AWS News Blog
New – Launch Amazon EMR Clusters in Private Subnets
My colleague Jon Fritz wrote the guest post below to introduce you to an important new feature for Amazon EMR.
— Jeff;
Today we are announcing that Amazon EMR now supports launching clusters in Amazon Virtual Private Cloud (VPC) private subnets, allowing you to quickly, cost-effectively, and securely create fully configured clusters with Hadoop ecosystem applications, Spark, and Presto in the subnet of your choice. With Amazon EMR release 4.2.0 and later, you can launch your clusters in a private subnet with no public IP addresses or attached Internet gateway. You can create a private endpoint for Amazon S3 in your subnet to give your Amazon EMR cluster direct access to data in S3, and optionally create a Network Address Translation (NAT) instance for your cluster to interact with other AWS services, like Amazon DynamoDB and AWS Key Management Service (AWS KMS). For more information on Amazon EMR in VPC, visit the Amazon EMR documentation.
Network Topology for Amazon EMR in a VPC Private Subnet
Before launching an Amazon EMR cluster in a VPC private subnet, please make sure you have the required permissions in your EMR service role and EC2 instance profile, and that you have a route (either through a route from your subnet to an S3 endpoint in your VPC or a NAT/Proxy instance) to the required S3 buckets for your cluster’s initialization. Click here for more information about configuring your subnet.
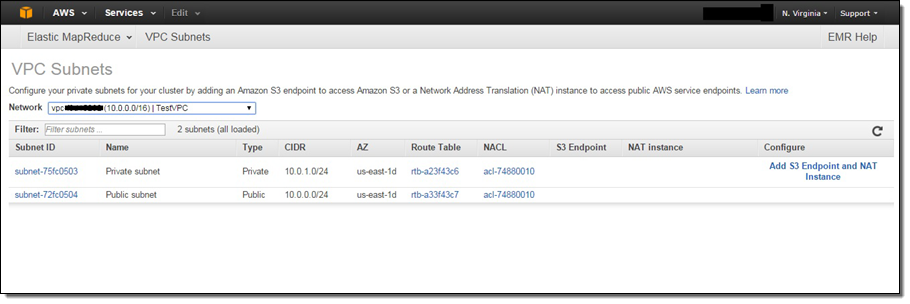
You can use the new VPC Subnets page in the EMR Console to view the VPC subnets available for your clusters, and configure them by adding S3 endpoints and NAT instances:
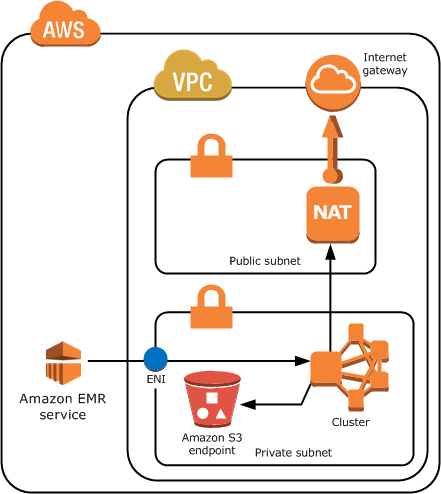
Also, here is a sample network topology for an Amazon EMR cluster in a VPC private subnet with a S3 endpoint and NAT instance. However, if you do not need to use your cluster with AWS services besides S3, you do not need a NAT instance to provide a route to those public endpoints:
Encryption at Rest for Amazon S3 (with EMRFS), HDFS, and Local Filesystem
A typical Hadoop or Spark workload on Amazon EMR utilizes Amazon S3 (using the EMR Filesystem – EMRFS) for input datasets/output results and two filesystems located on your cluster: the Hadoop Distributed Filesystem (HDFS) distributed across your cluster and the Local Filesystem on each instance. Amazon EMR makes it easy to enable encryption for each filesystem, and there are a variety of options depending on your requirements:
- Amazon S3 Using the EMR Filesystem (EMRFS) – EMRFS supports several Amazon S3 encryption options (using AES-256 encryption), allowing Hadoop and Spark on your cluster to performantly and transparently process encrypted data in S3. EMRFS seamlessly works with objects encrypted by S3 Server-Side Encryption or S3 client-side encryption. When using S3 client-side encryption, you can use encryption keys stored in the AWS Key Management Service or in a custom key management system in AWS or on-premises.
- HDFS Transparent Encryption with Hadoop KMS – The Hadoop Key Management Server (KMS) can supply keys for HDFS Transparent Encryption, and it is installed on the master node of your EMR cluster with HDFS. Because encryption and decryption activities are carried out in the client, data is also encrypted in-transit in HDFS. Click here for more information.
- Local Filesystem on Each Node – The Hadoop MapReduce and Spark frameworks utilize the Local Filesystem on each slave instance for intermediate data throughout a workload. You can use a bootstrap action to encrypt the directories used for these intermediates on each node using LUKS.
Encryption in Transit for Hadoop MapReduce and Spark
Hadoop ecosystem applications installed on your Amazon EMR cluster typically have different mechanisms to encrypt data in transit:
- Hadoop MapReduce Shuffle – In a Hadoop MapReduce job, Hadoop will send data between nodes in your cluster in the shuffle phase, which occurs before the reduce phase of the job. You can use SSL to encrypt this process by enabling the Hadoop settings for Encrypted Shuffle and providing the required SSL certificates to each node.
- HDFS Rebalancing – HDFS rebalances by sending blocks between DataNode processes. However, if you use HDFS Transparent Encryption (see above), HDFS never holds unencrypted blocks and the blocks remain encrypted when moved between nodes.
- Spark Shuffle – Spark, like Hadoop MapReduce, also shuffles data between nodes at certain points during a job. Starting with Spark 1.4.0, you can encrypt data in this stage using SASL encryption.
IAM Users and Roles, and Auditing with AWS CloudTrail
You can use Identity and Access Management (IAM) users or federated users to call the Amazon EMR APIs, and limit the API calls that each user can make. Additionally, Amazon EMR requires clusters to be created with two IAM roles, an EMR service role and EC2 instance profile, to limit the permissions of the EMR service and EC2 instances in your cluster, respectively. EMR provides default roles using EMR Named Policies for automatic updates, however, you can also provide custom IAM roles for your cluster. Finally, you can audit the calls your account has made to the Amazon EMR API using AWS CloudTrail.
EC2 Security Groups and Optional SSH Access
Amazon EMR uses two security groups, one for the Master Instance Group and one for slave instance groups (Core and Task Instance Groups), to limit ingress and egress to the instances in your cluster. EMR provides two default security groups, but you can provide your own (assuming they have the necessary ports open for communication between the EMR service and the cluster) or add additional security groups to your cluster. In a private subnet, you can also specify the security group added to the ENI used by the EMR service to communicate with your cluster.
Also, you can optionally add an EC2 key pair to the Master Node of your cluster if you would like to SSH to that node. This allows you to directly interact with the Hadoop applications installed on your cluster, or access web-UIs for applications using a proxy without opening up ports in your Master Security Group.
Hadoop and Spark Authentication and Authorization
Because Amazon EMR installs open source Hadoop ecosystem applications on your cluster, you can also leverage existing security features in these products. You can enable Kerberos authentication for YARN, which will give user-level authentication for applications running on YARN (like Hadoop MapReduce and Spark). Also, you can enable table and SQL-level authorization for Hive using HiveServer2 features, and use LDAP integration to create and authenticate users in Hue.
Run your workloads securely on Amazon EMR
Earlier this year, Amazon EMR was added to the AWS Business Associates Agreement (BAA) for running workloads which process PII data (including eligibility for HIPAA workloads). Amazon EMR also has certification for PCI DSS Level 1, ISO 9001, ISO 27001, and ISO 27018.
Security is a top priority for us and our customers. We are continuously adding new security-related functionality and third-party compliance certifications to Amazon EMR in order to make it even easier to run secure workloads and configure security features in Hadoop, Spark, and Presto.
— Jon Fritz, Senior Product Manager, Amazon EMR
PS – To learn more, read Securely Access Web Interfaces on Amazon EMR Launched in a Private Subnet on the AWS Big Data Blog.