AWS Partner Network (APN) Blog
Use Matillion Data Loader for Change Data Capture Loading to Amazon Redshift Serverless
By Nidhi Gupta, Sr. Partner Solutions Architect – AWS
By Molly Sandbo, Director Product Marketing – Matillion
 |
| Matillion |
 |
Many businesses need to analyze vast amounts of data quickly without having to worry about the underlying infrastructure. With Amazon Redshift Serverless, users can run and scale analytics workloads seamlessly, paying only for the compute and storage resources they consume.
Businesses often have a need to use change data capture (CDC) to quickly and easily load incremental data to data warehouses. In this post, you will learn how to load data easily into Amazon Redshift Serverless using Matillion Data Loader. We’ll go through an example of CDC loading from PostgreSQL to Amazon Redshift Serverless as the destination.
Matillion is an AWS Data and Analytics Competency Partner with the Amazon Redshift specialization. An AWS Marketplace Seller as well, Matillion delivers modern, cloud-native data integration technology solving individual’s and enterprise’s top business challenges.
Matillion Data Loader is a software-as-a-service (SaaS) data loading platform that extracts data from popular sources and loads it into cloud data platform destinations. If you’d like to jump in right away, you can register and start using Matillion Data Loader for free at dataloader.matillion.com or through the Matillion Hub.
Some key features of Matillion Data Loader are:
- No-code pipeline creation to empower more users across organizations and speed up data pipeline creation and loading.
- Platform that supports both batch and CDC pipelines.
- Automatic schema drift propagation without assistance from IT or the need to code, saving time and reducing the number of job failures and delays due to source data schema drift.
- Integration with Matillion ETL for pre-built data transformations.
Let’s discuss in detail the steps to CDC data loading to Amazon Redshift using Matillion Data Loader.
Prerequisites
You should have the following prerequisites to get started with Matillion Data Loader:
- Active Matillion Hub account. For more information, read the Matillion Hub overview.
- PostgreSQL as the data source.
- Amazon Simple Storage Service (Amazon S3) as the destination to store data. Refer to the instructions for creating a bucket.
- Amazon Redshift as final destination. Refer to the documents below to set up Amazon Redshift:
- Credentials to allow Matillion Data Loader to connect with the source and destination systems.
CDC Loading into Amazon Redshift
Change data capture identifies and captures changes from an operational database in near real-time and delivers changed data to a destination for further processing.
Most database technologies write low-level transaction logs as changes occur within the database. These are typically used by the database to assist in disaster recovery scenarios. Log-based CDC technologies are also able to hook into these transaction logs and ingest all changes as they happen.
Matillion Data Loader’s CDC feature uses log-based CDC to capture every change event from database log files or change tables. This achieves the lowest latency, scales as needed, captures every data change, and does not impact database performance.
Matillion CDC provides an intuitive, no-code user experience to extract change data from the most commercially used source databases, like PostgreSQL, MySQL, Microsoft SQL Server, and Oracle.
Every Matillion CDC pipeline requires a CDC Agent to orchestrate the data extraction and loading tasks. It’s highly recommended you read the CDC Agent Installation documentation and consult your cloud administrator for help and permissions where required.
CDC through Matillion Data Loader occurs in a secure hybrid SaaS architecture. CDC pipeline setup and management occurs in the intuitive, wizard-based SaaS interface of Matillion Data Loader.
A CDC Agent is created to access your data source and cloud storage destination using the credentials you provide. The Agent is deployed into a container in your virtual private cloud (VPC) or in your on-premises environment.
The Agent executes the data extraction and data loading; and all data remains secure in your data environment. No data or access credentials are exposed outside your firewall.
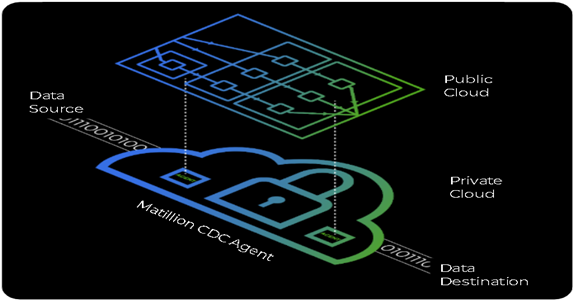
Figure 1 – Hybrid SaaS approach.
Once the data is in your cloud storage, developers, data scientists, and artificial intelligence (AI) and machine learning (ML) modelers can use the raw data immediately to perfect their algorithms and models. Here, you can also use Matillion ETL to create analytics-ready data and load that into your cloud data warehouse. This ensures data is not only up to date, but also analytics-ready in just minutes.
Let’s look at a real-life scenario where a business wants to extend their persona analysis above with real-time customer data to personalize their marketing campaigns.
They want to set up a CDC pipeline to ingest prospect engagement data from their PostgreSQL database and store that data in Amazon Simple Storage Service (Amazon S3). Then, they’ll use Matillion ETL’s intuitive low-code/no-code interface to prepare analytics-ready data and load that into Amazon Redshift. Check out this video for a brief demo of Matillion CDC.
Step 1: Create a Matillion CDC Agent
When you log in to Matillion Data Loader, click Agents on the left navigation to set up your CDC Agent. Follow the instructions in the CDC Agent installation and AWS Installation Overview documentation.
Click Add agent, input your CDC Agent information, and hit Continue.
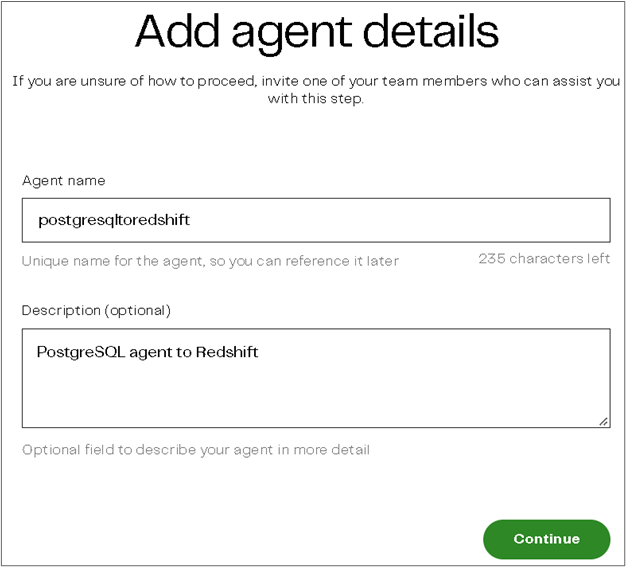
Figure 2 – Enter CDC Agent information.
Choose AWS as your cloud provider. Then, choose the service you wish to use to deploy your CDC Agent. For example, if you select AWS CloudFormation, you’ll be taken to a page that lists prerequisites, provides a template to use, and gives you additional information about configuration.
Follow the documentation carefully to deploy the Agent. It must be deployed and in a Connected state before you use it to create a CDC pipeline. Once you input the information and validate the key pair, you’ll see your Matillion CDC Agent in your dashboard.
Step 2: Set Up the Source Database for CDC
In this example, we are using Amazon Aurora PostgreSQL as the source database. Please refer to the links below to configure CDC in the database:
Step 3: Create Your CDC Pipeline
Now, it’s time to set up your CDC pipeline configuration. You first need to select the CDC Agent you want to use to manage your CDC pipeline. If you have several Agents set up and in a Connected state, click Add pipeline for the Agent you want to use.
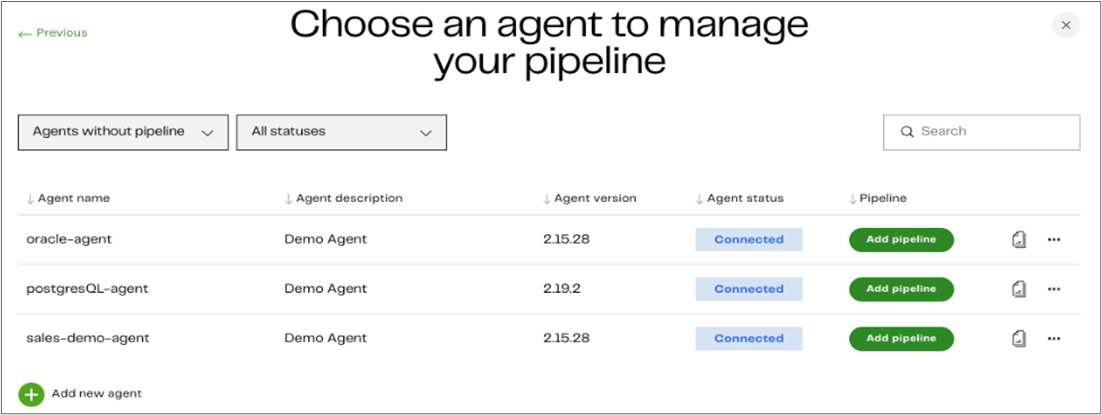
Figure 3 – Select the CDC Agent to manage CDC pipeline.
Next, choose PostgreSQL as your data source. Be sure to follow along in the CDC Sources Overview documentation. It’s essential your data source be configured properly for CDC. In this example, refer to PostgreSQL Connector for details and instructions.
Since you can set up either a batch or CDC pipeline from PostgreSQL, Matillion Data Loader asks which loading method you want to use. Select Change Data Capture.
Then, enter the information below to connect to your PostgreSQL database. In the example below, we are using provisioned Amazon Aurora DB clusters for CDC support, and we store the database user password in AWS Secrets Manager as a plain text secret. Learn more about how to set up secrets.

Figure 4 – Enter details to connect to PostgreSQL.
At this point, you can choose a single schema, multiple schemas, and associated set of tables to load from PostgreSQL, similar to selecting tables in the batch example above.
The next step is to choose the destination for your data; in our example, we choose Amazon S3. By storing all data in S3, developers, data scientists, and AI/ML modelers can access the raw data immediately to perfect their algorithms and models. This also provides an immutable copy of your source data, and enables you to recreate an exact copy of the source data at any point in time.
When configuring your destination, enter your Amazon S3 bucket name and give your target table a prefix. You can also test the connection to your destination and continue.
Enter the appropriate information on the following screen for destination server address, database name, username, and an AWS secrets name. Using secrets in this manner keeps access credentials and passwords secure. Passwords are never exposed.
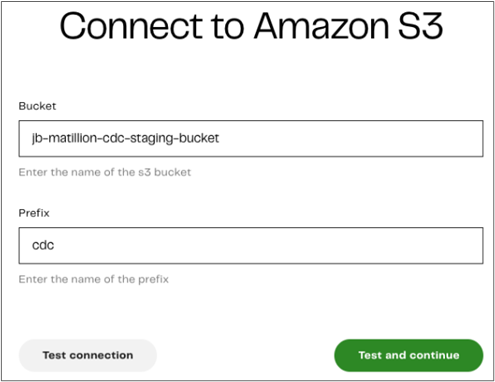
Figure 5 – Enter Amazon S3 bucket and prefix information.
Next, provide a unique CDC pipeline name and execute it. Matillion Data Loader creates all of the code needed for the CDC Agent to access the database source, monitor its change logs or change tables in real-time, and store changed data in Avro format in your S3 bucket destination.
Matillion Data Loader performs an initial load, and then begins loading changed data in near real-time. As a reminder, all data and access credentials are kept secure behind your firewall and never exposed.
Step 4: Transform and Load Data into Amazon Redshift
The final step is to use Matillion ETL to transform the data and load that analytics-ready data into Amazon Redshift. Follow the documentation on Matillion ETL and Shared Jobs. Within the documentation, pay particular attention to the AWS and Amazon Redshift portions for our example.
The shared jobs read data and metadata stored in cloud storage by your CDC pipeline via your CDC Agent. The data is then loaded into target tables in Amazon Redshift. The process can load all tables, the preferred method, or a single table. Schema drift support is also available.
If you need assistance at any time, reach out to Matillion by logging in to Matillion Support.
You can view the status of both your batch and CDC pipelines through the Matillion Data Loader dashboard. In the screenshot below, you can see the CDC pipeline with PostgreSQL source is doing its initial snapshot. Once the initial loads are complete, you’ll see the “active” status for each pipeline.
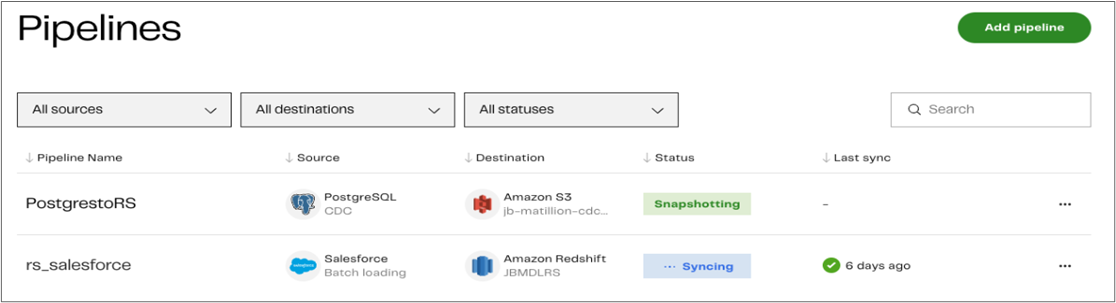
Figure 6 – Matillion Data Loader dashboard.
Summary
Matillion Data Loader enables organizations to move data from a growing number of sources that need faster, simpler access to insights and analytics. Through a single, easy-to-use interface, you can create batch or change data capture (CDC) pipelines in minutes. This makes you, and your data, more productive.
To learn more about Matillion Data Loader, visit the website, register for a weekly demo, or schedule a demo specifically for your organization.
To get started immediately, you can register and use Matillion Data Loader for free at dataloader.matillion.com or through the Matillion Hub.
.

.
Matillion – AWS Partner Spotlight
Matillion is an AWS Partner that delivers modern, cloud-native data integration technology solving individual’s and enterprise’s top business challenges.
Contact Matillion | Partner Overview | AWS Marketplace | Case Studies