AWS Big Data Blog
Category: AWS Quest
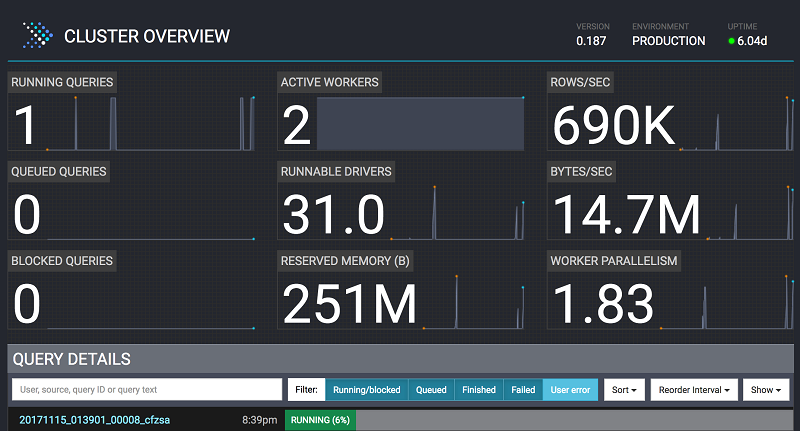
Easily manage table metadata for Presto running on Amazon EMR using the AWS Glue Data Catalog
In this post, we will explore how the AWS Glue Data Catalog addresses discoverability and manageability for table metadata for Presto on Amazon EMR.

Best Practices for Running Apache Kafka on AWS
The best practices described in this post are based on our experience in running and operating large-scale Kafka clusters on AWS for more than two years. Our intent for this post is to help AWS customers who are currently running Kafka on AWS, and also customers who are considering migrating on-premises Kafka deployments to AWS.
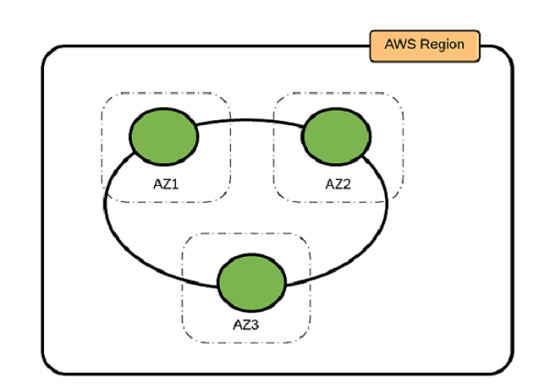
Best Practices for Running Apache Cassandra on Amazon EC2
In this post, we outline three Cassandra deployment options, as well as provide guidance about determining the best practices for your use case.

Top 9 Best Practices for High-Performance ETL Processing Using Amazon Redshift
When migrating from a legacy data warehouse to Amazon Redshift, it is tempting to adopt a lift-and-shift approach, but this can result in performance and scale issues long term. This post guides you through the following best practices for ensuring optimal, consistent runtimes for your ETL processes.