AWS Architecture Blog
Category: Technical How-to

Field Notes: How to Scale Your Networks on Amazon Web Services
As AWS adoption increases throughout an organization, the number of networks and virtual private clouds (VPCs) to support them also increases. Customers can see growth upwards of tens, hundreds, or in the case of the enterprise, thousands of VPCs. Generally, this increase in VPCs is driven by the need to: Simplify routing, connectivity, and isolation […]

Field Notes: How to Prepare Large Text Files for Processing with Amazon Translate and Amazon Comprehend
Biopharmaceutical manufacturing is a highly regulated industry where deviation documents are used to optimize manufacturing processes. Deviation documents in biopharmaceutical manufacturing processes are geographically diverse, spanning multiple countries and languages. The document corpus is complex, with additional requirements for complete encryption. Therefore, to reduce downtime and increase process efficiency, it is critical to automate the […]
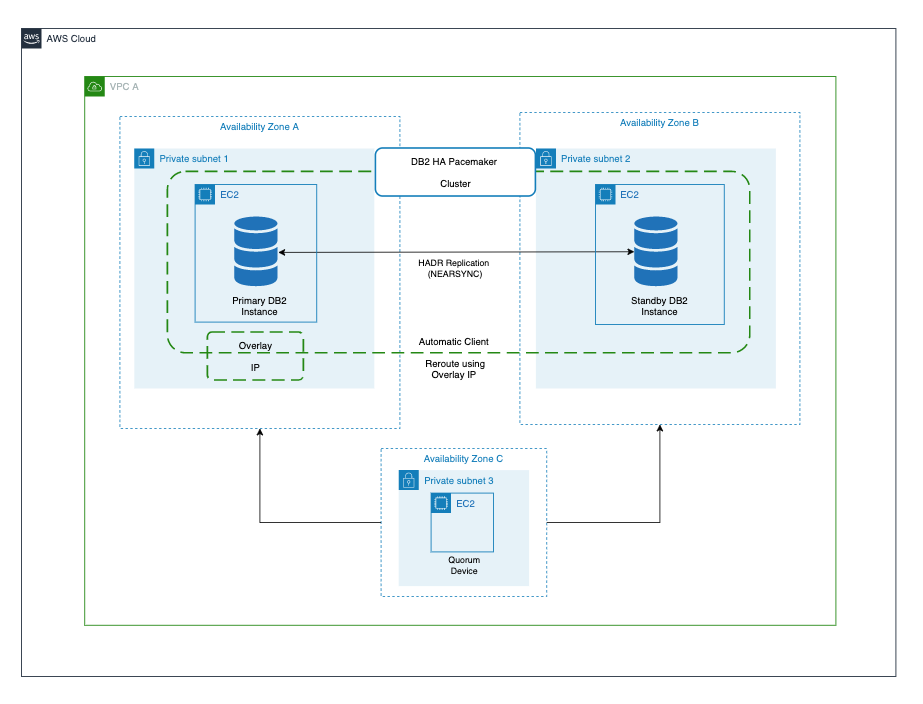
Field Notes: Set Up a Highly Available Database on AWS with IBM Db2 Pacemaker
Many AWS customers need to run mission-critical workloads—like traffic control system, online booking system, and so forth—using the IBM Db2 LUW database server. Typically, these workloads require the right high availability (HA) solution to make sure that the database is available in the event of a host or Availability Zone failure. This HA solution for […]

Field Notes: Tracking Overall Equipment Effectiveness with AWS IoT Analytics and Amazon QuickSight
This post was co-authored with Michael Brown, Senior Solutions Architect, Manufacturing at AWS. Overall equipment effectiveness (OEE) is a measure of how well a manufacturing operation is utilized (facilities, time and material) compared to its full potential, during the periods when it is scheduled to run. Measuring OEE provides a way to obtain actionable insights […]
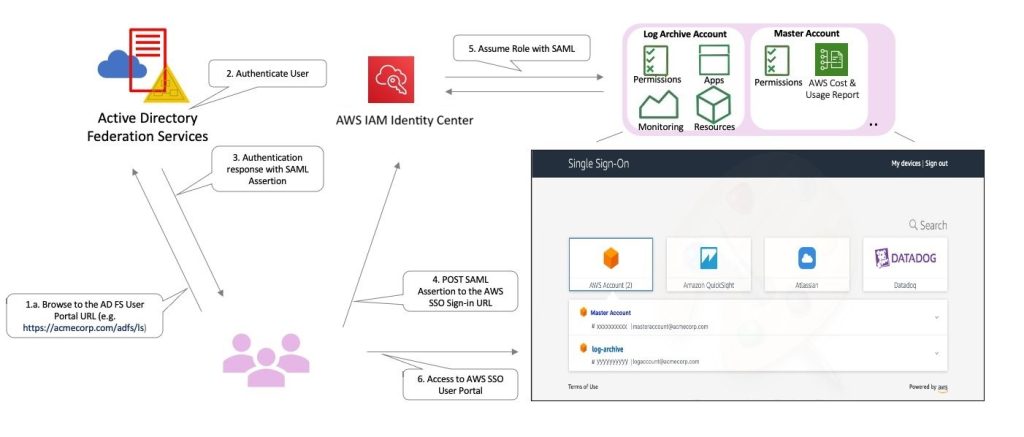
Field Notes: Integrating Active Directory Federation Service with AWS IAM Identity Center
March, 2026: All references of AWS Single Sign-On (AWS SSO), which is now AWS IAM Identity Center, were updated. Enterprises use Active Directory Federation Services (AD FS) with single sign-on, to solve operational and security challenges by allowing the usage of a single set of credentials for multiple applications. This improves the user experience and […]
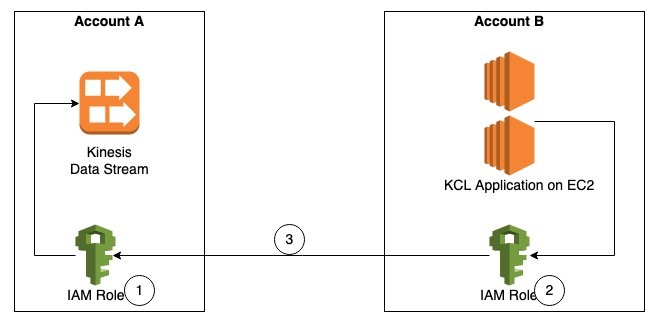
Field Notes: How to Enable Cross-Account Access for Amazon Kinesis Data Streams using Kinesis Client Library 2.x
Businesses today are dealing with vast amounts of real-time data they need to process and analyze to generate insights. Real-time delivery of data and insights enable businesses to quickly make decisions in response to sensor data from devices, clickstream events, user engagement, and infrastructure events, among many others. Amazon Kinesis Data Streams offers a managed […]
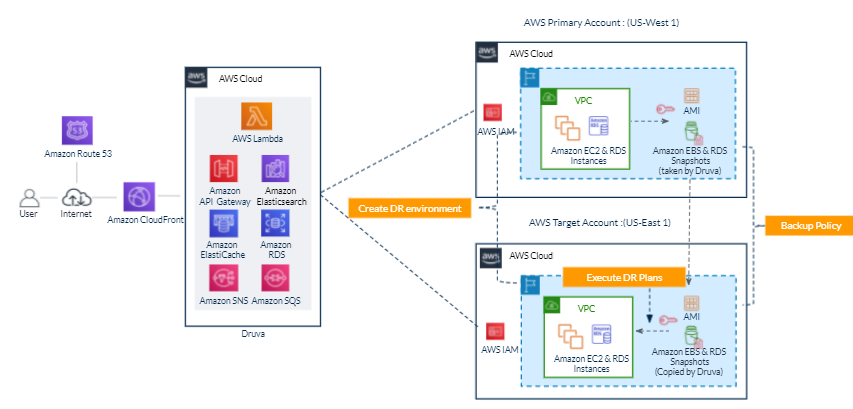
Field Notes: Automate Disaster Recovery for AWS Workloads with Druva
This post was co-written by Akshay Panchmukh, Product Manager, Druva and Girish Chanchlani, Sr Partner Solutions Architect, AWS. The Uptime Institute’s Annual Outage Analysis 2021 report estimated that 40% of outages or service interruptions in businesses cost between $100,000 and $1 million, while about 17% cost more than $1 million. To guard against this, it […]

Field Notes: How to Deploy End-to-End CI/CD in the China Regions Using AWS CodePipeline
This post was co-authored by Ravi Intodia, Senior Technology Architect, Infosys Technologies Ltd, Nirmal Tomar, Principal Consultant, Infosys Technologies Ltd and Ashutosh Pateriya, Solution Architect, AWS. Today’s businesses must contend with fast-changing competitive environments, expanding security needs, and scalability issues. Businesses must find a way to reconcile the need for operational stability with the need […]
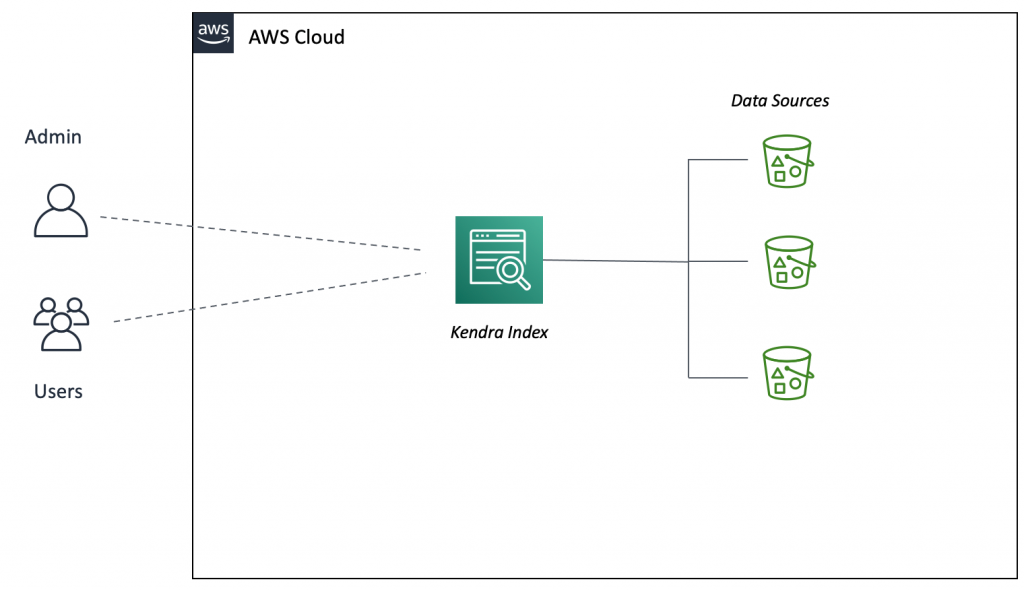
Field Notes: How to Boost Your Search Results Using Relevance Tuning with Amazon Kendra
One challenge enterprises face when they implement an intelligent search solution for their large data sources, is the ability to quickly provide relevant search results. When working with large data sources, not all features or attributes within your data will be equally relevant to all your users. We want to prioritize identifying and boosting specific […]
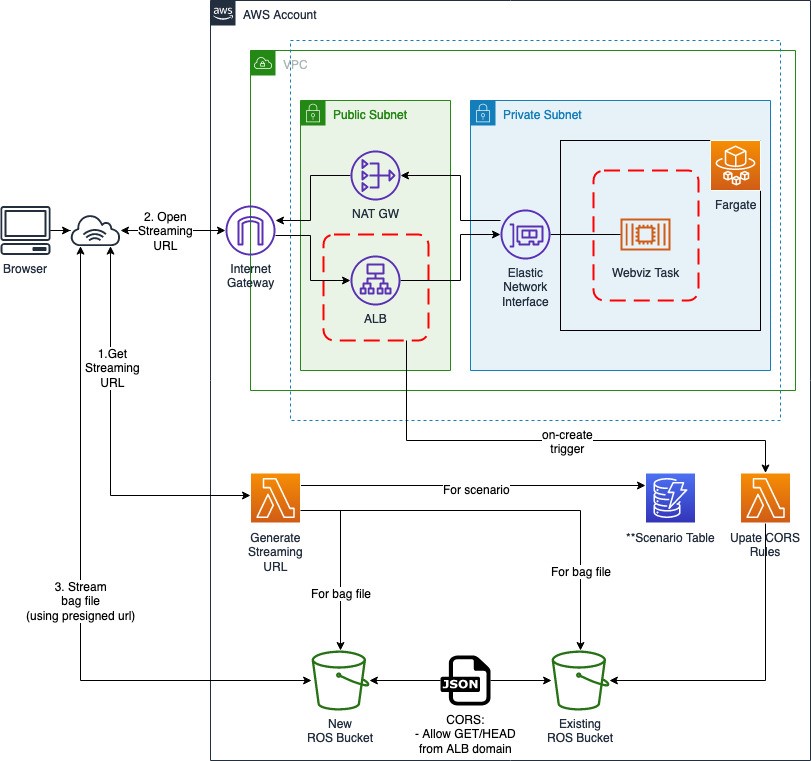
Field Notes: Deploy and Visualize ROS Bag Data on AWS using rviz and Webviz for Autonomous Driving
In the automotive industry, ROS bag files are frequently used to capture drive data from test vehicles configured with cameras, LIDAR, GPS, and other input devices. The data for each device is stored as a topic in the ROS bag file. Developers and engineers need to visualize and inspect the contents of ROS bag files to identify […]