AWS Big Data Blog
Tag: Amazon EMR

Improve Apache Spark write performance on Apache Parquet formats with the EMRFS S3-optimized committer
November 2024: This post was reviewed and updated for accuracy. The EMRFS S3-optimized committer is a new output committer available for use with Apache Spark jobs as of Amazon EMR 5.19.0. This committer improves performance when writing Apache Parquet files to Amazon S3 using the EMR File System (EMRFS). In this post, we run a performance […]

Spark enhancements for elasticity and resiliency on Amazon EMR
This blog post provides an overview of the issues with how open-source Spark handles node loss and the improvements in Amazon EMR to address the issues.
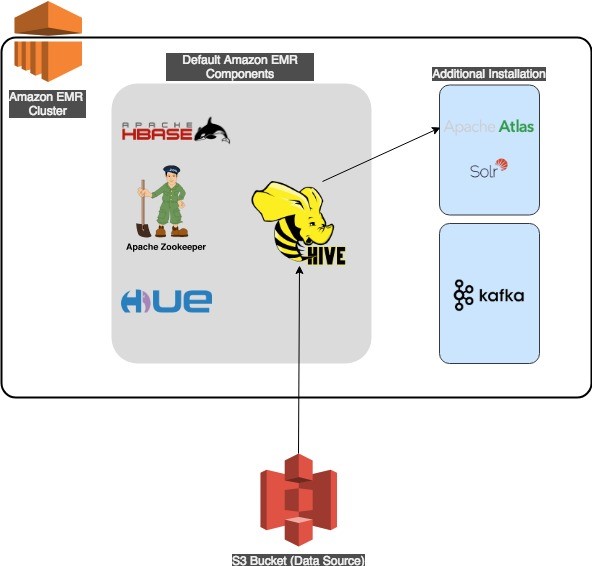
Metadata classification, lineage, and discovery using Apache Atlas on Amazon EMR
This blog post was last reviewed and updated April, 2022. The code repositories used in this blog have been reviewed and updated to fix the solution With the ever-evolving and growing role of data in today’s world, data governance is an essential aspect of effective data management. Many organizations use a data lake as a […]
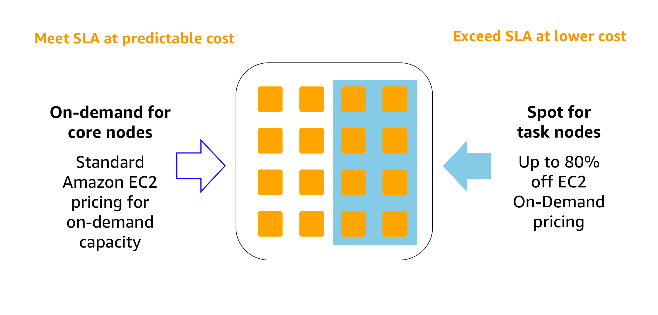
Reduce costs by migrating Apache Spark and Hadoop to Amazon EMR
Apache Spark and Hadoop are popular frameworks to process data for analytics, often at a fraction of the cost of legacy approaches, yet at scale they may still become expensive propositions. This blog post discusses ways to reduce your total costs of ownership, while also improving staff productivity at the same time. This can be […]
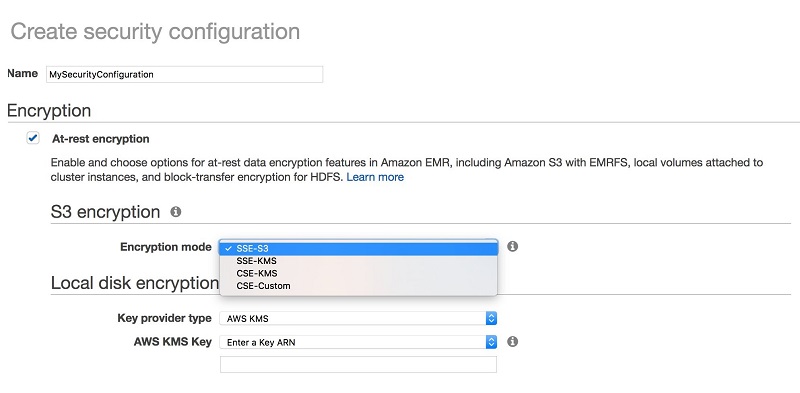
Best Practices for Securing Amazon EMR
This post walks you through some of the principles of Amazon EMR security. It also describes features that you can use in Amazon EMR to help you meet the security and compliance objectives for your business. We cover some common security best practices that we see used. We also show some sample configurations to get you started.
Dynamically scale up storage on Amazon EMR clusters
February 2025: The bootstrap action script in this blog post uses IMDS v1 for accessing EC2 instance metadata. The script does not support IMDS v2 and cannot be used in an AWS account which has IMDS v2 enforced across the account. Using the script in an IMDS v2 enabled account will cause issues and unexpected […]

Getting started: Training resources for Big Data on AWS
Whether you’ve just signed up for your first AWS account or you’ve been with us for some time, there’s always something new to learn as our services evolve to meet the ever-changing needs of our customers. To help ensure you’re set up for success as you build with AWS, we put together this quick reference guide for Big Data training and resources available here on the AWS site.
How to migrate a Hue database from an existing Amazon EMR cluster
This post describes the step-by-step process for migrating the Hue database from an existing EMR cluster.
Easily manage table metadata for Presto running on Amazon EMR using the AWS Glue Data Catalog
In this post, we will explore how the AWS Glue Data Catalog addresses discoverability and manageability for table metadata for Presto on Amazon EMR.

Build a Multi-Tenant Amazon EMR Cluster with Kerberos, Microsoft Active Directory Integration and IAM Roles for EMRFS
In this post, we will discuss what EMRFS authorization is (Amazon S3 storage-level access control) and show how to configure the role mappings with detailed examples.