AWS Big Data Blog
Ingest Stripe data in a fast and reliable way using Stripe Data Pipeline for Amazon Redshift
Enterprises typically host a myriad of business applications for varying data needs. As companies grow, so does the demand for insights from a complete set of business data. Having data from various applications that store data in disparate silos can delay the decision-making process. However, building and maintaining an API integration or a third-party extract, transform, and load (ETL) pipeline to move data into a destination data store can be time-consuming and expensive.
Today we’re delighted to introduce Stripe Data Pipeline for Amazon Redshift to help you access your Stripe data and extract insight securely and easily from Amazon Redshift. This data, including billing, issuing, and payment records, can be shared in a consistent and automated fashion. You can integrate your Stripe data with data from other sources in your Amazon Redshift clusters to create a single source of truth.
In this post, we discuss the benefits of Stripe Data Pipeline and some of its use cases.
Solution overview
Amazon Redshift is a fast, fully managed, petabyte-scale cloud data warehousing service that makes it simple and cost-effective to efficiently analyze all your data using your existing business intelligence (BI) tools. It’s optimized for datasets ranging from a few hundred gigabytes to petabytes or more. This columnar data warehouse provides provisioned as well as serverless deployment options and uses an industry-standard SQL interface to analyze structured and semi-structured data with fast query performance.
Stripe Data Pipeline is powered by Amazon Redshift’s latest RA3 instances, which provide cross-account data sharing capability. RA3 takes a performant, cost-effective approach to address rapidly growing data volume by decoupling data processing from managed storage. You can then scale compute and storage independently and only pay for what you use. Data sharing provides read access directly to data stored across Amazon Redshift clusters without data movement. This capability removes the complexity and delays that are often associated with managing large distributed datasets across multiple accounts.
The solution provides the following core features and benefits:
- Scalable and managed data pipeline – You don’t need to build, maintain, and scale custom ETL jobs. You can set up Stripe Data Pipeline in minutes, and it and scales automatically to handle increased business activities and data volume.
- Up-to-date financial data – You automatically receive and refresh a complete set of your Stripe data and reports in Amazon Redshift on a low-latency schedule. Stripe Data Pipeline is built into Stripe and always provides accurate data.
- Security and compliance – Data is shared directly from Stripe with your Amazon Redshift cluster, and confidentiality of the data is protected in transit and at rest. Amazon Redshift offers comprehensive security controls and monitoring via native integration with AWS CloudTrail and Amazon CloudWatch (for more information, see Logging Amazon Redshift API calls with AWS CloudTrail and Monitoring Amazon Redshift using CloudWatch metrics, respectively). You can define and audit who has access to what and ensure the compliance requirements are met.
- Extensibility – Once the data is accessible in AWS, you benefit from the breadth of native integrations Amazon Redshift supports. You can join datasets from other data stores in operational databases, build reports and dashboards with BI tools, or identify patterns and generate prediction using Amazon Redshift ML.
The following architecture diagram provides a quick overview of how data sharing works and how other AWS services can be used together. We dive deeper into different use cases in the following sections.
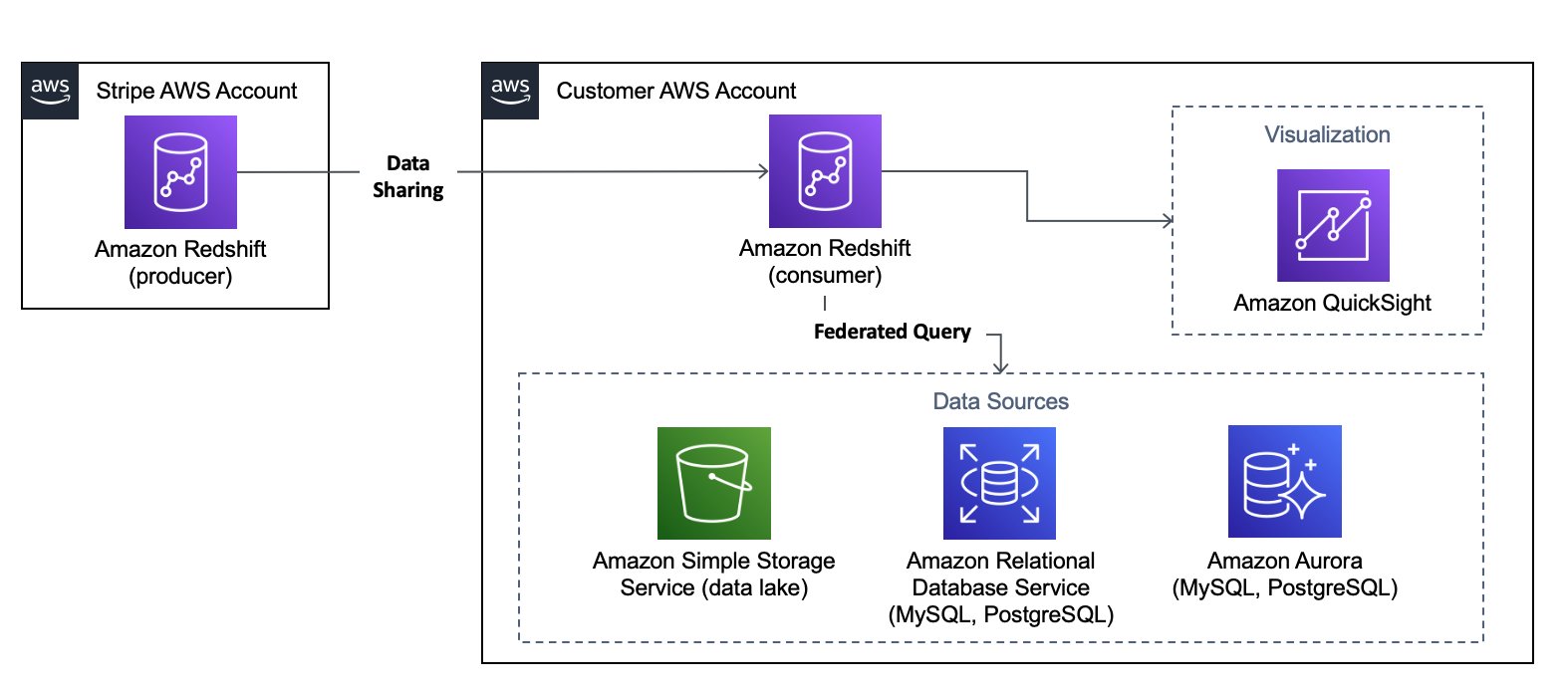
Accept datashares from Stripe
You can configure the solution in a few steps with no code necessary.
Once Stripe creates a datashare from the producer cluster and authorizes your AWS account, you can view this datashare on your Amazon Redshift console. You need to associate it with specific or all clusters in your AWS account as the consumer. Clusters can be specified by namespaces as globally unique identifiers. Next, you create a database from the datashare in order to start querying data.
Query data from the consumer Amazon Redshift cluster
You can now access your Stripe data and schema directly from Amazon Redshift’s web-based query editor. This direct connection enables teams to pull accurate analysis of various functions of the business. For example:
- Finance – “How does my cash flow change based on seasonality?”
- Sales – “How many customers do we have in the US?”
- Product – “How many active users do we have on each subscription plan?”
- Sales operations – “Which customers haven’t paid their invoices?”
The following screenshot shows an example in which the query editor displays the number of charges blocked per Stripe’s connected account.
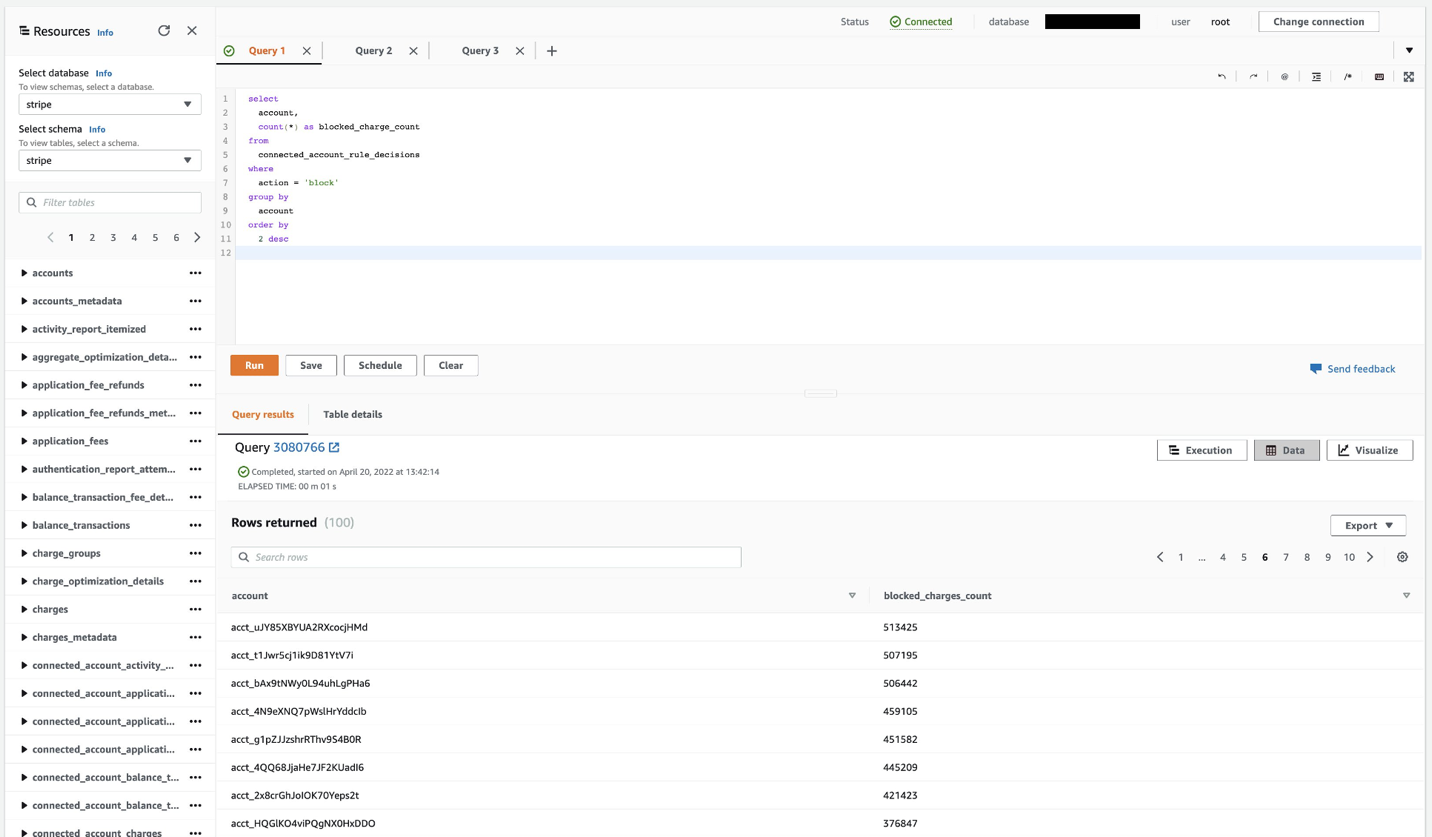
Use federated queries
The modern data architecture of Amazon Redshift enables you to store data in purpose-built data stores based on specific use cases, and allows querying external databases on Amazon Relational Database Service (Amazon RDS) or datasets in an Amazon Simple Storage Service (Amazon S3) data lake without moving these datasets to Amazon Redshift clusters. You can drive deeper by incorporating data from Amazon RDS, or from an S3 data lake through Amazon Redshift Spectrum. This capability provides a native integration without requiring additional ETL jobs.
The following syntax allows you to create an external schema from an Amazon Aurora MySQL-Compatible Edition database to an Amazon Redshift cluster. Amazon Redshift assumes an AWS Identity and Access Management (IAM) role and uses AWS Secrets Manager to access external data stores. For more information and examples with other supported data stores, refer to Querying data with federated queries in Amazon Redshift.
Coming back to Stripe Data Pipeline, now you can combine the data from an Aurora table and create further analysis. For example, you can correlate the trends of customer acquisition against sales campaign by region, so you can gain an understanding of the campaign effectiveness and make adjustment to marketing strategies.
Create visualizations and dashboards
Now that your complete set of business data is accessible from Amazon Redshift, you can start to explore the data and create visualizations. Amazon QuickSight is a serverless BI service that allows you to easily connect to a data source, create analyses, publish dashboards, and share between teams. QuickSight seamlessly integrates with AWS services such as Amazon Redshift, Amazon S3, and many more.
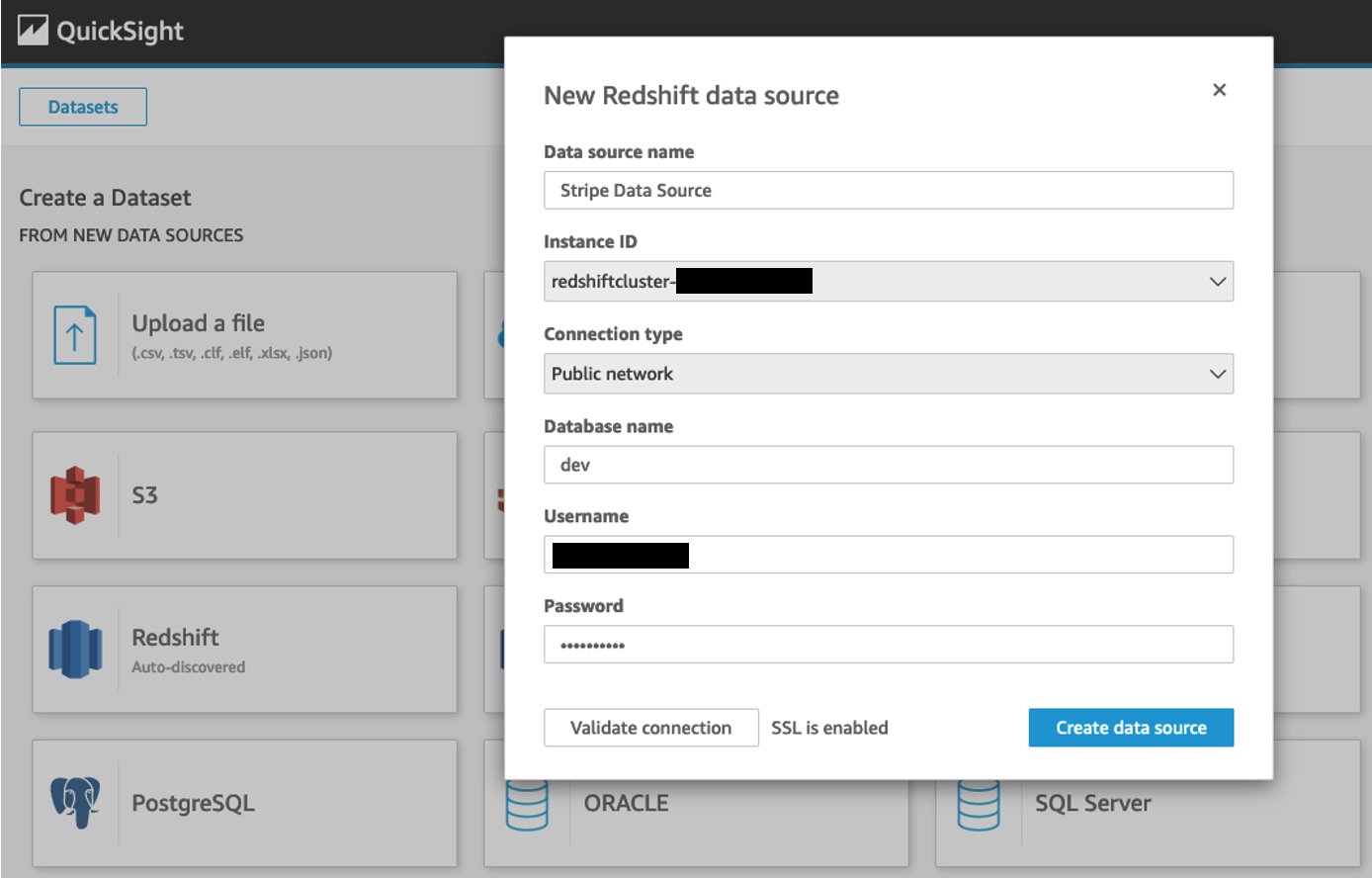
The following screenshot illustrates how straightforward it is to connect an Amazon Redshift instance to QuickSight as a new data source.
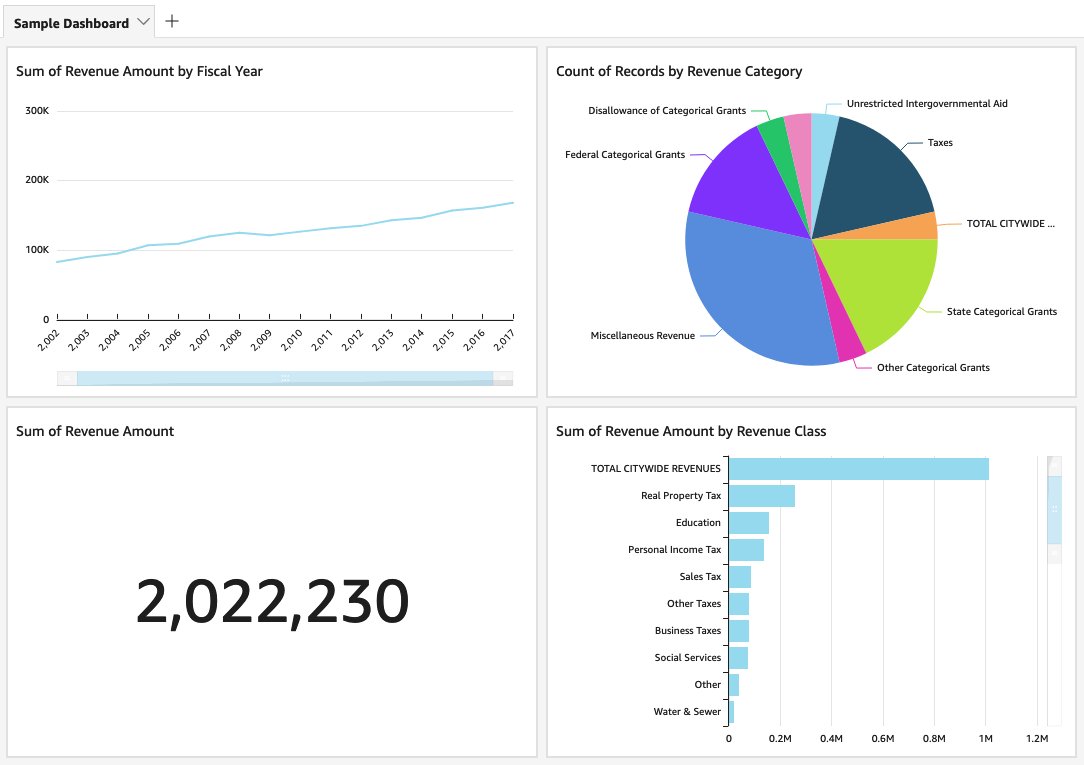
The following screenshot is of a sample QuickSight dashboard pulling data from Amazon Redshift.
Key considerations
When using Stripe Data Pipeline, consider the following:
- Instance type – This solution is available for all RA3 node types. If you run an existing DS2 or DC2 cluster, there are multiple options to migrate to RA3, including elastic resize, snapshot and restore, and classic resize. For more information, including an upgrade sizing reference between different node types, refer to Upgrading to RA3 node types.
- RI migration – If you have Amazon Redshift Reserved Instances (RIs), you can use the RI migration feature to migrate the DS2 RI clusters to equivalent RA3 RI clusters as part of a cross-instance resize or cross-instance snapshot restore operation. The RA3 RI covering the new cluster will be the same cost and on the same calendar terms as the original DS2 RI for supported configurations.
- Encryption – The consumer cluster must be encrypted as part of the enhanced security control for cross-account sharing. You can enable encryption at cluster creation time, or modify an unencrypted cluster with either AWS Key Management Service (AWS KMS) or AWS CloudHSM.
- Federated queries – This capability works with external DB instances, including Amazon RDS for PostgreSQL, Amazon Aurora PostgreSQL-Compatible Edition, Amazon RDS for MySQL, and Aurora MySQL-Compatible Edition. You should also ensure that you have an Amazon Redshift cluster with a cluster maintenance version that supports federated queries.
Conclusion
In this post, we introduced Stripe Data Pipeline for Amazon Redshift and discussed options to further integrate with AWS services. Stripe Data Pipeline removes the need to build custom API integration or adopt a third-party ETL pipeline, making data accessible with a few clicks and with no code required. Businesses can automatically receive up-to-date data from Stripe in their data warehouse on AWS, reduce data silos, and extract deep insights to address business needs.
Check out Stripe Data Pipeline for more information about the solution and how to get started.
About the Authors
 Jessica Ho is a Sr. Partner Solutions Architect at AWS supporting ISV partners who build business applications. She is passionate about creating differentiated solutions that promote cloud adoption. Outside of work, she enjoys spoiling her garden into a mini jungle.
Jessica Ho is a Sr. Partner Solutions Architect at AWS supporting ISV partners who build business applications. She is passionate about creating differentiated solutions that promote cloud adoption. Outside of work, she enjoys spoiling her garden into a mini jungle.
 Alexander Mahabir is a Sr. Partner Solutions Architect at AWS based in the D.C metropolitan area. Alex has over 16 year of experience building cloud, and on-premise solutions for small, medium, and large enterprises. Alex currently works with ISV partners in the Digital Customer Experience segment.
Alexander Mahabir is a Sr. Partner Solutions Architect at AWS based in the D.C metropolitan area. Alex has over 16 year of experience building cloud, and on-premise solutions for small, medium, and large enterprises. Alex currently works with ISV partners in the Digital Customer Experience segment.