Containers
Run event-driven workflows with Amazon EKS and AWS Step Functions
Introduction
Event-driven computing is a common pattern in modern application development with microservices, which is a great fit for building resilient and scalable software in AWS. Event-driven computing needs to be push-based with event-driven applications that are run on-demand when an event triggers the functional workflow. Tools that help you minimize resource usage and reduce costs are essential. Instead of running systems continuously while you wait for an event to occur, event-driven applications are more efficient because they start when the event occurs and terminate when processing completes. Additionally, event-driven architectures with Smart Endpoints and Dump Pipes patterns further decouple services, which makes it easier to develop, scale, and maintain complex systems.
This post demonstrates a proof-of-concept implementation that uses Kubernetes to execute code in response to an event. The workflow is powered by AWS Step Functions, which is a low-code, visual workflow service that helps you build distributed applications using AWS services. AWS Step Functions integrates with Amazon Elastic Kubernetes Service (Amazon EKS), making it easy to build event-driven workflows that orchestrate jobs running on Kubernetes with AWS services, such as AWS Lambda, Amazon Simple Notification Service (Amazon SNS), and Amazon Simple Queue Service (Amazon SQS), with minimal code.
Calling Amazon EKS with AWS Step Functions
AWS Step Functions integration with Amazon EKS creates a workflow that creates and deletes resources in your Amazon EKS cluster. You also benefit from built in error-handling that handles task failures or transient issues.
AWS Step Functions provide eks:runJob service integration that allows you to run a job on your Amazon EKS cluster. The eks:runJob.sync variant allows you to wait for the job to complete and retrieve logs.
We use AWS Step Functions to orchestrate an AWS Lambda function and a Map state ("Type": "Map") that runs a set of steps for each element of an input array. A Map state executes the same steps for multiple entries of an array with the state input.
Solution overview
The following diagram demonstrates the solution to run a sample event-driven workflow using Amazon EKS and AWS Step Functions.
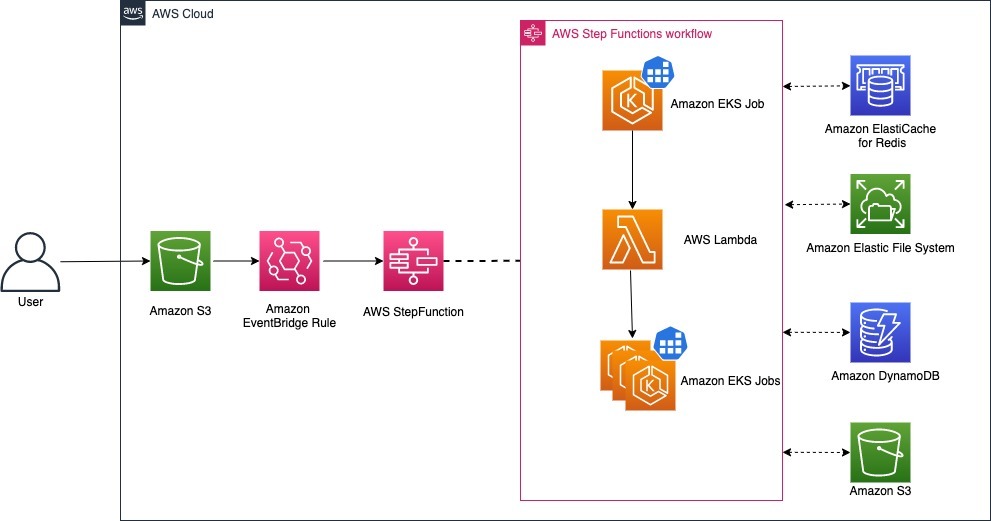
For this demonstration, we use AWS Cloud Development Kit (AWS CDK) and first deploy a set of AWS CDK stacks to create and deploy necessary infrastructure, as shown in the previous diagram. AWS Step Functions invoke when an input file appears in the configured Amazon Simple Storage Service (Amazon S3) bucket.
AWS Step Functions starts the following process when a new file appears in the Amazon S3 bucket:
- AWS Step Functions create a
File SplitterKubernetes job that runs in an Amazon EKS cluster. The job reads the input file from the Amazon S3 bucket and splits the large input file into smaller files, saving them to an Amazon Elastic File System (Amazon EFS) persistent volume. File SplitterKubernetes job uses theunix splitcommand to chunk the large files into smaller ones, with each file containing a maximum of 30,000 lines (which is configured usingMAX_LINES_PER_BATCHenvironment variable).File splitterKubernetes job saves the path of the split files in Amazon ElastiCache (Redis) that are used for tracking the overall progress of this job. The data in the Redis cache gets stored in the following format:
![]()
- AWS Step Functions orchestrate a
Split-file-lambdaAWS Lambda function that reads the Redis cache and returns an array of split file locations as the response. - AWS Step Functions orchestrate a Map state that uses split files array as input and create a parallel Kubernetes jobs in your Amazon EKS cluster to process these split files in parallel, with a MaxConcurrency = 0. Each Kubernetes job receives one split file as input and performs the following:
- Read the individual split file from the Amazon EFS location.
- Process each row in the file and generate
ConfirmationIdfor eachOrderIdfield available for each row in the input file which inserts this information to orders Amazon DynamoDB table. All DynamoDB writes are batched to a maximum of 25 rows per request. - Create a Comma-separated values (CSV) file in a Amazon EFS file location, with each row of the file containing both
ConfirmationIdandOrderIdwritten in batch. - Update Amazon ElastiCache by removing the split file (path) from Redis set using
rdb.SRemcommand. - Finally, merge the output split files in the Amazon EFS directory and upload them to the Amazon S3 bucket.
- It’s very important to settle on a right value for the maximum number of rows a split input file can contain. We set this value via
MAX_LINES_PER_BATCHenvironment variable. Giving a smaller value will end up with too many split files creating many Kubernetes jobs, whereas setting a large value eaves too little scope for parallelism.
Walkthrough
Prerequisites
You need the following to complete the steps in this post:
- AWS CLI version 2
- AWS CDK version 2.19.0 or later
- yarn version 1.22.0
- Node version 17.8.0 or later
- NPM version 8.5.0 or later
- Docker-cli
- Kubectl
- Git
Let’s start by setting a few environment variables:
Bootstrap AWS Region
The first step to any AWS CDK deployment is bootstrapping the environment. cdk bootstrap is a tool in the AWS CDK command-line interface (CLI) responsible for preparing the environment (i.e., a combination of AWS account and Region) with resources required by AWS CDK to perform deployments into that environment. If you already use AWS CDK in a Region, then you don’t need to repeat the bootstrapping process.
Execute the following commands to bootstrap the AWS environment:
Deploy the stack
The AWS CDK code create one stack with the name file-batch-stack, which creates the following AWS Resources:
- An Amazon VPC and all related networking components (e.g., subnets).
- An Amazon EKS cluster
- An AWS Step Function with different states to orchestrate the event-driven batch workload process
- An Amazon S3 bucket to store the input file and merged output file
- An Amazon EvenBridge rule to trigger an AWS Step Function based on write events to Amazon S3 bucket
- An Amazon ElastiCache (Redis) to store split file details
- An AWS Lambda to create an array of split files
- An Amazon EFS file store to store temporary split files
- An Amazon DynamoDB
Orderstable to store the output details of processed order
Run cdk list to see the list of the stacks to be created.
Run the following command to start the deployment:
Please allow a few minutes for the deployment to complete. Once the deployment is successful, you will see the following output:
Start the workflow
To verify that the deployed solution is working, you can upload sample file test.csv under the payload folder to the input bucket. Run the following command from the root directory:
The following image shows a line from the input file:
![]()
When a new file is uploaded to the Amazon S3 bucket, the AWS Step Function state machine is triggered using an Amazon EventBridge Rule. Navigate to the AWS Managed Console and select the state machine created by the AWS CDK (the CDK output includes the name).
The AWS Step Function execution looks like the execution details, as described in the Solution overview section, and shown in the following diagram:
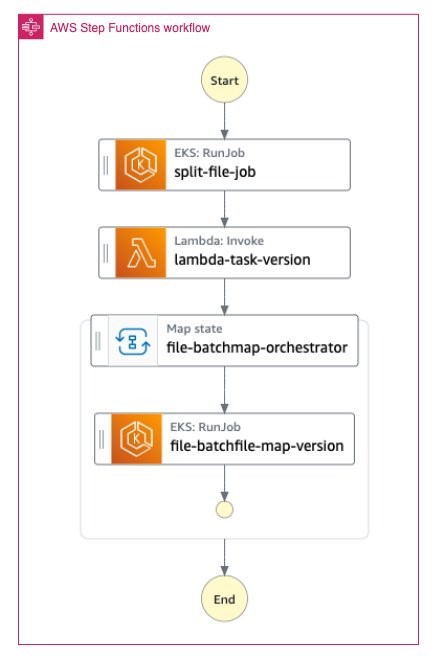
Once the workflow completes successfully, you can download the response file from the Amazon S3 bucket.
Run following command:

Cleanup
You continue to incur cost until you delete the infrastructure that you created for this post. Use the following command to clean up the resources created for this post:
AWS CDK asks you:
Are you sure you want to delete: file-batch-stack (y/n)?
Enter y to delete.
Conclusion
This post showed how to run event-driven workflows at scale using AWS Step Functions on Amazon EKS and AWS Lambda. We provided you with AWS CDK code to create the cloud infrastructure, Kubernetes resources, and the application within the same codebase. Whenever you upload a file to the Amazon S3 bucket, the event triggers a Kubernetes job.
You can follow the details in this post to build your own serverless event-driven workflows that run jobs in Amazon EKS clusters.