AWS Architecture Blog
Category: Technical How-to

Field Notes: How to Back Up a Database with KMS Encryption Using AWS Backup
An AWS security best practice from The 5 Pillars of the AWS Well-Architected Framework is to ensure that data is protected both in transit and at rest. One option is to use SSL/TLS to encrypt data in transit, and use cryptographic keys to encrypt data at rest. To meet your organization’s disaster recovery goals, periodic snapshots of […]
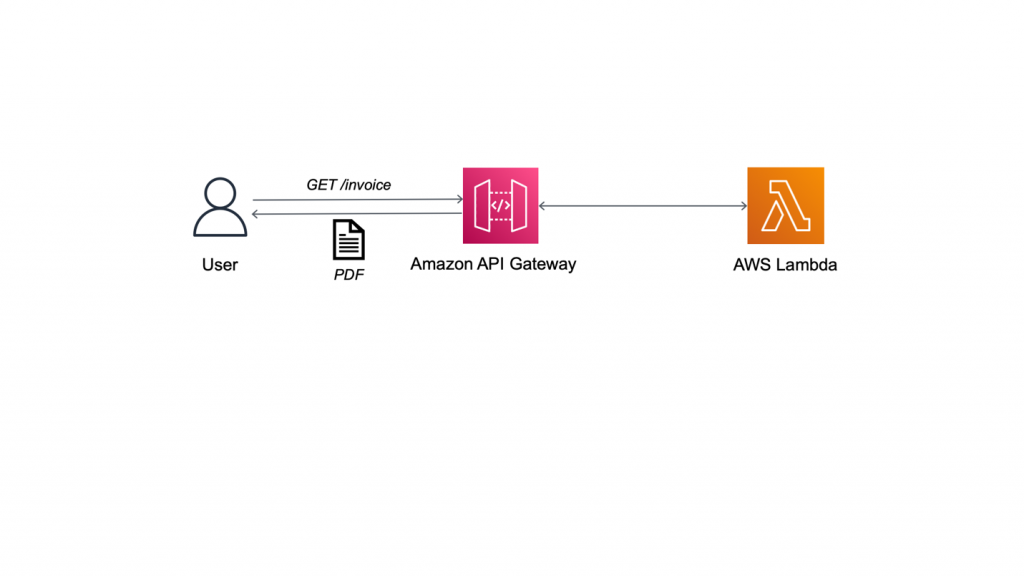
Field Notes: Three Steps to Port Your Containerized Application to AWS Lambda
AWS Lambda support for container images allows porting containerized web applications to run in a serverless environment. This gives you automatic scaling, built-in high availability, and a pay-for-value billing model so you don’t pay for over-provisioned resources. If you are currently using containers, container image support for AWS Lambda means you can use these benefits […]

Field Notes: Building an automated scene detection pipeline for Autonomous Driving – ADAS Workflow
This Field Notes blog post in 2020 explains how to build an Autonomous Driving Data Lake using this Reference Architecture. Many organizations face the challenge of ingesting, transforming, labeling, and cataloging massive amounts of data to develop automated driving systems. In this re:Invent session, we explored an architecture to solve this problem using Amazon EMR, Amazon […]
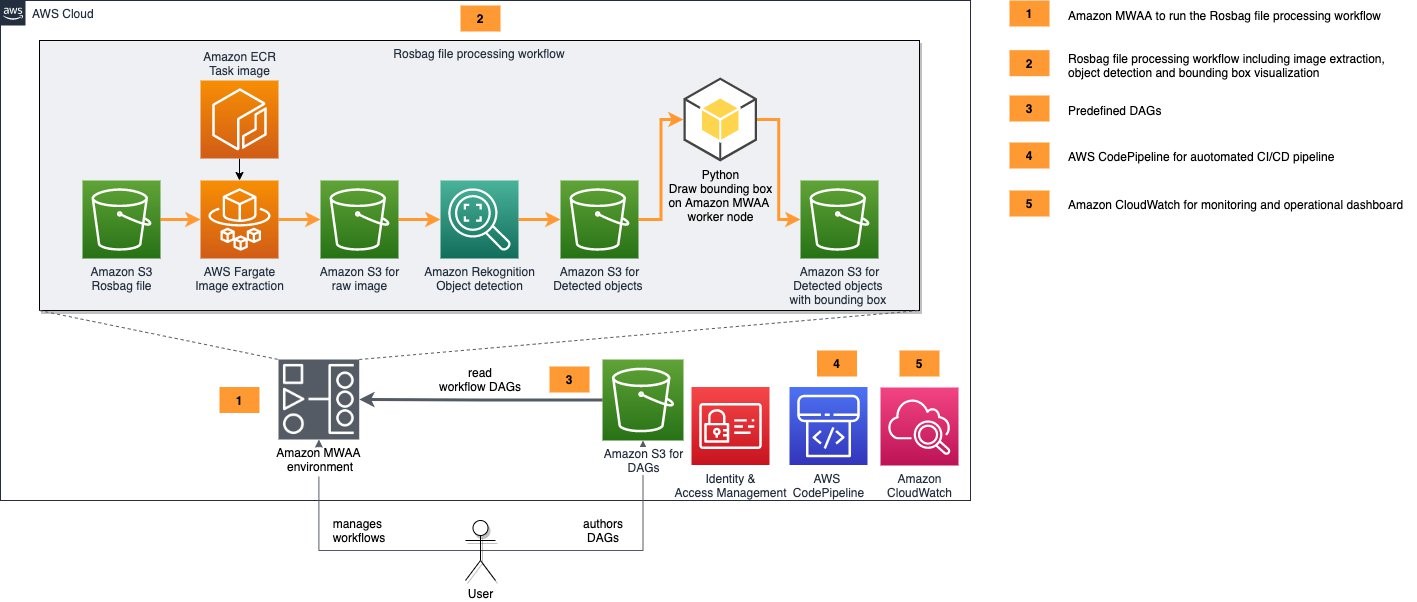
Field Notes: Deploying Autonomous Driving and ADAS Workloads at Scale with Amazon Managed Workflows for Apache Airflow
Cloud Architects developing autonomous driving and ADAS workflows are challenged by loosely distributed process steps along the tool chain in hybrid environments. This is accelerated by the need to create a holistic view of all running pipelines and jobs. Common challenges include: finding and getting access to the data sources specific to your use case, […]

Field Notes: Building an Automated Image Processing and Model Training Pipeline for Autonomous Driving
In this blog post, we demonstrate how to build an automated and scalable data pipeline for autonomous driving. This solution was built with the goal of accelerating the process of analyzing recorded footage and training a model to improve the experience of autonomous driving. We will demonstrate the extraction of images from ROS bag file […]
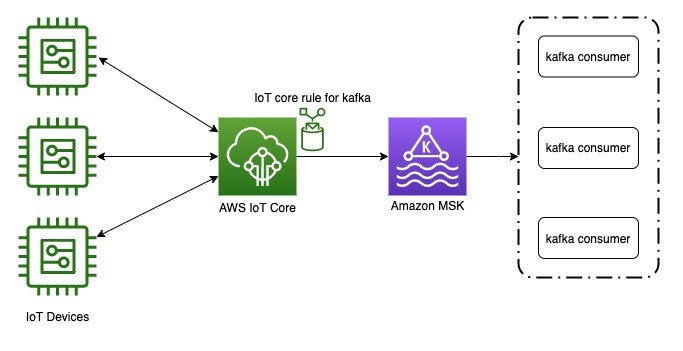
Field Notes: Deliver Messages Using an IoT Rule Action to Amazon Managed Streaming for Apache Kafka
With IoT devices scaling up rapidly, real-time data integration and data processing has become a major challenge. This is why customers often choose Message Queuing Telemetry Transport (MQTT) for message ingestion, and Apache Kafka to build a real-time streaming data pipeline. AWS IoT Core now supports a new IoT rule action to deliver messages from […]

Field Notes: Building a Scalable Real-Time Newsfeed Watchlist Using Amazon Comprehend
One of the challenges businesses have is to constantly monitor information via media outlets and be alerted when a key interest is picked up, such as individual, product, or company information. One way to do this is to scan media and news feeds against a company watchlist. The list may contain personal names, organizations or […]

Field Notes: Build Dynamic IVR Menus with Amazon Connect and AWS Lambda
This post was co-written by Marius Cealera, Senior Partner Solutions Architect at AWS, and Zdenko Estok, Cloud Architect and DevOps Engineer at Accenture. Modern interactive voice response (IVR) systems help customers find answers to their questions through a series of menus, usually relying on the customer to filter and select the right options. Adding more […]

Field Notes: Launch a Fully Configured AWS Deep Learning Desktop with NICE DCV
You want to start quickly when doing deep learning using GPU-activated Elastic Compute Cloud (Amazon EC2) instances in the AWS Cloud. Although AWS provides end-to-end machine learning (ML) in Amazon SageMaker, working at the deep learning frameworks level, the quickest way to start is with AWS Deep Learning AMIs (DLAMIs), which provide preconfigured Conda environments for […]

Field Notes: How Sportradar Accelerated Data Recovery Using AWS Services
This post was co-written by Mithil Prasad, AWS Senior Customer Solutions Manager, Patrick Gryczka, AWS Solutions Architect, Ben Burdsall, CTO at Sportradar and Justin Shreve, Director of Engineering at Sportradar. Ransomware is a type of malware which encrypts data, effectively locking those affected by it out of their own data and requesting a payment to […]