AWS Big Data Blog
Build, secure, and manage data lakes with AWS Lake Formation
A data lake is a centralized store of a variety of data types for analysis by multiple analytics approaches and groups. Many organizations are moving their data into a data lake. In this post, we explore how you can use AWS Lake Formation to build, secure, and manage data lakes.
Traditionally, organizations have kept data in a rigid, single-purpose system, such as an on-premises data warehouse appliance. Similarly, they have analyzed data using a single method, such as predefined BI reports. Moving data between databases or for use with different approaches, like machine learning (ML) or improvised SQL querying, required “extract, transform, load” (ETL) processing before analysis. At best, these traditional methods have created inefficiencies and delays. At worst, they have complicated security.
By contrast, cloud-based data lakes open structured and unstructured data for more flexible analysis. Any amount of data can be aggregated, organized, prepared, and secured by IT staff in advance. Analysts and data scientists can then access it in place with the analytics tools of their choice, in compliance with appropriate usage policies.
Data lakes let you combine analytics methods, offering valuable insights unavailable through traditional data storage and analysis. In a retail scenario, ML methods discovered detailed customer profiles and cohorts on non-personally identifiable data gathered from web browsing behavior, purchase history, support records, and even social media. The exercise showed the deployment of ML models on real-time, streaming, interactive customer data.
Such models could analyze shopping baskets and serve up “next best offers” in the moment, or deliver instant promotional incentives. Marketing and support staff could explore customer profitability and satisfaction in real time and define new tactics to improve sales. Around a data lake, combined analytics techniques like these can unify diverse data streams, providing insights unobtainable from siloed data.
The challenges of building data lakes
Unfortunately, the complex and time-consuming process for building, securing, and starting to manage a data lake often takes months. Even building a data lake in the cloud requires many manual and time-consuming steps:
- Setting up storage.
- Moving, cleaning, preparing, and cataloging data.
- Configuring and enforcing security policies for each service.
- Manually granting access to users.
You want data lakes to centralize data for processing and analysis with multiple services. But organizing and securing the environment requires patience.
Currently, IT staff and architects spend too much time creating the data lake, configuring security, and responding to data requests. They could spend this time acting as curators of data resources, or as advisors to analysts and data scientists. Analysts and data scientists must wait for access to needed data throughout the setup.
The following diagram shows the data lake setup process:
 Setting up storage
Setting up storage
Data lakes hold massive amounts of data. Before doing anything else, you must set up storage to hold all that data. If you are using AWS, configure Amazon S3 buckets and partitions. If you are building the data lake on premises, acquire hardware and set up large disk arrays to store all the data.
Moving data
Connect to different data sources — on-premises and in the cloud — then collect data on IoT devices. Next, collect and organize the relevant datasets from those sources, crawl the data to extract the schemas, and add metadata tags to the catalog. You can use a collection of file transfer and ETL tools:
- AWS Glue
- AWS Database Migration Service (AWS DMS)
- Amazon Kinesis
- Amazon Managed Streaming for Apache Kafka (Amazon MSK) (new)
- AWS Transfer for SFTP service (new)
- AWS Snowball
Cleaning and preparing data
Next, collected data must be carefully partitioned, indexed, and transformed to columnar formats to optimize for performance and cost. You must clean, de-duplicate, and match related records.
Today, organizations accomplish these tasks using rigid and complex SQL statements that perform unreliably and are difficult to maintain. This complex process of collecting, cleaning, and transforming the incoming data requires manual monitoring to avoid errors. Many customers use AWS Glue for this task.
Configuring and enforcing policies
Customers and regulators require that organizations secure sensitive data. Compliance involves creating and applying data access, protection, and compliance policies. For example, you restrict access to personally identifiable information (PII) at the table or column level, encrypt all data, and keep audit logs of who is accessing the data
Today, you can secure data using access control lists on S3 buckets or third-party encryption and access control software. You create and maintain data access, protection, and compliance policies for each analytics service requiring access to the data. For example, if you are running analysis against your data lake using Amazon Redshift and Amazon Athena, you must set up access control rules for each of these services.
Many customers use AWS Glue Data Catalog resource policies to configure and control metadata access to their data. Some choose to use Apache Ranger. But these approaches can be painful and limiting. S3 policies provide at best table-level access. And you must maintain data and metadata policies separately. With Apache Ranger, you can configure metadata access to only one cluster at a time. Also, policies can become wordy as the number of users and teams accessing the data lake grows within an organization.
Making it easy to find data
Users with different needs, like analysts and data scientists, may struggle to find and trust relevant datasets in the data lake. To make it easy for users to find relevant and trusted data, you must clearly label the data in a data lake catalog. Provide users with the ability to access and analyze this data without making requests to IT.
Today, each of these steps involves a lot of manual work. Customer labor includes building data access and transformation workflows, mapping security and policy settings, and configuring tools and services for data movement, storage, cataloging, security, analytics, and ML. With all these steps, a fully productive data lake can take months to implement.
The wide range of AWS services provides all the building blocks of a data lake, including many choices for storage, computing, analytics, and security. In the nearly 13 years that AWS has been operating Amazon S3 with exabytes of data, it’s also become the clear first choice for data lakes. AWS Glue adds a data catalog and server-less transformation capabilities. Amazon EMR brings managed big data processing frameworks like Apache Spark and Apache Hadoop. Amazon Redshift Spectrum offers data warehouse functions directly on data in Amazon S3. Athena brings server-less SQL querying.
With all these services available, customers have been building data lakes on AWS for years. AWS runs over 10,000 data lakes on top of S3, many using AWS Glue for the shared AWS Glue Data Catalog and data processing with Apache Spark.
AWS has learned from the thousands of customers running analytics on AWS that most customers who want to do analytics also want to build a data lake. But many of you want this process to be easier and faster than it is today.
AWS Lake Formation (now generally available)
At AWS re:Invent 2018, AWS introduced Lake Formation: a new managed service to help you build a secure data lake in days. If you missed it, watch Andy Jassy’s keynote announcement. Lake Formation has several advantages:
- Identify, ingest, clean, and transform data: With Lake Formation, you can move, store, catalog, and clean your data faster.
- Enforce security policies across multiple services: After your data sources are set up, you then define security, governance, and auditing policies in one place, and enforce those policies for all users and all applications.
- Gain and manage new insights:With Lake Formation, you build a data catalog that describes available datasets and their appropriate business uses. This catalog makes your users more productive by helping them find the right dataset to analyze.
The following screenshot illustrates Lake Formation and its capabilities.
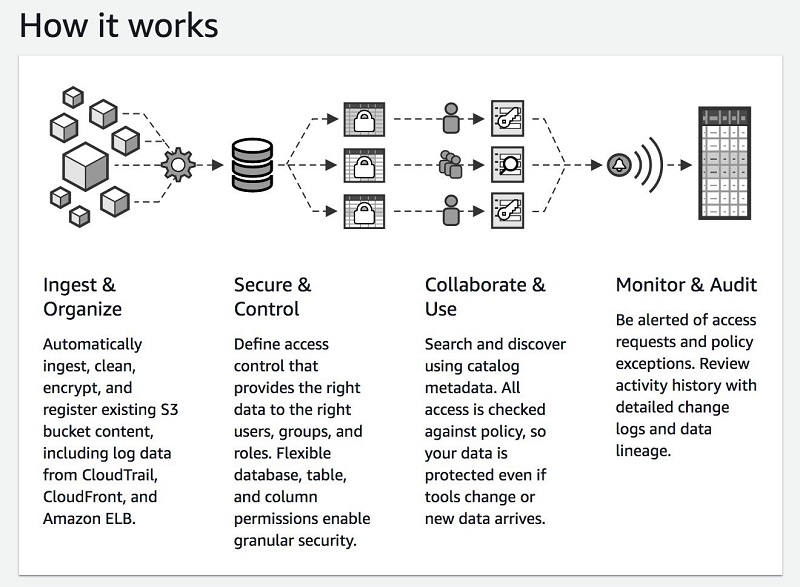
How to create a data lake
S3 forms the storage layer for Lake Formation. If you already use S3, you typically begin by registering existing S3 buckets that contain your data. Lake Formation creates new buckets for the data lake and import data into them. AWS always stores this data in your account, and only you have direct access to it.
There is no lock-in to Lake Formation for your data. Because AWS stores data in standard formats like CSV, ORC, or Parquet, it can be used with a wide variety of AWS or third-party analytics tools.
Lake Formation also optimizes the partitioning of data in S3 to improve performance and reduce costs. The raw data you load may reside in partitions that are too small (requiring extra reads) or too large (reading more data than needed). Lake Formation organizes your data by size, time, or relevant keys to allow fast scans and parallel, distributed reads for the most commonly used queries.
How to load data and catalog metadata
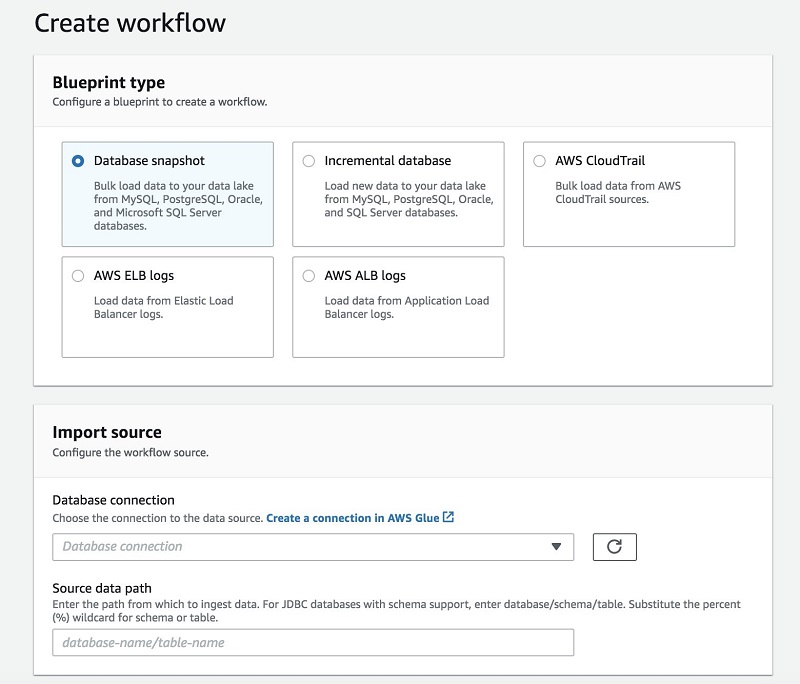
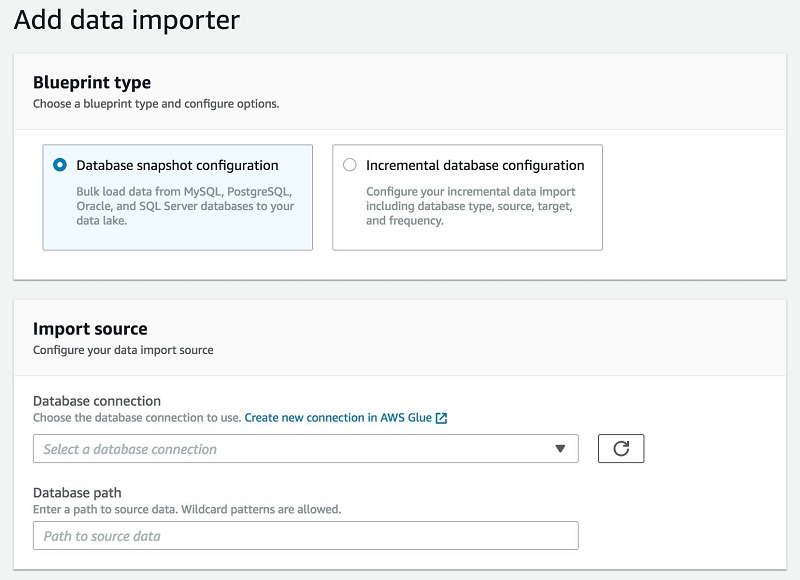
Lake Formation uses the concept of blueprints for loading and cataloging data. You can run blueprints one time for an initial load or set them up to be incremental, adding new data and making it available.
With Lake Formation, you can import data from MySQL, Postgres, SQL Server, MariaDB, and Oracle databases running in Amazon RDS or hosted in Amazon EC2. You can also import from on-premises databases by connecting with Java Database Connectivity (JDBC).
Point Lake Formation to the data source, identify the location to load it into the data lake, and specify how often to load it. Blueprints discovers the source table schema, automatically convert data to the target data format, partition the data based on the partitioning schema, and track data that was already processed. All these actions can be customized.
Blueprints rely on AWS Glue as a support service. AWS Glue crawlers connect and discover the raw data that to be ingested. AWS Glue code generation and jobs generate the ingest code to bring that data into the data lake. Lake Formation uses the same data catalog for organizing the metadata. AWS Glue stitches together crawlers and jobs and allows for monitoring for individual workflows. In these ways, Lake Formation is a natural extension of AWS Glue capabilities.
The following graphics show the Blueprint Workflow and Import screens:
How to transform and prepare data for analysis
In addition to supporting all the same ETL capabilities as AWS Glue, Lake Formation introduces new Amazon ML Transforms. This feature includes a fuzzy logic blocking algorithm that can de-duplicate 400M+ records in less than 2.5 hours, which is magnitudes better than earlier approaches.
To match and de-duplicate your data using Amazon ML Transforms: First, merge related datasets. Amazon ML Transforms divides these sets into training and testing samples, then scans for exact and fuzzy matches. You can provide more data and examples for greater accuracy, putting these into production to process new data as it arrives to your data lake. The partitioning algorithm requires minimal tuning. The confidence level reflects the quality of the grouping, improving on earlier, more improvised algorithms. The following diagram shows this matching and de-duplicating workflow.
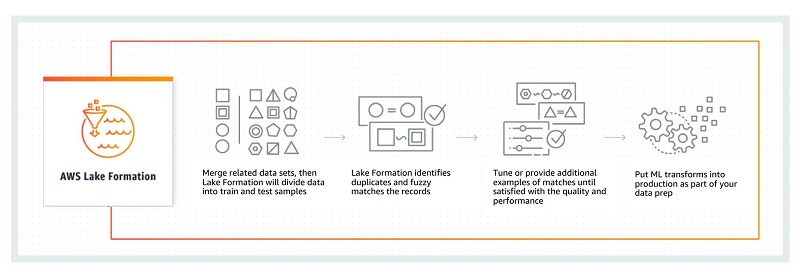
Amazon.com is currently using and vetting Amazon ML Transforms internally, at scale, for retail workloads. Lake Formation now makes these algorithms available to customers, so you can avoid the frustration of creating complex and fragile SQL statements to handle record matching and de-duplication. Amazon ML Transforms help improve data quality before analysis. For more information, see Fuzzy Matching and Deduplicating Data with Amazon ML Transforms for AWS Lake Formation.
How to set access control permissions
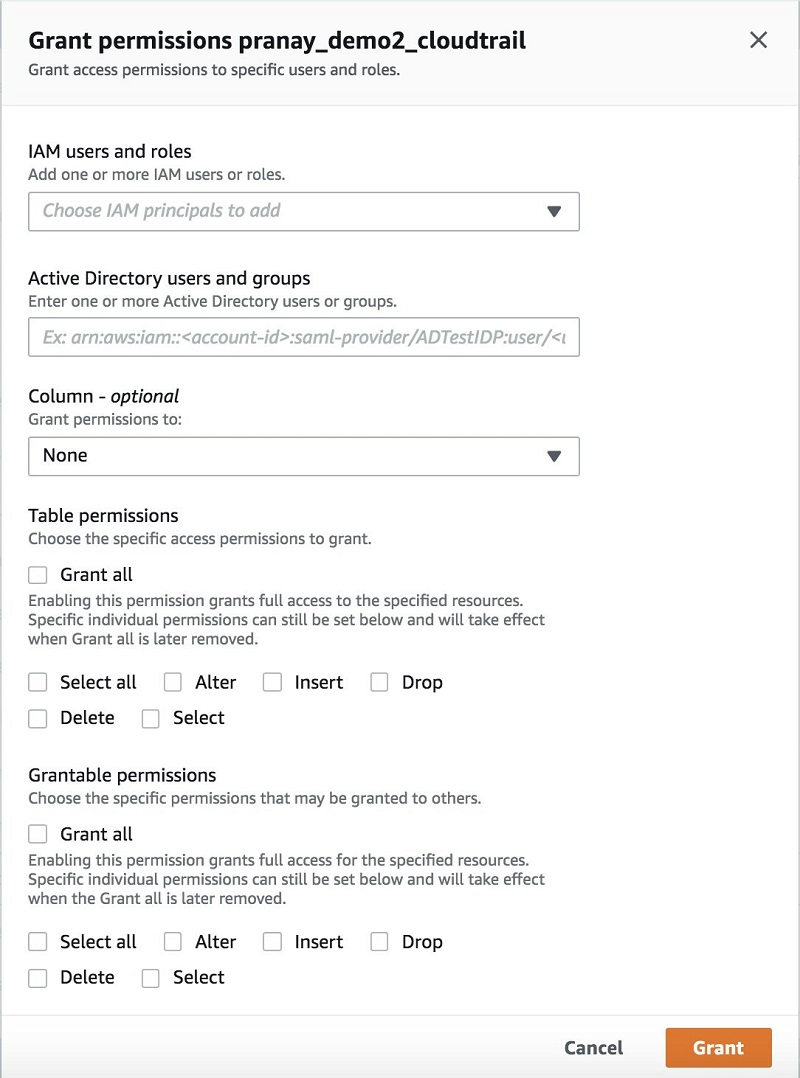
Lake Formation lets you define policies and control data access with simple “grant and revoke permissions to data” sets at granular levels. You can assign permissions to IAM users, roles, groups, and Active Directory users using federation. You specify permissions on catalog objects (like tables and columns) rather than on buckets and objects.
You can easily view and audit all the data policies granted to a user—in one place. Search and view the permissions granted to a user, role, or group through the dashboard; verify permissions granted; and when necessary, easily revoke policies for a user. The following screenshots show the Grant permissions console:

How to make data available for analytics
Lake Formation offers unified, text-based, faceted search across all metadata, giving users self-serve access to the catalog of datasets available for analysis. This catalog includes discovered schemas (as discussed previously) and lets you add attributes like data owners, stewards, and other business-specific attributes as table properties.
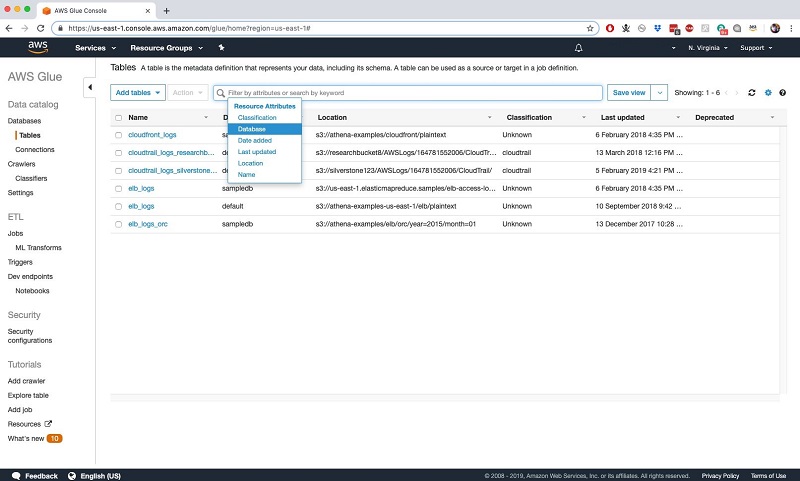
At a more granular level, you can also add data sensitivity level, column definitions, and other attributes as column properties. You can explore data by any of these properties. But access is subject to user permissions. See the following screenshot of the AWS Glue tables tab:
How to monitor activity
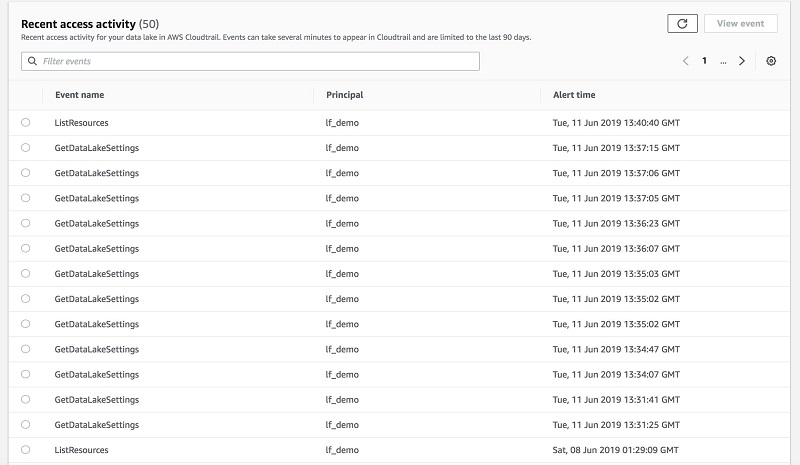
With Lake Formation, you can also see detailed alerts in the dashboard, and then download audit logs for further analytics.
Amazon CloudWatch publishes all data ingestion events and catalog notifications. In this way, you can identify suspicious behavior or demonstrate compliance with rules.
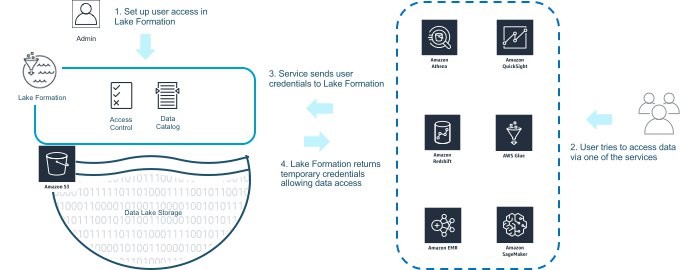
To monitor and control access using Lake Formation, first define the access policies, as described previously. Users who want to conduct analysis access data directly through an AWS analytics service, such as Amazon EMR for Spark, Amazon Redshift, or Athena. Or, they access data indirectly with Amazon QuickSight or Amazon SageMaker.
A service forwards the user credentials to Lake Formation for the validation of access permissions. Then Lake Formation returns temporary credentials granting access to the data in S3, as shown in the following diagrams. After a user gains access, actual reads and writes of data operate directly between the analytics service and S3. This approach removes the need for an intermediary in the critical data-processing path.
The following screenshot and diagram show how to monitor and control access using Lake Formation.
Conclusion
With just a few steps, you can set up your data lake on S3 and start ingesting data that is readily queryable. To get started, go to the Lake Formation console and add your data sources. Lake Formation crawls those sources and moves the data into your new S3 data lake.
Lake Formation can automatically lay out the data in S3 partitions; change it into formats for faster analytics, like Apache Parquet and ORC; and increase data quality through machine-learned record matching and de-duplication.
From a single dashboard, you can set up all the permissions for your data lake. Those permissions are implemented for every service accessing this data – including analytics and ML services (Amazon Redshift, Athena, and Amazon EMR for Apache Spark workloads). Lake Formation saves you the hassle of redefining policies across multiple services and provides consistent enforcement of and compliance with those policies.
Learn how to start using AWS Lake Formation.
About the Authors
 Nikki Rouda is the principal product marketing manager for data lakes and big data at AWS. Nikki has spent 20+ years helping enterprises in 40+ countries develop and implement solutions to their analytics and IT infrastructure challenges. Nikki holds an MBA from the University of Cambridge and an ScB in geophysics and math from Brown University.
Nikki Rouda is the principal product marketing manager for data lakes and big data at AWS. Nikki has spent 20+ years helping enterprises in 40+ countries develop and implement solutions to their analytics and IT infrastructure challenges. Nikki holds an MBA from the University of Cambridge and an ScB in geophysics and math from Brown University.
 Prajakta Damle is a Principle Product Manager at Amazon Web Services.
Prajakta Damle is a Principle Product Manager at Amazon Web Services.