AWS Database Blog
Automate Amazon Aurora Global Database endpoint management for planned and unplanned failover
This blog post was last reviewed or updated April, 2022 to include unplanned failover feature.
Important note: This solution relies on Route 53 control plane, which is only available in N.Virginia region (us-east-1). For an unplanned failover, if your primary Region is us-east-1 we don’t advise using this solution as it takes a dependency on the Route 53 control plane, which is in us-east-1. It’s a best practice to not take a dependency in a failover mechanism that is in the same Region you would be failing out from. Refer to Creating Disaster Recovery Mechanisms Using Amazon Route 53 to learn more. If your primary region is N.Virginia(us-east-1), we recommend deploying this solution with the switch --features 'planned’.
Amazon Aurora is a MySQL and PostgreSQL-compatible relational database built for the cloud. Aurora combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open-source databases. Aurora Global Database lets you span your relational database across multiple Regions. Global Database is a perfect fit for use cases when you want cross-Region disaster recovery or to achieve low-latency reads in secondary Regions. Global Database is a great way to scale your readers across multiple Regions.
In this post, we discuss a solution to automate managing global database endpoints.
Overview of Global Database
A global database cluster is made up of multiple Regional clusters. A Global Database cluster may have up to six Regional clusters in supported Regions, such as clusters in both us-east-1 and us-west-2.
In the global database topology, only one Region is primary and all other Regions are secondary. The primary Region contains the only writer instance and also contains the only active writer endpoint. The writer endpoint always points to the active writer node. All secondary Regions also have writer endpoints, but they’re inactive.
Each Regional cluster also has a reader endpoint. The reader endpoint balances read traffic to read replicas in a Regional cluster, if there are any. The reader endpoint isn’t affected after a global database failover.
There are two failover scenarios with Aurora Global Database – managed planned failover and unplanned failover.
Managed planned failover feature lets you switch from the current primary Region to the secondary in a managed fashion. You can invoke the managed failover process via the AWS Management Console, AWS Command Line Interface (AWS CLI), or API. During the failover process, the designated secondary cluster gets promoted to primary, the old primary is demoted to secondary, and the replication direction is reversed. During this process, the writer endpoint of the cluster changes and the writer endpoint in the new primary becomes the active writer endpoint. When that happens, database users and applications have to be reconfigured to update their connections strings to use the new endpoint.
Currently, Aurora Global Database does not support a managed option for unplanned failover. An unplanned failover has to be carried out manually by a first detaching the surviving secondary Aurora DB cluster from the Global Database and then promoting it as an individual Aurora cluster. At the completion of unplanned failover, the newly promoted Aurora cluster has a different writer endpoint. The process is covered in detail in the Aurora user guide.
In both cases, it’s tedious and time-consuming to reconfigure the applications after a failover. This post discusses a solution to automate endpoint management for Global Database that automatically switches between Regions so the apps never have to be reconfigured to update the connection strings.
The solution discussed in this post is available as sample code on GitHub.
Architecture overview
The solution creates an Amazon Route 53 private hosted zone and a CNAME record. As shown in the following diagram, users and applications connect to the Route 53 CNAME endpoint to connect to the database writer. The automation updates the CNAME to the writer endpoint of the current primary cluster in the global database in the event of a managed planned failover.
Important note: This solution relies on Route 53 control plane, only available in the N. Virginia Region (us-east-1). Refer to Creating Disaster Recovery Mechanisms Using Amazon Route 53 to learn more.
Applications not using SSL can get automated endpoint updates on a managed planned failover. We discuss SSL support limitations later in this post.
The solution relies on event notifications. The solution uses two events:
- A managed planned failover (RDS-EVENT-0185) event to detect managed planned failover.
- An event that detects an Aurora cluster removed from a Global Database cluster and promoted as a single cluster (RDS-EVENT-0228).
After it’s deployed, the solution keeps the CNAME updated to the correct writer when the endpoint change is caused by either of these events described above. Care must be taken to continue to handle endpoint if using SSL for endpoint connections.
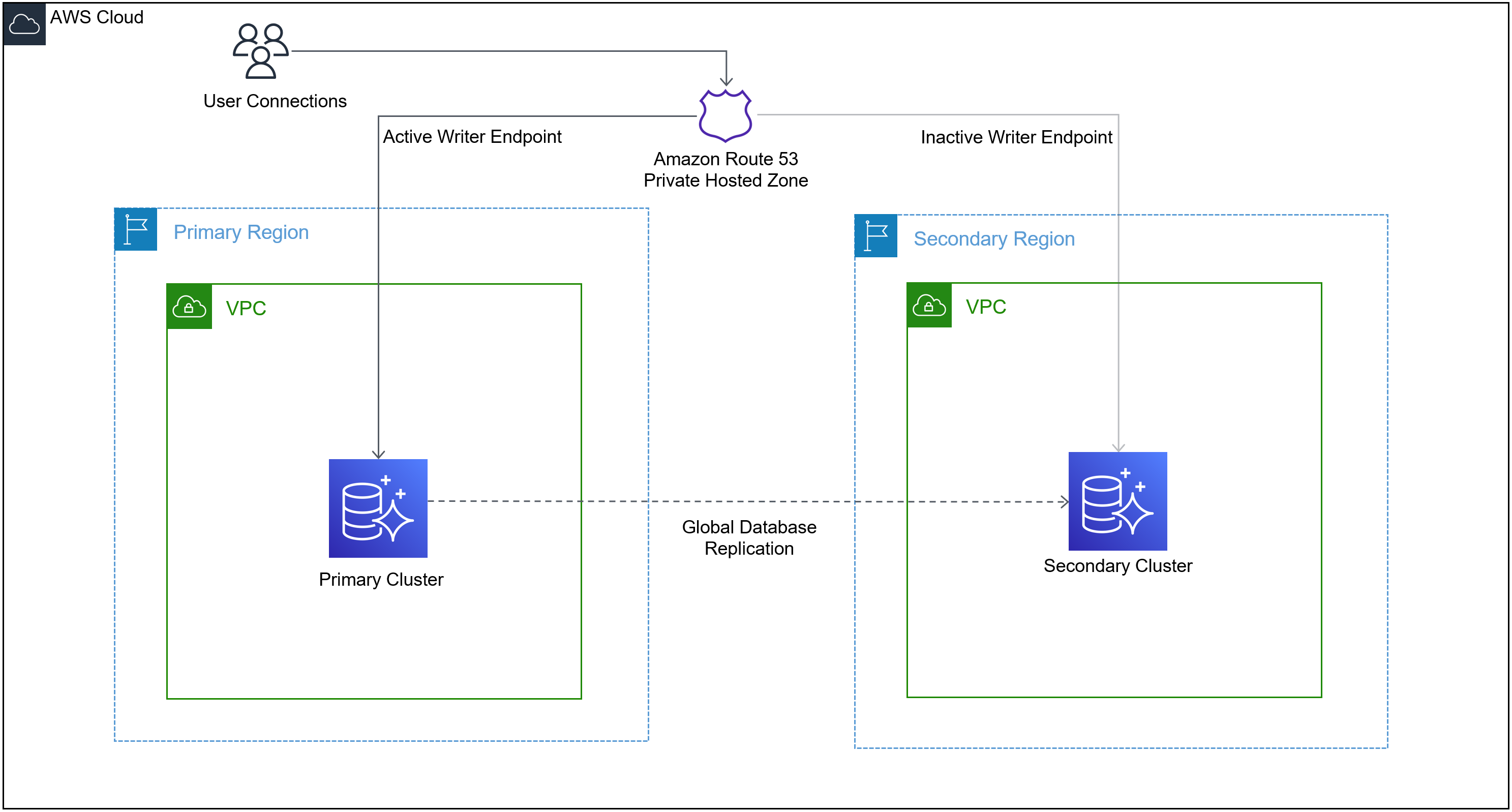
Components involved in the solution
Let’s do a quick overview of the services used in the architecture:
- Amazon Route 53 – Route 53 is a highly available and scalable cloud Domain Name System (DNS) web service. It’s designed to give developers and businesses an extremely reliable and cost-effective way to route end-users to applications by translating names like
www.example.cominto the numeric IP addresses. The solution creates a private hosted zone and CNAME records that route the client requests to the active writer endpoint. One CNAME record is created for every global database cluster and kept updated to point to the current writer endpoint of that cluster. A CNAME (Canonical Name) record is used in the DNS (Route 53 in this case) to create an alias from one domain name to another domain name. In this case, the CNAME record is passed as a parameter during initial deployment of the solution and redirects connection to the current writer endpoint. - Amazon DynamoDB – Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It’s a fully managed, multi-Region, multi-active, durable database with built-in security, backup and restore, and in-memory caching for internet-scale applications. This solution creates a DynamoDB table for record keeping.
- Amazon EventBridge – Amazon EventBridge is a serverless event bus that makes it easier to build event-driven applications at scale using events generated from your applications, integrated software as a service (SaaS) applications, and AWS services. EventBridge delivers a stream of real-time data from event sources. This solution creates an EventBridge rule that is used to match an event pattern any time a global database managed planned failover completes successfully in a Region. When a failover is completed, the completion event is detected, and this rule is triggered.
- AWS Lambda – AWS Lambda is a serverless compute service that lets you run code without provisioning or managing servers, creating workload-aware cluster scaling logic, maintaining event integrations, or managing runtimes. This solution creates a Lambda function that gets triggered on global database failover and updates the CNAME record to the correct value.
Solution overview
Let’s see how this solution works by following the order of events when a global database failover happens. The following diagram shows the chain of events.
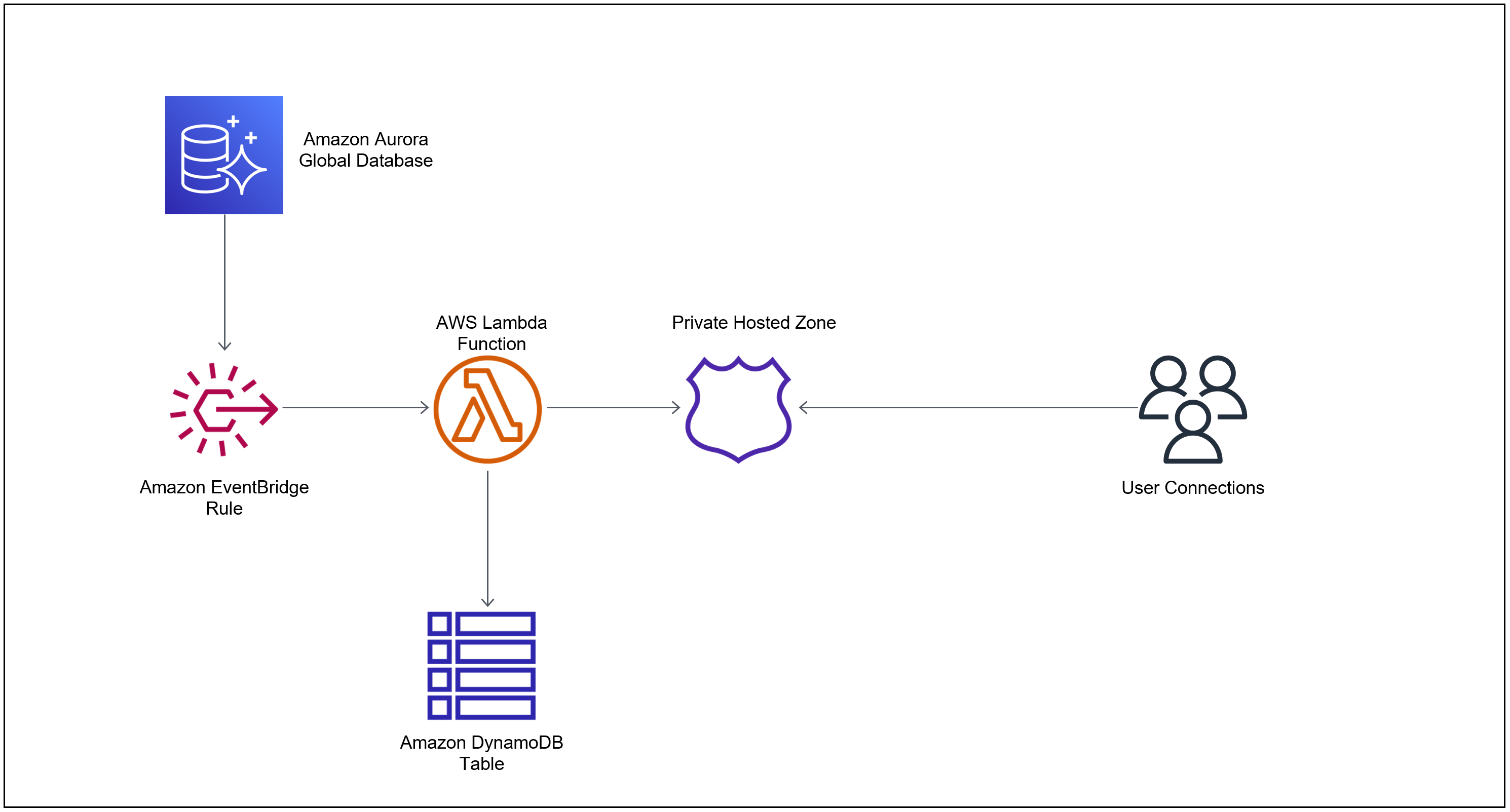
This solution uses a serverless stack to orchestrate the change of CNAME record. The following is the order of events that unfold when a global database fails over using the managed planned failover feature:
- Aurora generates events when certain actions are taken or certain events occur, including any type of global database activity. In our case the activities we are interested in two activities:
- Completion of a global database failover. When a managed planned failover is initiated—either via the AWS CLI, API, or console—the global database failover process starts. When the failover process is complete—after the new cluster is promoted to primary and the writer endpoints are changed—an event is issued that triggers an EventBridge rule. This rule is triggered for all global database clusters in this Region and account. If you need to exclude any specific global database clusters from being managed, you can do it using the solution deployment guide. This rule is triggered by matching the following event pattern:
- Removal of an Aurora cluster from Global Database topology and promotion to a single primary cluster (Detach and Promote). When an Aurora cluster is removed from a Global Cluster – either via the AWS CLI, API, or console – the Aurora cluster is promoted as a single primary cluster. When the promotion process is complete – after the new cluster is promoted to primary and the writer endpoints are changed—an event is issued that triggers an EventBridge rule. This rule is triggered for all clusters being removed from the global cluster in this region and account. If you need to exclude any specific global database clusters from being managed, you can do it using the solution deployment guide. This rule is triggered by matching the following event pattern:
- The rule has a target defined as a Lambda function. When the rule is invoked by the global database failover completion event, it triggers the Lambda function. This function contains the core logic of this solution.
- The function looks up the DynamoDB table to make sure that a global database is being managed by this solution and the private hosted zone ID created for this solution (you pass the hosted zone name during initial deployment).
- If the record is found in the DynamoDB table, it means the global database cluster is being managed by this solution. The Lambda function looks up the current writer endpoint and updates the CNAME.
At this point the automation is complete, and the clients can successfully connect to the new writer endpoint.
Prerequisites
To deploy this solution, you must have the following prerequisites:
- AWS CLI already configured with administrator permission
- The latest version of Python 3
- The AWS SDK for Python (boto3)
- An AWS account with at least one Aurora global database with at least two Regions
- The Git command line tools installed
This solution is made available as sample code on GitHub under the MIT license.
Deploy the solution
To deploy this solution in your account, complete the following steps:
- Clone the repository to your local development machine:
- In the root directory, where you cloned the GitHub repository, from the command line, run the following command. Make sure you pass all Regions where your global database clusters are deployed.
This script deploys the AWS CloudFormation template in all selected Regions, and waits for AWS CloudFormation to finish provisioning the individual stacks. Note the following parameters:
- – – region-list – This command builds the stack in all Regions you passed with the parameter
--region-list. When you run the preceding command, make sure you pass all Regions where your global database clusters are deployed. The number of clusters isn’t relevant here, only Regions need to be passed. The Region list accepts values as comma-separated Region names, for example,us-east-1,us-west-2. - – – features – You can choose if you want to deploy the solution to either managed planned or unplanned failover or both (default). You can control the features by passing either
planned,unplannedorallvalue. - – – consent-anonymous-data-collect – This script collects anonymous, non-PII, and non-account identifiable data to understand how many times this solution has been deployed by customers. Data collection is completely optional, and if you pass no as a value, you’re opted out. This parameter defaults to
yes. It only collects the stack name, Region, timestamp, and the UUID portion of the stack ID (for uniqueness). We only collect data to understand how much the solution is being used, and if so, it motivates us to continue to put resources and efforts in it to refine it further and add features.
For a detailed discussion of all parameters in the command, refer to the readme section of the GitHub repository.
- After AWS CloudFormation finishes building resources in all Regions, run the following command, passing all Regions of the global database:
If you made any mistakes, you can just rerun it. The script is idempotent. When you’re ready to add a new global cluster, you can simply rerun it with the new global database cluster and CNAME pair.
Note the following parameters:
- – – cluster-cname-pair – The global cluster name you want to manage and the writer endpoint you want to create passed in a key-value format separated by a colon. For example, if the global database cluster you’re managing is named
gdb-clu-1and you want to have an endpoint namedtestdomain.com, you pass the value{“gdb-clu-1”:“writer1.testdomain.com”}. You can pass as many clusters you have separated by a comma. - – – hosted-zone-name – The name of the hosted zone to create. Make sure the domain part of your endpoint and the hosted zone names match.
For a detailed discussion of all parameters in the command, refer to the readme section of the GitHub repository.
The solution in its entirety is deployed in 2–3 minutes, regardless of how many clusters or Regions you have.
After deploying this solution, you see two types of resources:
- Global resources created per account:
- Private hosted zone (Route 53) – A private hosted zone is created based on the values you passed.
- CNAME records – A CNAME record is created inside the hosted zone based on the parameters you passed per cluster.
- Local resources created per Region:
- IAM role – An AWS Identity and Access Management role is created so the Lambda function can assume this role while running. The role is very granular and minimalistic. It selectively grants only permissions needed to carry out the functions needed to run the Lambda function.
- Lambda function – This function is invoked on a global database failover completion event, and updates the CNAME. It contains the core logic of the solution automation.
- DynamoDB table – A DynamoDB table named
gdbcnamepairis created. This table keeps track of the clusters that are managed by this solution. - EventBridge rule – This rule is triggered when a global database completes failover in the Region. This rule has the Lambda function as its target.
Current limitations
This solution has following limitations:
- Partial SSL support – Because the solution uses a Route 53 CNAME, the SSL certificate can’t validate the Aurora instance endpoint common name. For example, the PostgreSQL client verify-full or MySQL client ssl-verify-server-cert fails to validate the server identity. However, you can continue to use SSL encryption without the verify servername options.
- Cross-Region VPC path has to be established – The solution only sets up DNS resolution across Regions and VPCs; you’re responsible for setting up a network path between the VPCs across Regions (for example by using VPC peering, a transit gateway, or a transit VPC) if one is needed by your application. If you don’t plan to have applications that connect to the writer endpoint from multiple Regions, then establishing a network path between the VPCs isn’t necessary.
Summary
In this post, we discussed how you can use this custom solution to automate endpoint management for Aurora Global Database, for both managed and unmanaged failover scenarios. The solution is completely hands-off once initially deployed, sets up in minutes, and is fully serverless and event-driven.
You can enjoy cross-Region benefits of Global Database in your environment without worrying about having to manage database endpoints or reconfigure application connection strings during a failover event.
Please test this solution and share your feedback on the comments section.
About the Author
 Aditya Samant is a Sr. Solutions Architect specializing in databases at AWS. His day job allows him to help AWS customers design scalable, secure and robust architectures utilizing the most cutting-edge cloud technologies. When not working Aditya enjoys retro PC tech, playing computer games and spending time with his family and friends.
Aditya Samant is a Sr. Solutions Architect specializing in databases at AWS. His day job allows him to help AWS customers design scalable, secure and robust architectures utilizing the most cutting-edge cloud technologies. When not working Aditya enjoys retro PC tech, playing computer games and spending time with his family and friends.