller and the batch window to be longer. This way, the Lambda threads are efficiently batching SQS messages before sending the batch to the function.
For example, if your queue gets a new message every second and your batch window size is one second, then the Lambda thread will invoke your function 60 times in one minute, with each invocation consisting of just one message in the batch.
If you increase the batch window to 60 seconds, then it will poll the queue for 60 seconds and invoke your Lambda function with 60 messages in the batch. This is more efficient as it makes just one Lambda invocation per minute rather than 60 invocations per minute.
Keep an Eye on the Visibility Timeout
Another configuration option to keep in mind is the visibility timeout on the SQS queue. When a message leaves an SQS queue, it’s not deleted from the queue; it’s just hidden from the other consumers in the queue for a certain period. That period is called the “visibility timeout.”
Once the visibility timeout is over, the message is visible again to all of the consumers in the queue. This means that to successfully process a message, you must process the message within the visibility timeout. You also have to make an API call to delete the message from the queue before it is visible.
To understand this behavior better, here’s an example queue with six messages and two consumers: A and B. They both poll the queue for one message at a time—A gets the message with the ID 1, and B gets the message with the ID 2.
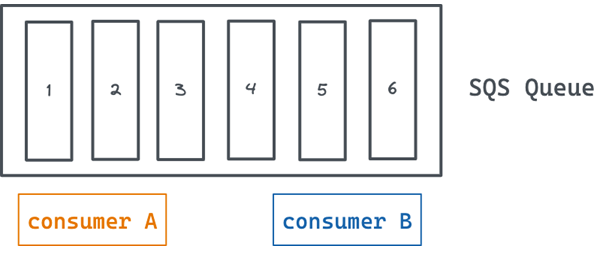
Figure 2 – An SQS queue with two consumers.
As you can see, while A and B are processing the message the messages are not deleted from the queue; they are just hidden. So, if there was another consumer it would never get the message #1 and #2 if it polls the queue.
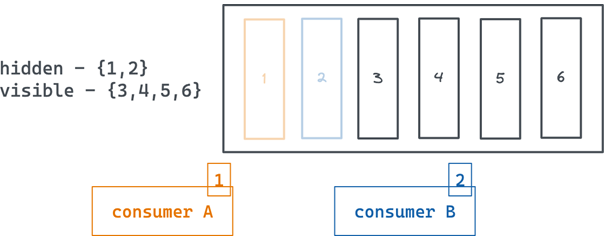
Figure 3 – SQS consumers A and B processing messages.
Let’s say the visibility timeout on the queue is 60 seconds. Consumer A processed the message in 30 seconds and then deleted the message from the queue—all before the 60-second timeout. The message never appeared again in the queue and was only processed once.

Figure 4 – SQS consumer B processing a message.
On the other hand, consumer B took more than 60 seconds to process the message and then deleted it. Consumer B deletes the message after 80 seconds, but there are high chances this message was also processed by consumer A. Let’s try to understand why that may have had happened.
The visibility timeout for the queue is 60 seconds, so after 60 seconds the message appeared again on the queue while consumer B is still processing it.

Figure 5 – SQS message with ID 2 is visible in the queue while still being processed by consumer B.
Now, since the message is visible in the queue, consumer A receives it in a batch (while B is still processing it).

Figure 6 – SQS message with ID 2 is being processed by both consumer A and B.
Although consumer B deletes the message later on, it has already been processed by consumer A.

Figure 7 – SQS consumer A is processing the message with ID 2.
That’s why for the SQS-Lambda integration, it’s advised to keep the visibility timeout to be the sum of Lambda function timeout, batch window time, and an additional 30 seconds as buffer.
This ensure you allocate enough time for the polling thread to wait (batch window time), invoke your Lambda function (Lambda timeout), and then delete messages from the queue (buffer time). Otherwise, you may start to see a lot of messages in your queue being processed more than once as we saw in the example above.
Dequeuing Messages One by One
There are use cases where you want to consume messages in a queue one after the other synchronously. For example, if you have multiple instances of your application and each instance makes a lot of writes to the database, the database might not be able to handle that many parallel connections.
Imagine 1,000 parallel Lambda functions creating Transmission Control Protocol (TCP) connections and sending requests to your database. With one of Serverless Guru’s clients, the team used Promise.all to make 200+ concurrent requests to the database per Lambda, so a total of 1,000 * 200 (i.e. 200,000) concurrent requests. The database server might not be able to handle that many concurrent requests, or you may see a lot of throttling errors.

Figure 8 – Multiple application instances writing to the database.
In scenarios like that, sometimes it makes sense to put a queue before the database and have just one consumer who dequeues a message from the queue and writes it to the database.
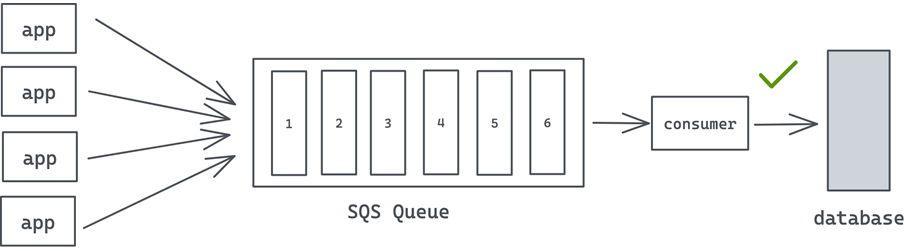
Figure 9 – Single SQS consumer writing to the database.
This is a fairly common pattern. The key lies in there being a finite number of consumers (often just one) to limit the number of parallel database connections.
Based on the SQS-Lambda integration architecture we just saw, it’s clear there can be at most 1,000 Lambda parallel functions processing the messages. If each one of them creates a new TCP connection to the database, imagine thousands of them spawning up and each one making a few connections.
Can AWS Lambda Reserved Concurrency Help?
A way to get around this issue is by setting reserved concurrency on the consumer Lambda function. When you configure reserved concurrency on a function, you limit the maximum number of parallel invocations of that function to a specific number. Regardless of who has invoked the function, AWS Lambda will throttle all the invocations of the function after its reserved concurrency is full.
For scenario #3, you can set the reserved concurrency for the consumer Lambda function to be one (1) and then enable the SQS-Lambda integration. You can safely assume there will only be at most one running invocation of that function at any given time despite the queue size.
Although this solution works, if you look at the metrics of the Lambda function, you’ll see a lot of throttling errors. You may also start to see a lot of SQS messages going to the dead letter queue (DLQ).
Lambda Reserved Concurrency and SQS Integration
AWS Lambda reserved concurrency only controls the invocations of the Lambda function and keeps the active invocations within the reserved concurrency limit. If you try to invoke the Lambda after the reserved concurrency is full, you’ll see throttling errors. In the case of the SQS-Lambda integration, the polling thread is just another client calling the Lambda function.
In this case, there will also be more than one polling thread (the actual number will be based on the size of the queue), and each thread will still try to invoke our Lambda function. The difference this time would be that once the reserved concurrency of our consumer Lambda is full, all of the threads will start to receive throttling errors for any subsequent invocation.
What happens, in this case, is that upon receiving a throttling error from the Lambda function, the polling thread tries invoking the function with the SQS batch a few more times before it rejects that batch. After the visibility timeout for the messages in the batch is over, they appear in the queue again.
The problem with this behavior is that if you have a redrive policy set on your queue, which you should according to AWS documentation, you may see a lot of messages going to the DLQ. This happens because once the polling thread fails to invoke your Lambda function with the SQS message, the message appears in the queue again with its receive count increased by one. The cycle could repeat multiple times, and once the receive count of a message reaches limit set in your redrive policy, the message is sent to the DLQ.
If you don’t have a redrive-policy, the message will only be deleted once its retention period is over.
Note that you can now configure the maximum concurrency of a Lambda function directly in the event source mapping.
FIFO Queues to the Rescue
A nice way to solve this is by using SQS FIFO queues. AWS even supports high-throughput FIFO queues.
FIFO queues work differently from normal queues as AWS needs to ensure each message is processed in the order it was sent, thus the name FIFO. If you integrate a FIFO SQS queue with AWS Lambda using event source mapping, for each message group AWS will spawn a single thread pulling in from the queue.
Here’s an excerpt from AWS documentation: “FIFO queue logic applies only per message group ID. Each message group ID represents a distinct ordered message group within an Amazon SQS queue.”
This means that AWS doesn’t apply the FIFO logic to all of the messages that go into a FIFO queue; it applies that logic to messages that belong to the same message group. A message group ID is an attribute you can set on a message when sending it to a FIFO queue.
When polling a FIFO SQS queue, Lambda is aware of the message group. If you put a single message group ID to all of the messages, AWS will only use one thread to poll the queue and will only make one Lambda invocation at a time.
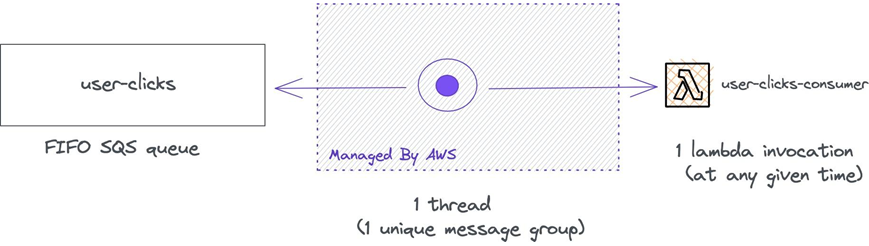
Figure 10 – SQS event source mapping for FIFO queues.
If you know that having two parallel Lambda functions will not impact the downstream service, you can use two unique message group IDs assigned to each message randomly, and AWS will only use two threads to poll the messages. At most, two Lambda invocations at any given time.
FIFO Queue vs. Reserve Concurrency
How is this better than setting reserve concurrency on AWS Lambda? With FIFO queue event source mapping, the polling threads don’t try to invoke Lambda functions aggressively. It will only invoke as many parallel functions as there are unique group IDs in the FIFO queue.
One thing to note is that with FIFO queues, you do incur a throughput loss of a regular SQS queue. Also, a FIFO queue has higher usage charges than a regular queue, so do consider those things when making this decision.
If using FIFO queues doesn’t fit your use case, you can always use AWS Batch or Amazon Elastic Container Service (Amazon ECS) tasks to consume the queue manually.
Conclusion
The Amazon SQS and AWS Lambda integration detailed in this post is a powerful feature, and for small to medium-sized queues you don’t have to think much about the integration as it works out of the box.
If you have questions surrounding how to implement a SQS-Lambda integration, or anything relating to serverless, get in touch with Serverless Guru.
.

.
Serverless Guru – AWS Partner Spotlight
Serverless Guru is an AWS Advanced Tier Services Partner that helps companies build, migrate, and train teams on AWS serverless development.