AWS Big Data Blog
Category: Amazon Kinesis
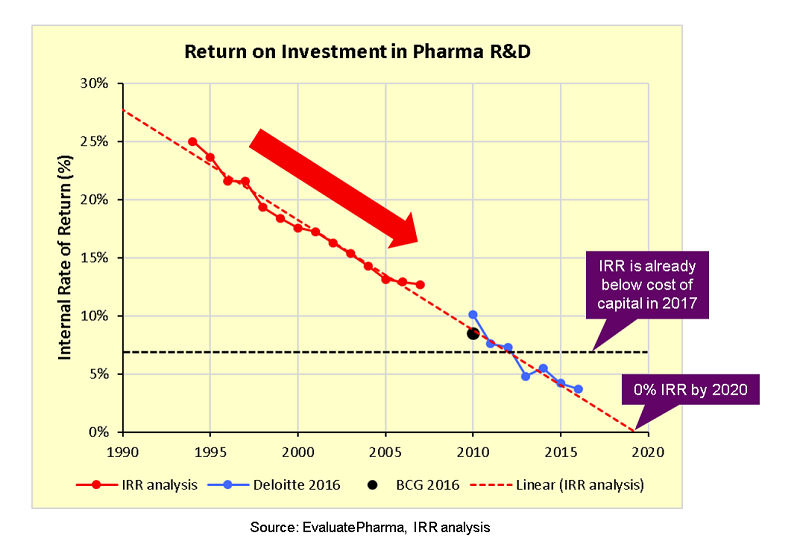
Improve clinical trial outcomes by using AWS technologies
We are living in a golden age of innovation, where personalized medicine is making it possible to cure diseases that we never thought curable. Digital medicine is helping people with diseases get healthier, and we are constantly discovering how to use the body’s immune system to target and eradicate cancer cells. According to a report […]

Create real-time clickstream sessions and run analytics with Amazon Kinesis Data Analytics, AWS Glue, and Amazon Athena
April 2024: The content of this post is no longer relevant and deprecated. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Clickstream events are small pieces of data that are generated continuously with high speed […]
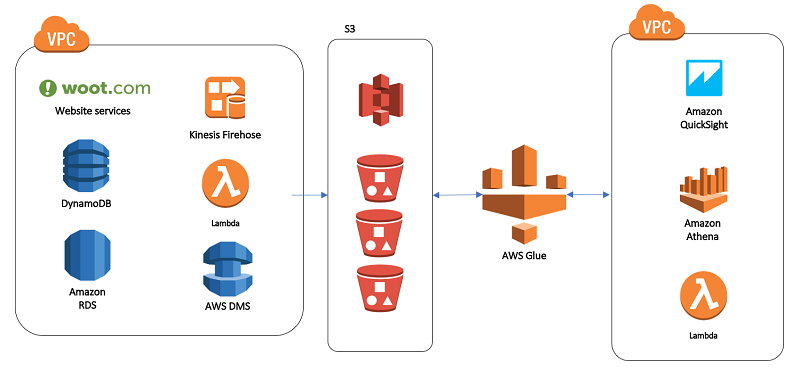
Our data lake story: How Woot.com built a serverless data lake on AWS
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. In this post, we talk about designing a cloud-native data warehouse as a replacement for our legacy data warehouse built on a relational database. At the beginning of the design process, the […]
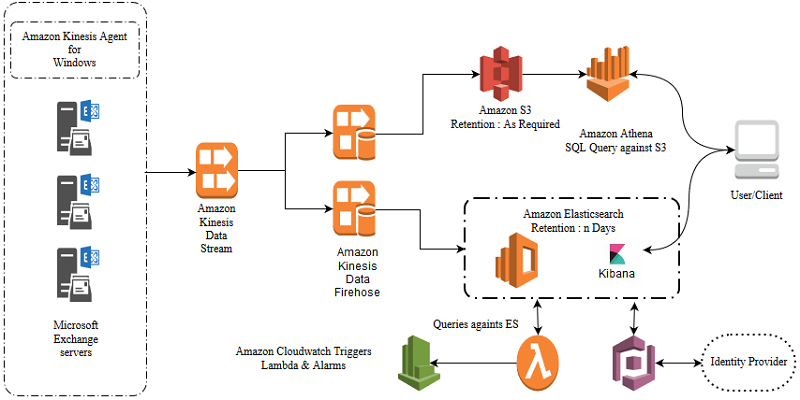
Manage centralized Microsoft Exchange Server logs using Amazon Kinesis Agent for Windows
This blog post discusses an efficient architecture to stream, analyze, and store Microsoft Exchange Server logs. For frequent queries and operational analytics, we use Amazon Elasticsearch Service (Amazon ES) and Kibana for real-time visualization.

Scale Amazon Kinesis Data Streams with AWS Application Auto Scaling
Recently, AWS launched a new feature of AWS Application Auto Scaling that let you define scaling policies that automatically add and remove shards to an Amazon Kinesis Data Stream. For more detailed information about this feature, see the Application Auto Scaling GitHub repository. As your streaming information increases, you require a scaling solution to accommodate […]

Your guide to Amazon Kinesis sessions, chalk talks, and workshops at AWS re:Invent 2018
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. AWS re:Invent 2018 is almost here! This post includes a list of Amazon Kinesis sessions, chalk talks, and workshops at AWS re:Invent 2018. You can choose the link next to each session description for the […]
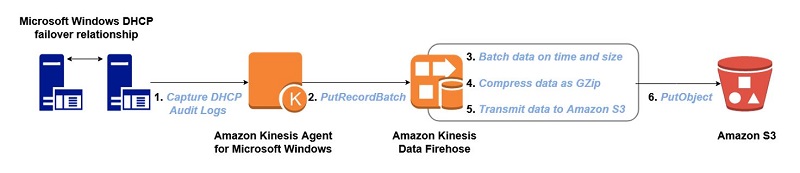
Turn Windows DHCP Server logs into actionable metrics using Amazon Kinesis Agent for Windows
Understanding Windows system and service health on a global scale is challenging. You capture server log data, and then analyze and manipulate the data in real time to create actionable telemetry insights. Amazon Kinesis Agent for Microsoft Windows makes it efficient to ingest Windows server log data into your AWS ecosystem for analysis. This blog […]
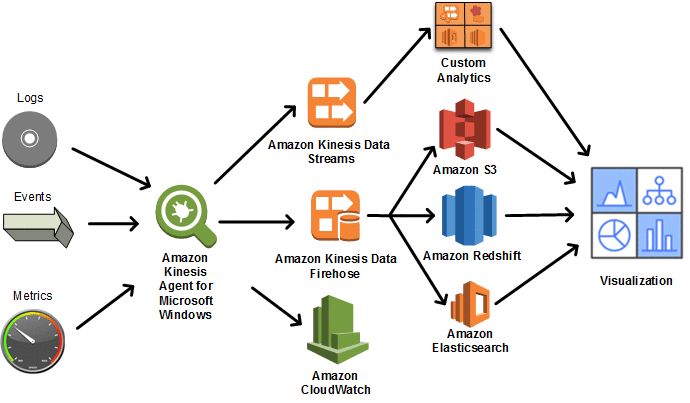
Collect, parse, transform, and stream Windows events, logs, and metrics using Amazon Kinesis Agent for Microsoft Windows
A complete data pipeline that includes Amazon Kinesis Agent for Microsoft Windows (KA4W) can help you analyze and monitor the performance, security, and availability of Windows-based services. You can build near-real-time dashboards and alarms for your Windows services. You can also use visualization and business intelligence tools such as Amazon Athena, Kibana, Amazon QuickSight, and […]

Analyze and visualize your VPC network traffic using Amazon Kinesis and Amazon Athena
In this blog post, we describe the complete solution for collecting, analyzing, and visualizing VPC flow log data. In addition, we created a single AWS CloudFormation template that lets you efficiently deploy this solution into your own account.

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 2
August 2024: This post was reviewed and updated for accuracy. In part 1 of this series, we demonstrated how to build a data pipeline in support of a data lake. We used key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we discuss […]