AWS Big Data Blog
Category: Compute

Increase Amazon Elasticsearch Service performance by upgrading to Graviton2
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Amazon OpenSearch Service supports multiple instance types based on your use case. In 2021, AWS announced general purpose (M6g), compute optimized (C6g), and memory optimized (R6g, R6gd) instance types for Amazon OpenSearch Service version 7.9 or later powered by AWS […]

Manage and process your big data workflows with Amazon MWAA and Amazon EMR on Amazon EKS
Many customers are gathering large amount of data, generated from different sources such as IoT devices, clickstream events from websites, and more. To efficiently extract insights from the data, you have to perform various transformations and apply different business logic on your data. These processes require complex workflow management to schedule jobs and manage dependencies […]

Estimate Amazon EC2 Spot Instance cost savings with AWS Glue DataBrew, AWS Glue, and Amazon QuickSight
AWS provides many ways to optimize your workloads and save on costs. For example, services like AWS Cost Explorer and AWS Trusted Advisor provide cost savings recommendations to help you optimize your AWS environments. However, you may also want to estimate cost savings when comparing Amazon Elastic Compute Cloud (Amazon EC2) Spot to On-Demand Instances. […]
Build a serverless tracking pixel solution in AWS
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Let’s describe the typical use case where a tracking pixel solution, also known as a web beacon, might help you: Analyzing web traffic is critical to understanding […]

Automate dynamic mapping and renaming of column names in data files using AWS Glue: Part 1
A common challenge ETL and big data developers face is working with data files that don’t have proper name header records. They’re tasked with renaming the columns of the data files appropriately so that downstream application and mappings for data load can work seamlessly. One example use case is while working with ORC files and […]

Automate dynamic mapping and renaming of column names in data files using AWS Glue: Part 2
In Part 1 of this two-part post, we looked at how we can create an AWS Glue ETL job that is agnostic enough to rename columns of a data file by mapping to column names of another file. The solution focused on using a single file that was populated in the AWS Glue Data Catalog […]

Build a DataOps platform to break silos between engineers and analysts
Organizations across the globe are striving to provide a better service to internal and external stakeholders by enabling various divisions across the enterprise, like customer success, marketing, and finance, to make data-driven decisions. Data teams are the key enablers in this process, and usually consist of multiple roles, such as data engineers and analysts. However, […]
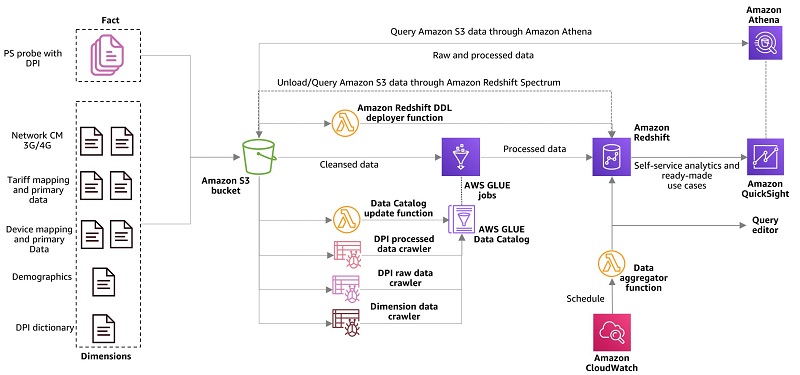
Data monetization and customer experience optimization using telco data assets: Part 2
Part 1 of this series explains the importance of building and implementing a customer experience (CX) management and data monetization strategy for telecom service providers (TSPs), and the major challenges driving these initiatives. It also includes an AWS CloudFormation template to set up a demonstration of the solution using AWS services. It covers transforming and enriching […]

Setting up automated data quality workflows and alerts using AWS Glue DataBrew and AWS Lambda
Proper data management is critical to successful, data-driven decision-making. An increasingly large number of customers are adopting data lakes to realize deeper insights from big data. As part of this, you need clean and trusted data in order to gain insights that lead to improvements in your business. As the saying goes, garbage in is […]

Building a scalable streaming data processor with Amazon Kinesis Data Streams on AWS Fargate
Data is ubiquitous in businesses today, and the volume and speed of incoming data are constantly increasing. To derive insights from data, it’s essential to deliver it to a data lake or a data store and analyze it. Real-time or near-real-time data delivery can be cost prohibitive, therefore an efficient architecture is key for processing, […]