AWS Big Data Blog
Category: Analytics

Introducing new dashboard experience on Amazon QuickSight
This post was last updated August 2022, to include new experiences such as Analysis and Embedding. Amazon QuickSight launches the new look and feel for your dashboards. In this post, we will walk through the changes and improvements introduced with the new look. The new dashboard experience includes the following improvements: Simplified toolbar Discoverable visual […]

Use a linear learner algorithm in Amazon Redshift ML to solve regression and classification problems
July 2024: This post was reviewed and updated for accuracy. Amazon Redshift is a fast, petabyte-scale cloud data warehouse delivering the best price–performance. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Amazon Redshift ML, powered by Amazon SageMaker, makes it easy for SQL […]
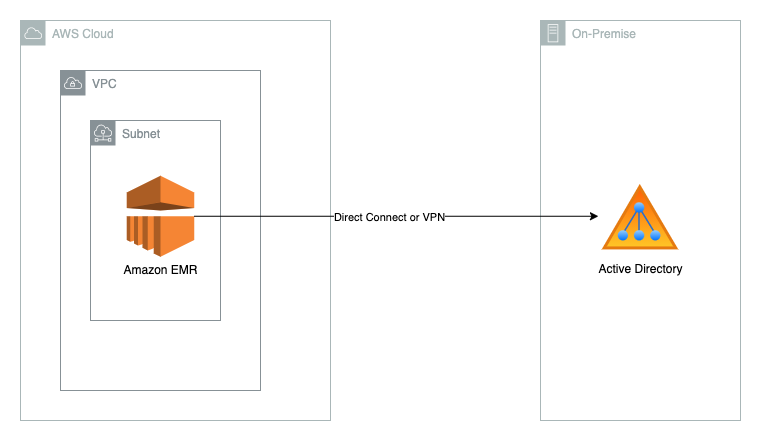
Deep dive into Amazon EMR Kerberos authentication integrated with Microsoft Active Directory
Many of our customers that use Amazon EMR as their big data platform need to integrate with their existing Microsoft Active Directory (AD) for user authentication. This integration requires the Kerberos daemon of Amazon EMR to establish a trusted connection with an AD domain, which involves a lot of moving pieces and can be difficult […]

Federate single sign-on access to Amazon Redshift query editor v2 with Okta
Amazon Redshift query editor v2 is a web-based SQL client application that you can use to author and run queries on your Amazon Redshift data warehouse. You can visualize query results with charts and collaborate by sharing queries with members of your team. You can use query editor v2 to create databases, schemas, tables, and […]
Federate access to Amazon Redshift query editor V2 with Active Directory Federation Services (AD FS): Part 3
In the first post of this series, Federate access to your Amazon Redshift cluster with Active Directory Federation Services (AD FS): Part 1, you set up Microsoft Active Directory Federation Services (AD FS) and Security Assertion Markup Language (SAML) based authentication and tested the SAML federation using a web browser. In Part 2, you learned […]

How Paytm modernized their data pipeline using Amazon EMR
This post was co-written by Rajat Bhardwaj, Senior Technical Account Manager at AWS and Kunal Upadhyay, General Manager at Paytm. Paytm is India’s leading payment platform, pioneering the digital payment era in India with 130 million active users. Paytm operates multiple lines of business, including banking, digital payments, bill recharges, e-wallet, stocks, insurance, lending and […]
Analyze Amazon SES events at scale using Amazon Redshift
Email is one of the most important methods for business communication across many organizations. It’s also one of the primary methods for many businesses to communicate with their customers. With the ever-increasing necessity to send emails at scale, monitoring and analysis has become a major challenge. Amazon Simple Email Service (Amazon SES) is a cost-effective, […]

Build a big data Lambda architecture for batch and real-time analytics using Amazon Redshift
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. With real-time information about customers, products, and applications in hand, organizations can take action as events happen in their business application. For example, you can prevent financial fraud, deliver personalized offers, and […]

Simplify your ETL and ML pipelines using the Amazon Athena UNLOAD feature
Many organizations prefer SQL for data preparation because they already have developers for extract, transform, and load (ETL) jobs and analysts preparing data for machine learning (ML) who understand and write SQL queries. Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using […]
Use Amazon Kinesis Data Firehose to extract data insights with Coralogix
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This is a guest blog post co-written by Tal Knopf at Coralogix. Digital data is expanding exponentially, and the existing limitations to store and analyze it are constantly being challenged and overcome. […]