AWS Architecture Blog
Serverless Stream-Based Processing for Real-Time Insights
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
Building on our previous posts regarding messaging patterns and queue-based processing, we now explore stream-based processing and how it helps you achieve low-latency, near real-time data processing in your applications. AWS offers two managed services for streaming, Amazon Kinesis and Amazon Managed Streaming for Apache Kafka (Amazon MSK).
What is streaming data?
At AWS, we define streaming data as data that is emitted at high volume in a continuous, incremental manner with the goal of low-latency processing. Whereas traditional batch-oriented business intelligence would offer insights in retrospect after months, days, or hours have passed, stream-based processing can offer actionable insights in real time. Stream-based processing is commonly used to respond to clickstream events, rapidly ingest various types of logs, and extract, transform, and load (ETL) data in real-time into data lakes and data warehouses.
Amazon Kinesis is the AWS service that makes it easy to collect, process, and analyze such real-time, streaming data with four different capabilities:
- Kinesis Data Streams: Enables ingesting, buffering, and custom processing of your streaming data
- Kinesis Data Firehose: Enables ingesting, transforming, and loading data to Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, or Splunk
- Kinesis Data Analytics: Enables real-time aggregation and filtering processing of streaming data.
- Kinesis Video Streams: Enables streaming video from connected devices to AWS for analytics, machine learning (ML) playback, and other processing.
For this blog post, we focus on Kinesis Data Streams and Kinesis Data Firehose, since both of these services are foundational for streaming, ingestion, buffering, and processing in your streaming data pipeline.
Kinesis Data Streams
Amazon Kinesis Data Streams is a massively scalable service that can continuously capture gigabytes of data per second from hundreds of thousands of sources. Like many distributed systems, Kinesis Data Streams achieves this level of scalability by partitioning or sharding your data where records are simultaneously written to and read from different shards in parallel. All Kinesis Data Streams require allocation of at least one shard and you choose how many shards you want to allocate to a given stream.
When writing to a shard in a Kinesis Data Stream, each shard supports ingestion of up to 1 MB of data per second or 1,000 records written per second. When reading from a shard, each shard supports output of 2 MB of data per second. You choose an initial number of shards to allocate for your Kinesis Data Stream, then can update your shard allocation over time. Increasing your shard allocation enables your application to easily scale from thousands of records to millions of records written per second.
Producing streaming data
Streaming data producers are processes that put records onto a Kinesis stream by calling the putRecord API to write a single record or putRecords API to write multiple records in a single invocation. Common approaches for producing messages including direct use of AWS tools, including:
- AWS SDK, which simplifies authentication and other semantics of invoking AWS service APIs
- Amazon Kinesis Agent, which enables local file/log monitoring and rotation sending in real time
- Amazon Kinesis Producer Library, which simplifies aggregating records into larger payloads to improve throughput.
Additionally, several AWS services natively integrate with Amazon Kinesis as a data producer:
There are also several third-party services that offer native integration as data producers, including:
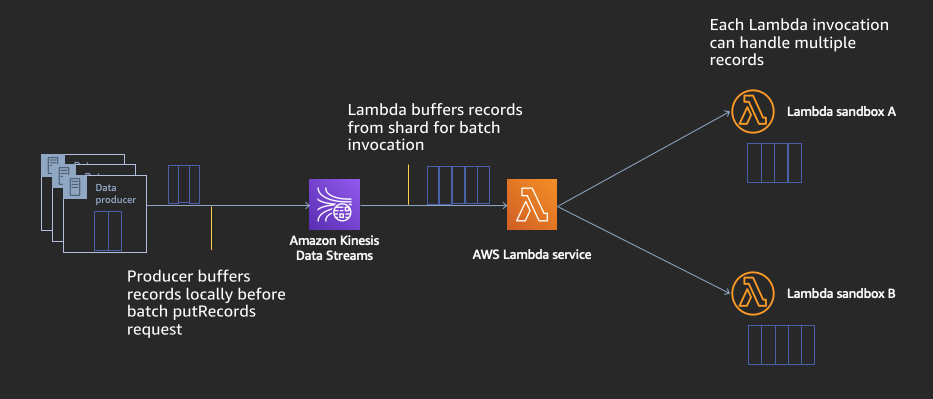
Regardless of the producer service/tool of choice, all data producers put records onto a stream by providing a partition key, stream name, and the data itself, which altogether must not exceed 1 MB in size. The partition key provided is used to determine which shard the data should be written to on the stream. Amazon Kinesis Data Streams offers ordering guarantees and maintain message ordering within a given shard in a stream using sequence numbers to track the unique position of each message sent.

Consuming streaming data
Once records are written to a Kinesis Data Stream, they are buffered in their respective shards for consumption. Unlike queue-based processing, the records are buffered until the data retention period set on the stream elapses, enabling one or more consumers to replay all in the messages in the shards of the stream. If your application must deliver your records to a data lake, data warehouse, Elasticsearch Service cluster, or Splunk, Kinesis Data Firehose can natively deliver your records to the following without needing to write any custom code:
- Amazon S3
- Amazon Redshift
- Amazon Elasticsearch Service
- Splunk
You simply indicate the desired delivery destination and configuration regarding how to batch and deliver the messages. Kinesis Data Firehose can also use your configured S3 desired object naming, Amazon Redshift table name, Amazon Elasticsearch index name, and more.
For custom processing or destinations outside of the Amazon Kinesis Data Firehose supported services above, you will need to write and execute custom code to consume data from the stream. Though you can use the Kinesis Client Library (KCL) to run your own custom processing application on persistent virtual machines or container instances, AWS Lambda offers serverless computing with native event source integration with Amazon Kinesis Data Streams. AWS Lambda as a stream consumer takes care of the operational overhead of reading shards, maintaining record order, check pointing as records are processed, and parallelizing processing.
Serverless stream processing with AWS Lambda
When configured with a Kinesis Stream as its event source, AWS Lambda continuously polls every shard in your stream at no extra charge and only invokes your Lambda code if and when there are messages in the stream. It additionally scales up the number of concurrent executions to parallelize reading all shards of a stream at the same time (and can have multiple executions reading the same shard simultaneously for a higher parallelization factor, if desired). AWS Lambda automatically checkpoints which records were successfully processed and handles retries and any failures automatically according to your desired configuration.
Best of all, there is no additional cost of the Lambda service handling all of these operational needs for you. You only pay for compute time when your function is invoked and messages are available on the stream for processing. You’re able to focus on processing your data with your business logic directly in your code since your records are sent as an array to your Lambda code. There is no additional code to author/manage regarding checkpointing, shard splits/merges, or other complexities.
Conclusion
In this blog, we defined streaming data and explored the Amazon Kinesis service and its various capabilities. We then reviewed the various options available for producing and consuming real-time streaming data with Amazon Kinesis, including using AWS Lambda for serverless streaming data processing. Please refer to the following resources for further learning on AWS streaming data processing:
- Serverless Stream Processing Pipeline Best Practices
- Serverless Streams, Messaging, and APIs – How to Pick the Right Serverless Application Pattern
- Serverless Streaming Data Processing Hands-on Workshop
In this messaging series
Now that you’ve learned about managed services for streaming, be sure to read the three previous posts in this series:
- Introduction to Messaging for Modern Cloud Architecture
- Event-Based Processing for Asynchronous Communication
- Application Integration Using Queues and Messages