AWS Big Data Blog
How Ontraport reduced data processing cost by 80% with AWS Glue
This post is written in collaboration with Elijah Ball from Ontraport.
Customers are implementing data and analytics workloads in the AWS Cloud to optimize cost. When implementing data processing workloads in AWS, you have the option to use technologies like Amazon EMR or serverless technologies like AWS Glue. Both options minimize the undifferentiated heavy lifting activities like managing servers, performing upgrades, and deploying security patches and allow you to focus on what is important: meeting core business objectives. The difference between both approaches can play a critical role in enabling your organization to be more productive and innovative, while also saving money and resources.
Services like Amazon EMR focus on offering you flexibility to support data processing workloads at scale using frameworks you’re accustomed to. For example, with Amazon EMR, you can choose from multiple open-source data processing frameworks such as Apache Spark, Apache Hive, and Presto, and fine-tune workloads by customizing things such as cluster instance types on Amazon Elastic Compute Cloud (Amazon EC2) or use containerized environments running on Amazon Elastic Kubernetes Service (Amazon EKS). This option is best suited when migrating workloads from big data environments like Apache Hadoop or Spark, or when used by teams that are familiar with open-source frameworks supported on Amazon EMR.
Serverless services like AWS Glue minimize the need to think about servers and focus on offering additional productivity and DataOps tooling for accelerating data pipeline development. AWS Glue is a serverless data integration service that helps analytics users discover, prepare, move, and integrate data from multiple sources via a low-code or no-code approach. This option is best suited when organizations are resource-constrained and need to build data processing workloads at scale with limited expertise, allowing them to expedite development and reduced Total Cost of Ownership (TCO).
In this post, we show how our AWS customer Ontraport evaluated the use of AWS Glue and Amazon EMR to reduce TCO, and how they reduced their storage cost by 92% and their processing cost by 80% with only one full-time developer.
Ontraport’s workload and solution
Ontraport is a CRM and automation service that powers businesses’ marketing, sales and operations all in one place—empowering businesses to grow faster and deliver more value to their customers.
Log processing and analysis is critical to Ontraport. It allows them to provide better services and insight to customers such as email campaign optimization. For example, email logs alone record 3–4 events for every one of the 15–20 million messages Ontraport sends on behalf of their clients each day. Analysis of email transactions with providers such as Google and Microsoft allow Ontraport’s delivery team to optimize open rates for the campaigns of clients with big contact lists.
Some of the big log contributors are web server and CDN events, email transaction records, and custom event logs within Ontraport’s proprietary applications. The following is a sample breakdown of their daily log contributions:
| Cloudflare request logs | 75 million records |
| CloudFront request logs | 2 million records |
| Nginx/Apache logs | 20 million records |
| Email logs | 50 million records |
| General server logs | 50 million records |
| Ontraport app logs | 6 million records |
Ontraport’s solution uses Amazon Kinesis and Amazon Kinesis Data Firehose to ingest log data and write recent records into an Amazon OpenSearch Service database, from where analysts and administrators can analyze the last 3 months of data. Custom application logs record interactions with the Ontraport CRM so client accounts can be audited or recovered by the customer support team. Originally, all logs were retained back to 2018. Retention is multi-leveled by age:
- Less than 1 week – OpenSearch hot storage
- Between 1 week and 3 months – OpenSearch cold storage
- More than 3 months – Extract, transform, and load (ETL) processed in Amazon Simple Storage Service (Amazon S3), available through Amazon Athena
The following diagram shows the architecture of their log processing and analytics data pipeline.
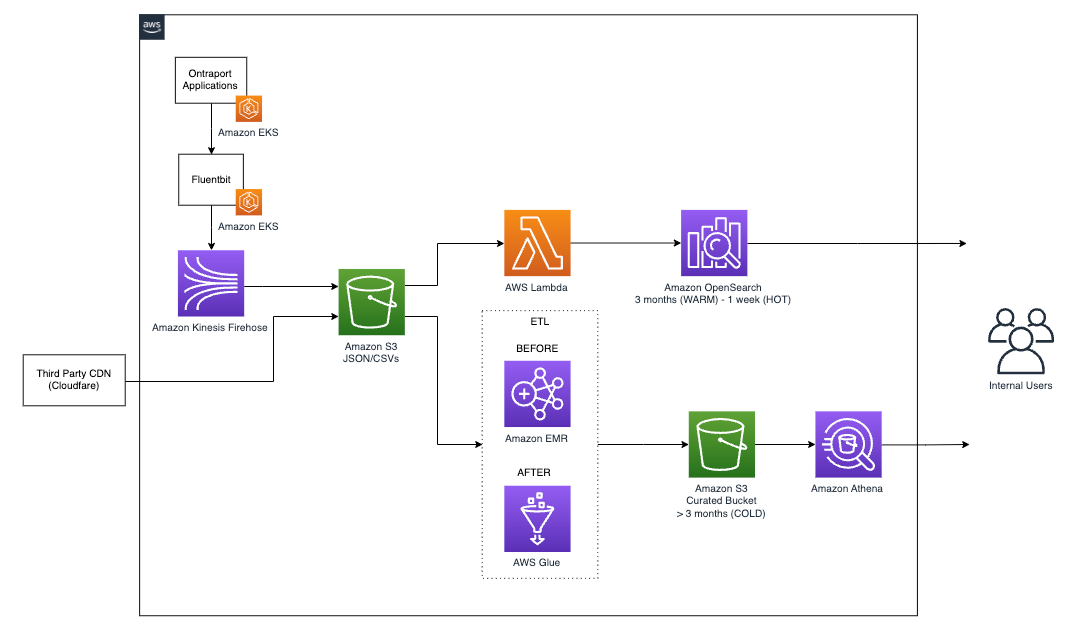
Evaluating the optimal solution
In order to optimize storage and analysis of their historical records in Amazon S3, Ontraport implemented an ETL process to transform and compress TSV and JSON files into Parquet files with partitioning by the hour. The compression and transformation helped Ontraport reduce their S3 storage costs by 92%.
In phase 1, Ontraport implemented an ETL workload with Amazon EMR. Given the scale of their data (hundreds of billions of rows) and only one developer, Ontraport’s first attempt at the Apache Spark application required a 16-node EMR cluster with r5.12xlarge core and task nodes. The configuration allowed the developer to process 1 year of data and minimize out-of-memory issues with a rough version of the Spark ETL application.
To help optimize the workload, Ontraport reached out to AWS for optimization recommendations. There were a considerable number of options to optimize the workload within Amazon EMR, such as right-sizing Amazon Elastic Compute Cloud (Amazon EC2) instance type based on workload profile, modifying Spark YARN memory configuration, and rewriting portions of the Spark code. Considering the resource constraints (only one full-time developer), the AWS team recommended exploring similar logic with AWS Glue Studio.
Some of the initial benefits with using AWS Glue for this workload include the following:
- AWS Glue has the concept of crawlers that provides a no-code approach to catalog data sources and identify schema from multiple data sources, in this case, Amazon S3.
- AWS Glue provides built-in data processing capabilities with abstract methods on top of Spark that reduce the overhead required to develop efficient data processing code. For example, AWS Glue supports a DynamicFrame class corresponding to a Spark DataFrame that provides additional flexibility when working with semi-structured datasets and can be quickly transformed into a Spark DataFrame. DynamicFrames can be generated directly from crawled tables or directly from files in Amazon S3. See the following example code:
- It minimizes the need for Ontraport to right-size instance types and auto scaling configurations.
- Using AWS Glue Studio interactive sessions allows Ontraport to quickly iterate when code changes where needed when detecting historical log schema evolution.
Ontraport had to process 100 terabytes of log data. The cost of processing each terabyte with the initial configuration was approximately $500. That cost came down to approximately $100 per terabyte after using AWS Glue. By using AWS Glue and AWS Glue Studio, Ontraport’s cost of processing the jobs was reduced by 80%.
Diving deep into the AWS Glue workload
Ontraport’s first AWS Glue application was a PySpark workload that ingested data from TSV and JSON files in Amazon S3, performed basic transformations on timestamp fields, and converted the data types of a couple fields. Finally, it writes output data into a curated S3 bucket as compressed Parquet files of approximately 1 GB in size and partitioned in 1-hour intervals to optimize for queries with Athena.
With an AWS Glue job configured with 10 workers of the type G.2x configuration, Ontraport was able to process approximately 500 million records in less than 60 minutes. When processing 10 billion records, they were able to increase the job configuration to a maximum of 100 workers with auto scaling enabled to complete the job within 1 hour.
What’s next?
Ontraport has been able to process logs as early as 2018. The team is updating the processing code to allow for scenarios of schema evolution (such as new fields) and parameterized some components to fully automate the batch processing. They are also looking to fine-tune the number of provisioned AWS Glue workers to obtain optimal price-performance.
Conclusion
In this post, we showed you how Ontraport used AWS Glue to help reduce development overhead and simplify development efforts for their ETL workloads with only one full-time developer. Although services like Amazon EMR offer great flexibility and optimization, the ease of use and simplification in AWS Glue often offer a faster path for cost-optimization and innovation for small and medium businesses. For more information about AWS Glue, check out Getting Started with AWS Glue.
About the Authors
 Elijah Ball has been a Sys Admin at Ontraport for 12 years. He is currently working to move Ontraport’s production workloads to AWS and develop data analysis strategies for Ontraport.
Elijah Ball has been a Sys Admin at Ontraport for 12 years. He is currently working to move Ontraport’s production workloads to AWS and develop data analysis strategies for Ontraport.
 Pablo Redondo is a Principal Solutions Architect at Amazon Web Services. He is a data enthusiast with over 16 years of FinTech and healthcare industry experience and is a member of the AWS Analytics Technical Field Community (TFC). Pablo has been leading the AWS Gain Insights Program to help AWS customers achieve better insights and tangible business value from their data analytics initiatives.
Pablo Redondo is a Principal Solutions Architect at Amazon Web Services. He is a data enthusiast with over 16 years of FinTech and healthcare industry experience and is a member of the AWS Analytics Technical Field Community (TFC). Pablo has been leading the AWS Gain Insights Program to help AWS customers achieve better insights and tangible business value from their data analytics initiatives.
 Vikram Honmurgi is a Customer Solutions Manager at Amazon Web Services. With over 15 years of software delivery experience, Vikram is passionate about assisting customers and accelerating their cloud journey, delivering frictionless migrations, and ensuring our customers capture the full potential and sustainable business advantages of migrating to the AWS Cloud.
Vikram Honmurgi is a Customer Solutions Manager at Amazon Web Services. With over 15 years of software delivery experience, Vikram is passionate about assisting customers and accelerating their cloud journey, delivering frictionless migrations, and ensuring our customers capture the full potential and sustainable business advantages of migrating to the AWS Cloud.