AWS Database Blog
Amazon DevOps Guru for RDS under the hood
Amazon DevOps Guru for RDS is a new capability for Amazon DevOps Guru that helps developers using Amazon Aurora database instances detect, diagnose, and resolve database performance issues fast and at scale. DevOps Guru for RDS uses machine learning (ML) to automatically identify and analyze a wide range of performance-related database issues, such as over-utilization of host resources, database bottlenecks, or misbehavior of SQL queries. When an issue is detected, DevOps Guru for RDS displays the finding on the DevOps Guru console and sends notifications using Amazon EventBridge or Amazon Simple Notification Service (Amazon SNS).
This new feature of DevOps Guru runs on a standalone system that continuously monitors and detects anomalies based on the database load (DB load) metric, which is collected by Amazon RDS Performance Insights. When an anomaly is detected, the system triggers an in-depth analysis on other performance metrics such as database wait events and top database queries in order to provide insightful diagnosis of the issue. Additionally, the system generates useful recommendations to help you resolve the issues that caused the anomaly.
In this post, we go into details of how DevOps Guru for RDS works, with a specific focus on its scalability, security, and availability.
System architecture
Let’s look at the components of the system, as shown in the following diagram. When Performance Insights is enabled on an RDS instance, a lightweight agent continually samples the instance’s performance metrics from the database instance and forwards the encrypted metrics to Amazon Kinesis Data Streams. The system relies on Amazon Kinesis for processing and analyzing real-time, streaming data at large scales. If DevOps Guru is enabled on the database instance, some of the non-sensitive performance metrics are then forwarded to DevOps Guru for processing.
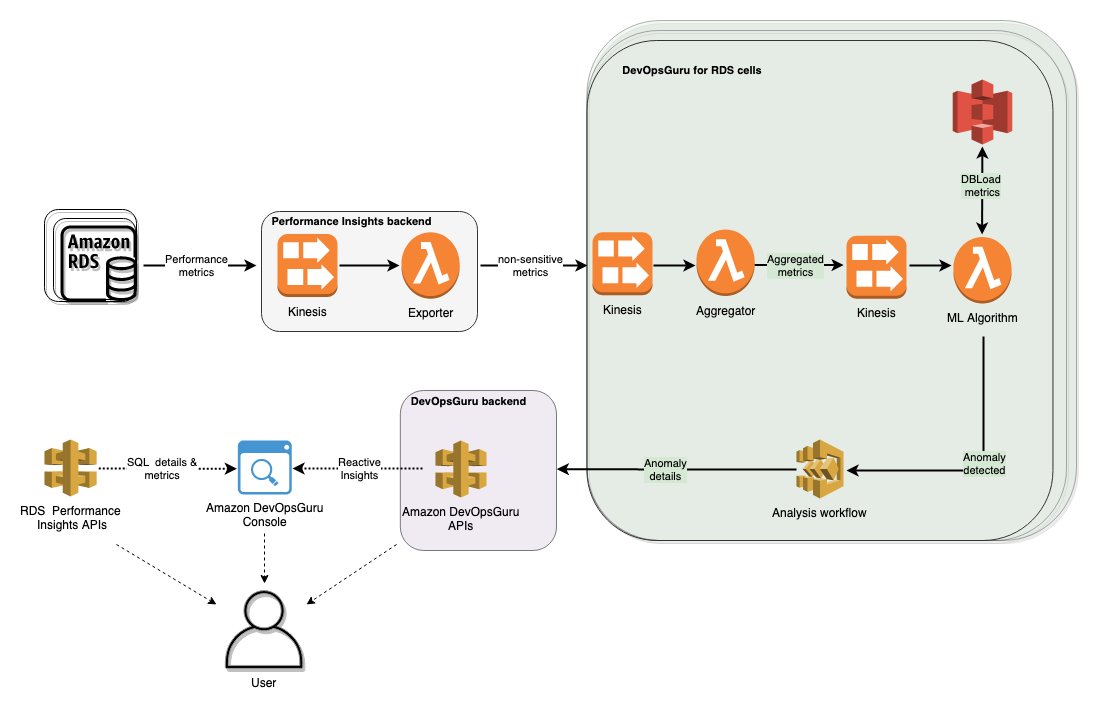
Cellular architectures have become a common pattern at AWS. The primary objective of a cell-based architecture is to minimize the blast radius of failures. Failures come in many forms, for example, software bugs, infrastructure failures, or operational mistakes. Cell-based architectures help contain failures to a single cell instead of affecting the entire Region. The other objective of cell-based architectures is the ability for the system to horizontally scale out while maintaining maximally sized components that can easily be performance tested. DevOps Guru for RDS divides the system into cells, where each cell is an isolated unit that is responsible for handling only a percentage of database instances in a given Region. As the fleet of DevOps Guru-enabled database instances in a Region grows, a new cell can be added to handle the increase in load.
Each Kinesis data stream in a DevOps Guru for RDS cell is partitioned by a Region-unique, immutable identifier for the database instance, DBiResourceId, and contains all the metrics that DevOps Guru for RDS needs, sorted by collection timestamp. Because it’s a Region-unique, immutable identifier, DBiResourceId serves as an ideal Kinesis partition key to collect metrics throughout the lifecycle of the database instance. These performance metrics are collected at a per-second granularity, but the DevOps Guru for RDS anomaly detection component prefers per-minute data in order to reduce the cost of performing anomaly detection. Therefore, the system uses an AWS Lambda tumbling window setup to aggregate metrics per minute and forward only the aggregated statistics like the sum, average, and counts to the anomaly detection component.
The primary metric used to detect anomalies is database load (DB load). DB load measures the level of activity in the database, making it a great metric to understand the health of the database instance. If the DB load is above the max vCPU line, this could indicate that the database instance is oversubscribed and having performance issues. However, relational database loads are often periodic, such as high spikes of DB load owing to a weekly batch reporting job. Such spikes of DB load are expected, and therefore are (a lot) less relevant to alarm on. To reduce false positives, the ML algorithm is trained to identify and ignore such regular patterns in the DB load. For example, consider the following sample DB load graph for a database instance. The DB load spikes in yellow are considered periodic and expected, even though some of the spikes are a lot higher (more than three times) than the max vCPU. However, the DB load spikes in red are not expected and therefore are detected by the ML algorithm as anomalous.

The ML algorithm is deployed on Lambda, which is configured to synchronously process batched records from the Kinesis data stream using the native Lambda and Kinesis integration. The ML algorithm requires a sliding window of recent DB load history of the database instance as input. This data is cached in Amazon Simple Storage Service (Amazon S3) because the data is large (over 400 KB) and Amazon S3 offers a low-latency, low-cost, highly available, and easy-to-use solution.
When a DB load anomaly is detected, the system gathers more data to determine the contributing top SQL queries and database wait events. Wait events describe the exact conditions a particular database session is waiting for. The most common wait event types are waiting for the CPU, waiting for a read or write, or waiting for a locked resource. Examining wait events help identify contention for system or database resources. Data about the anomaly is analyzed based on rules and best practices curated from the collective experience of Amazon RDS database engineers. The result of this analysis are recommendations that help you diagnose and fix the issue.
After generating recommendations, all anomaly details are forwarded to DevOps Guru. DevOps Guru further aggregates the anomaly details and groups them with other anomalies in your application (if any) before surfacing the anomalies to you as reactive insights via the DevOps Guru console and APIs.

Conclusion
We are excited about how DevOps Guru for RDS will help you diagnose and resolve database performance problems. We hope this post helped you understand how our architecture addresses the core requirements of scalability, security, and availability.
For more information on how to get started with this new capability of DevOps Guru, see New – Amazon DevOps Guru for RDS to Detect, Diagnose, and Resolve Amazon Aurora-Related Issues using ML.
About the Author
 Vikas Lokesh is a Software Development Engineer in RDS at Amazon Web Services.
Vikas Lokesh is a Software Development Engineer in RDS at Amazon Web Services.