AWS Big Data Blog
Create cross-account and cross-region AWS Glue connections
November 2024: This post was reviewed and updated for accuracy.
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data for analytics. AWS Glue uses connections to access certain types of source and target data stores, as described in the AWS Glue documentation.
By default, you can use AWS Glue to create connections to data stores in the same AWS account and AWS Region as the one where you have AWS Glue resources. In this blog post, we describe how to access Amazon Redshift in an AWS Region different from the one where you have AWS Glue resources.
AWS Glue connections
AWS Glue uses a connection to crawl and catalog a data store’s metadata in the AWS Glue Data Catalog, as the documentation describes. AWS Glue ETL jobs also use connections to connect to source and target data stores. AWS Glue supports connections to Amazon Redshift, Amazon RDS, and JDBC data stores.
A connection contains the properties needed by AWS Glue to access a data store. These properties might include connection information such as user name and password, data store subnet IDs, and security groups.
If the data store is located inside an Amazon VPC, AWS Glue uses the VPC subnet ID and security group ID connection properties to set up elastic network interfaces in the VPC containing the data store. Doing this enables ETL jobs and crawlers to connect securely to the data store in the VPC.
AWS Glue can create this elastic network interface setup if the VPC containing the data store is in the same account and AWS Region as the AWS Glue resources. The security groups specified in a connection’s properties are applied on each of the network interfaces. The security group rules and network ACLs associated with the subnet control network traffic through the subnet. Correct rules for allowing outbound traffic through the subnet ensure that AWS Glue can establish network connectivity with all subnets in the VPC containing the data store, and therefore access the source or target data store.
VPC components can be interlinked only if they are present in the same AWS Region. Therefore, AWS Glue cannot create the elastic network interfaces inside a VPC in another region. If the VPC containing the data store is in another region, you have to add the network routes and create additional network interfaces which allow network interfaces set up by AWS Glue to establish network connectivity with the data store.
In this blog post, we will describe two different ways to configure the networking routes and interfaces to give AWS Glue access to Amazon Redshift in an AWS Region different from the one with your AWS Glue resources. In our example, we connect AWS Glue, located in Region A, to an Amazon Redshift data warehouse located in Region B.
Option 1: Connecting AWS Glue to Amazon Redshift in a public subnet using a NAT gateway.
Note: The examples here assume that the Amazon Redshift cluster is in a different AWS Region, but belongs to the same account. In this setup, the glue resources are in a private subnet in the glue VPC while the redshift cluster is in a private subnet in the Redshift VPC.
Setting up VPC components for AWS Glue
AWS Glue requires a VPC with networking routes to the data stores to which it connects. In our solution, the security groups and route tables are configured to enable elastic network interfaces set up by AWS Glue in a private subnet to reach the internet or connect to data stores outside the VPC. The following diagram shows the necessary components and the network traffic flow.
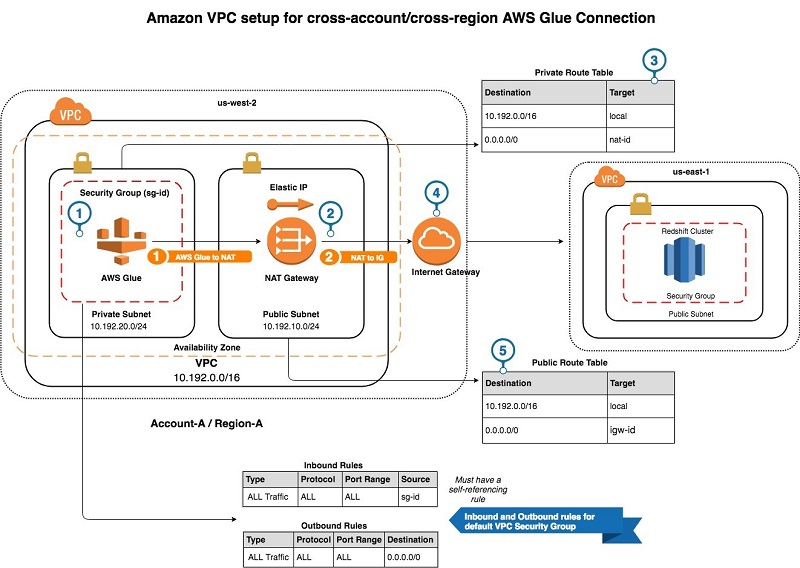
![]() Required components for VPC setup:
Required components for VPC setup:
- AWS Glue resources in a private subnet in Region A.
- A NAT gateway with an Elastic IP address attached to it in a public subnet in Region A.
- A private route table containing a route allowing outbound network traffic from the private subnet to pass through the NAT gateway.
- An internet gateway in Region A.
- A public route table with a route allowing outbound network traffic from the public subnet to pass through the internet gateway.
Note: We must update the default security group of the VPC to include a self-referencing inbound rule and an outbound rule to allow all traffic from all ports. Later in the example, we attach this security group to an AWS Glue connection to let network interfaces set up by AWS Glue communicate with each other within a private subnet.
Network traffic flow through the components:
![]()
Outbound network traffic from AWS Glue resources in the private subnet to any destination or data store outside the private subnet is routed through the NAT gateway.
![]()
The NAT gateway is present in a public subnet and has an associated Elastic IP address. It forwards network traffic from AWS Glue resources to internet by using an internet gateway.
When AWS Glue tries to establish a connection with a data store outside of the private subnet, the incoming network traffic on the data store side appears to come from the NAT Gateway.
On the data store side, you allow the data store or its security group to accept incoming network traffic from the Elastic IP address attached to the NAT gateway. This is shown in the section “Allow Amazon Redshift to accept network traffic from AWS Glue,” following.
Creating VPC components using AWS CloudFormation
You can automate the creation of a VPC and all the components described preceding using the vpc_setup.yaml CloudFormation template, hosted on GitHub. Follow these step-by-step instructions to create the stack in your AWS account:
- Deploy the stack in the US Oregon (us-west-2) Region:

Note: In this example, we create the AWS Glue resources and connection in the us-west-2 Region. You can change this to the AWS Region where you have your AWS Glue connection and resources.
You are directed to the AWS CloudFormation console, with the stack name and URL template fields pre-filled.
- Choose Next.

- Use the default IP ranges and choose Next.

- Skip this step and choose Next.

- Review and choose Create.



- Wait for stack creation to complete. After completion, all the VPC components and necessary setup required are created.

- Navigate to the VPC console and copy the Elastic IP address for the newly created NAT.
Note: This IP address is used for outbound network flow from AWS Glue resources and so should be whitelisted on the data store side. For more detail, see “Allow Amazon Redshift to accept network traffic from AWS Glue,” following.
Before creating and testing an AWS Glue connection to your data store, you need an IAM role that lets AWS Glue access the VPC components that you just created.
Creating an IAM role to let AWS Glue access Amazon VPC components
For this example, we create a role called TestAWSGlueConnectionIAMRole with a managed IAM policy AWSGlueServiceRole attached to it.
- Choose the Roles tab from the AWS Identity and Access Management (IAM) console.
- Choose Create role and select AWS Glue as a trusted entity.

- Attach an IAM policy to the role that allows AWS Glue to access the VPC components. In this example, we are using the default AWSGlueServiceRole policy, which contains all the required permissions for the setup.

- We name the role TestAWSGlueConnectionRole.


Note: The default GlueServiceRole policy that we attached to our custom role TestAWSGlueConnectionIAMRole has permissions for accessing VPC components. If you are using a custom policy instead of the default one, it should also contain the same permissions to be able to access VPC components.

Creating an Amazon Redshift cluster using AWS CloudFormation
For this example, we create a sample Amazon Redshift cluster in a VPC in the US N. Virginia (us-east-1) Region. Follow these step-by-step instructions to create the stack in your AWS account:
- Navigate to the CloudFormation console in region us-east-1 and create a new stack using this CloudFormation template, described in the documentation.
- Provide the configuration for the cluster and MasterUsername and MasterUserPassword. MasterUserPassword must follow the following constraints:
- It must be 8–64 characters in length.
- It must contain at least one uppercase letter, one lowercase letter, and one number.
- It can use any printable ASCII characters (ASCII code 33–126) except ‘ (single quote), ” (double quote), :, \, /, @, or space.

- Choose Next and proceed with the stack creation.

- Review the configuration and choose Create.



- Wait for stack creation to complete, which can take a few minutes.

- Navigate to the Amazon Redshift console and choose the cluster name to see the cluster properties.

- Note the JDBC URL for the cluster and the attached security group for later use.

Note: We created a sample Amazon Redshift cluster in a public subnet present inside a VPC in Region B. We recommend that you follow the best practices for increased security and availability while setting up a new Amazon Redshift cluster, as shown in our samples on GitHub.
Creating an AWS Glue connection
Now you have the required VPC setup, Amazon Redshift cluster, and IAM role in place. Next, you can create an AWS Glue connection and test it as follows:
- Choose Create Connection under the Connections tab in AWS Glue console. The AWS Region in which we are creating this connection is the same as for our VPC setup, that is US Oregon (
us-west-2).

- Choose a JDBC connection type. You can choose to enforce JDBC SSL or not, depending on the configuration for your data store.

- Under the Network Options, Add the Glue VPC, private subnet and security group. This security group has a self-referencing inbound rule and an outbound rule that allows all traffic.

- Add the Connection properties.

- Review configuration and choose Create connection.

The AWS Glue console should now show that the connection was created successfully.

Note: Completing this step just means that an AWS Glue connection was created. It doesn’t guarantee that AWS Glue can actually connect to your data store. Before we test the connection, we also need to allow Amazon Redshift to accept network traffic coming from AWS Glue.
Allow Amazon Redshift to accept network traffic from AWS Glue
The Amazon Redshift cluster in a different AWS Region (us-east-1) from AWS Glue must allow incoming network traffic from AWS Glue.
For this, we update the security group attached to the Amazon Redshift cluster, and whitelist the Elastic IP address attached to the NAT gateway for the AWS Glue VPC.

Testing the AWS Glue connection
As a best practice, before you use a data store connection in an ETL job, choose Test connection. AWS Glue uses the parameters in your connection to confirm that it can access your data store and reports back any errors.
- Select the connection TestAWSGlueConnection that we just created and choose Test Connection.

- Select the TestAWSGlueConnectionIAMRole that we created for allowing AWS Glue resources to access VPC components.

- After you choose the Test connection button in the previous step, it can take a few seconds for AWS Glue to successfully connect to the data store. When it does, the console shows a message saying it “Successfully connected to the data store with connection TestAWSGlueConnection.”

Option 2: Connecting AWS Glue to Amazon Redshift in a private subnet using VPC peering and S3 gateway endpoint.
In this option, we would be using a VPC peering connection and an Amazon S3 gateway endpoint to connect AWS Glue in a private subnet in a dedicated Glue VPC to an Amazon Redshift cluster in a private subnet in another dedicated Redshift VPC. With this option, the traffic stays with the AWS backbone and does not go through the open internet.

Create the Glue VPC
In the VPC console, select Create a VPC and choose VPC and more option. Create the Glue VPC, private subnet, S3 gateway endpoint and enable DNS hostnames and resolutions. Make sure the region is us-west-2.


The Glue VPC, a private subnet and an S3 endpoint has been created.

Create the Redshift VPC
In the VPC console, select Create a VPC and choose the VPC and more option. Create the Redshift VPC, and private subnet. Enable DNS hostnames and resolutions. Make sure the region is us-east-1.


The Redshift VPC has been created.

Peer the Glue VPC and the Redshift VPC Together
- Select the Glue VPC and under Peering connections, choose Create peering connection. Give the connection a name.
- Under Select a local VPC to peer, choose the Glue VPC ID as the requester.
- Under Select another VPC to peer with, choose My account.
- Under Region, choose Another region. Select
us-east-1and use the VPC ID of the Redshift VPC. - Choose Create peering connection.

- Switch to the
us-east-1region to accept the peering connection. Choose Accept request from the dropdown menu under Actions.

- Choose Accept request.

- Enable Domain Name Service (DNS) settings for the peering connections for both the Glue VPC and Redshift VPC. This ensures that AWS Glue can obtain the private IP addresses of your Redshift endpoints. Otherwise, AWS Glue resolves the Redshift endpoints to public IP addresses. AWS Glue cannot connect to public IP addresses without a NAT gateway.

- Select the peering connection for each VPC. Choose to edit the DNS settings and check Allow from each of the VPC peering connection DNS settings and Save.


Update the route tables of the Redshift and Glue VPC
- Select the route table of the Redshift VPC.

- Choose Edit routes and add the IPv4 CIDR address of the Glue VPC to the destination. Under target, select Peering connection and choose the peering connection. Choose Save changes.

- Select the route table of the Glue VPC. You can see that a route of the S3 gateway endpoint was automatically added to the route table.

- Click on Edit routes and add the IPv4 CIDR address of the Redshift VPC to destination. Under target, select peering connection and choose the peering connection. Click Save changes.
Update the Redshift Security Group
- Choose the security group for the private redshift subnet.
- Choose Add rule under Edit inbound rules.
- Under type, select Custom TCP
- Under port range, add 5439
- Under source, add custom and add the Glue private subnet IPv4 CID address.
- Choose Save rules.

Create the Amazon Cluster in the Redshift VPC
- On the Redshift console, select Manage subnet groups under Configurations.

- Choose Create cluster subnet group, and add a cluster subnet group name.
- Under Add subnets, select the Redshift VPC and click on Add all the subnets for this VPC. Choose create cluster subnet group.

- On the Redshift console, choose Create cluster and add a cluster name.
- Under Cluster configuration, choose a cluster node type ra3.xlplus. Select Single-AZ under AZ configurations and under Number of nodes, add 1.
- Under Database configurations, select manually add the admin password, add a password.


- Under Cluster permissions, choose Manage IAM roles and create new IAM role for the cluster. Choose any S3 bucket under Specify an S3 bucket for the IAM role to access.


- Under Network and Security, select the Redshift VPC, select the private subnet security group and the cluster subnet group. Choose Create cluster.


- Amazon redshift creates a new cluster. Note tdhe JDBC URL endpoint.

Create the Glue Connection
- Choose Create Connection under the Connections tab in AWS Glue console. The AWS Region in which we are creating this connection is the same as for our VPC setup, that is US Oregon (
us-west-2).

- Choose a JDBC connection type. You can choose to enforce JDBC SSL or not, depending on the configuration for your data store.

- On the connection details, add the connection-specific configuration. Note the URL for our Amazon Redshift cluster. It shows that the Amazon Redshift cluster is present in
us-east-1. - Under Network Options, add the Glue VPC, private subnet and the security group and choose Next.

- Add the Connection properties and choose Next.

- Review configuration and choose Create connection.

Testing the AWS Glue connection
- Select the connection
Glue Redshift Jdbc connection-VPC Peeringthat we just created and choose Test Connection.

- Select the
TestAWSGlueConnectionRolethat we created for allowing AWS Glue resources to access VPC components and choose Confirm.

- After you choose the Test connection button in the previous step, it can take a few seconds for AWS Glue to successfully connect to the data store. When it does, the console shows a message saying it “Successfully connected to the data store with connection TestAWSGlueConnection.”

Conclusion
We have described two options for connecting Amazon Glue in a different VPC and region to a Redshift cluster in another VPC and region but in the same account. By creating a VPC setup similar to the ones we described, you can let AWS Glue connect to Redshift in a different AWS Region. By doing this, you establish network connectivity between AWS Glue resources and your Redshift cluster. You can now use this AWS Glue connection in ETL jobs and AWS Glue crawlers to connect with the Redshift cluster.
If you have questions or suggestions, please leave a comment following.
Additional Reading
If you found this post helpful, be sure to check out Connecting to and running ETL jobs across multiple VPCs using a dedicated AWS Glue VPC, and How to access and analyze on-premises data stores using AWS Glue.
About the Authors
 Pankaj Malhotra is a Software Development Engineer at Amazon Web Services. He enjoys solving problems related to cloud infrastructure and distributed systems. He specializes in developing multi-regional, resilient services using serverless technologies.
Pankaj Malhotra is a Software Development Engineer at Amazon Web Services. He enjoys solving problems related to cloud infrastructure and distributed systems. He specializes in developing multi-regional, resilient services using serverless technologies.
 Ewanlen Mark Ativie is a Solutions Architect at Amazon Web Services. He enjoys working on cloud solutions and specializes in analytics services.
Ewanlen Mark Ativie is a Solutions Architect at Amazon Web Services. He enjoys working on cloud solutions and specializes in analytics services.
Audit History
Last reviewed and updated in November 2024 by Ewanlen Mark Ativie | Solutions Architect