AWS Big Data Blog
Category: Amazon RDS
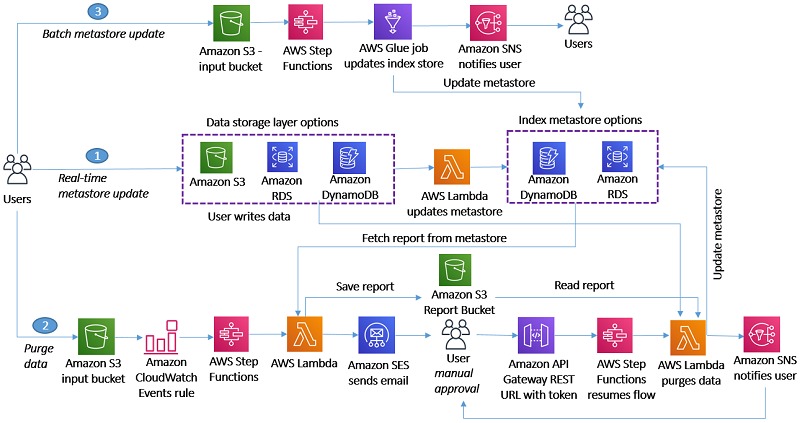
How to delete user data in an AWS data lake
General Data Protection Regulation (GDPR) is an important aspect of today’s technology world, and processing data in compliance with GDPR is a necessity for those who implement solutions within the AWS public cloud. One article of GDPR is the “right to erasure” or “right to be forgotten” which may require you to implement a solution […]

Integrating AWS Lake Formation with Amazon RDS for SQL Server
This post shows how to ingest data from Amazon RDS into a data lake on Amazon S3 using Lake Formation blueprints and how to have column-level access controls for running SQL queries on the extracted data from Amazon Athena.
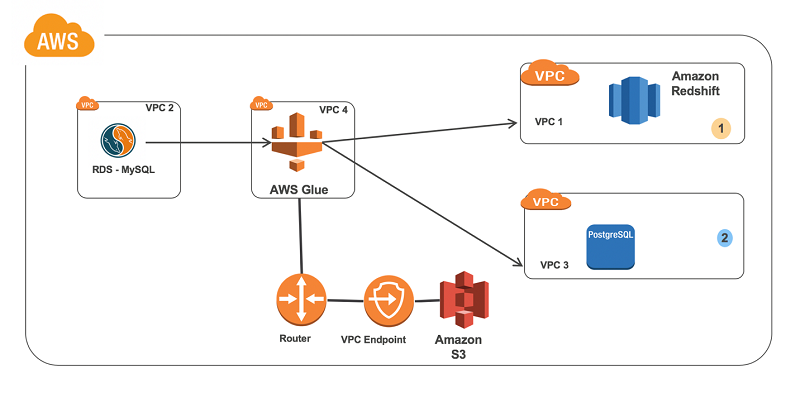
Connect to and run ETL jobs across multiple VPCs using a dedicated AWS Glue VPC
In this blog post, we’ll go through the steps needed to build an ETL pipeline that consumes from one source in one VPC and outputs it to another source in a different VPC. We’ll set up in multiple VPCs to reproduce a situation where your database instances are in multiple VPCs for isolation related to security, audit, or other purposes.

Migrate RDBMS or On-Premise data to EMR Hive, S3, and Amazon Redshift using EMR – Sqoop
This blog post shows how our customers can benefit by using the Apache Sqoop tool. This tool is designed to transfer and import data from a Relational Database Management System (RDBMS) into AWS – EMR Hadoop Distributed File System (HDFS), transform the data in Hadoop, and then export the data into a Data Warehouse (e.g. in Hive or Amazon Redshift).
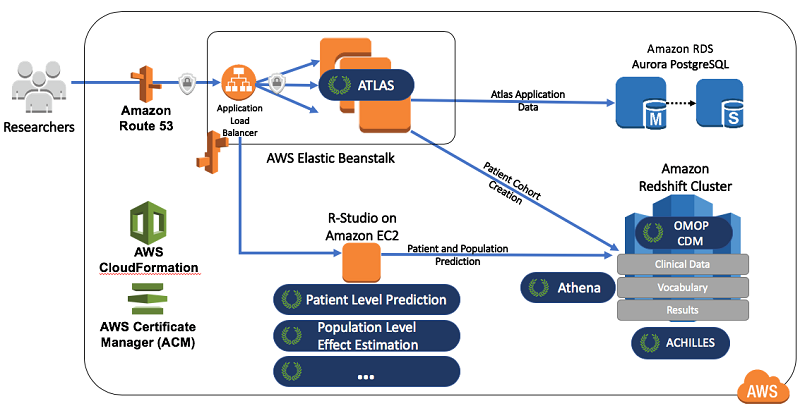
Create data science environments on AWS for health analysis using OHDSI
This blog post demonstrates how to combine some of the OHDSI projects (Atlas, Achilles, WebAPI, and the OMOP Common Data Model) with AWS technologies. By doing so, you can quickly and inexpensively implement a health data science and informatics environment.

JOIN Amazon Redshift AND Amazon RDS PostgreSQL WITH dblink
Tony Gibbs is a Solutions Architect with AWS (Update: This blog post has been translated into Japanese) When it comes to choosing a SQL-based database in AWS, there are many options. Sometimes it can be difficult to know which one to choose. For example, when would you use Amazon Aurora instead of Amazon RDS PostgreSQL […]