AWS Database Blog
Automate update of table settings on restored Amazon DynamoDB table
Regular backups are a key component of designing business-critical applications to be resilient in the event of any failure situation. They provide many benefits, the most important being data protection, more efficient recovery of data in the event of disruptions, compliance with organization and legal requirements, and simplified maintenance.
Point-in-time recovery (PITR) for DynamoDB provides continuous, automatic backups of your Amazon DynamoDB table data with per-second granularity to restore to any given second up to 35 days in the past. With PITR, you can back up tables with hundreds of terabytes of data with no impact on the performance or availability of the underlying DynamoDB tables. Refer to Backup strategies for Amazon DynamoDB to learn more. You can enable PITR using the AWS Management Console, AWS Command Line Interface (AWS CLI), or the DynamoDB API.
Although PITR enables you to restore a table to a point in time using the DynamoDB console or the AWS Command Line Interface (AWS CLI), some source table-level settings aren’t automatically applied to the newly created table. These include auto scaling, streams, Time to Live (TTL), and more. For more information about table settings, see Point-in-time recovery: How it works.
In this post, we show you an event-driven solution to automatically apply Amazon DynamoDB table settings to a restored table using AWS CloudFormation templates. This approach removes the need for manual intervention during the point-in-time recovery process and demonstrates how the target table can be governed using a CloudFormation template.
Solution overview
The solution is primarily comprised of the following AWS services:
- AWS CloudFormation
- Amazon DynamoDB
- Amazon EventBridge
- AWS Lambda
- Amazon Simple Queue Service (Amazon SQS)
- AWS Serverless Application Model
Key pointers to note:
- The solution uses Point-In-Time-Recovery DynamoDB API call recorded by AWS CloudTrail, termed as ‘PITR API Call’ in this blog post for better readability.
- The solution described in this post is deployed as an AWS Serverless Application Model application stack. For more information on AWS SAM Application, refer to What is the AWS Serverless Application Model (AWS SAM)?.
We created an AWS SAM application stack that reacts to a PITR API Call and updates table level settings on the restored DynamoDB table. The stack can be divided into two sets of resources:
- Resource group with an Amazon EventBridge rule which reacts to PITR API call.
- Resource group to retry PITR API call from the Amazon SQS queue using exponential back-off and jitter (marked by the red dotted line in Figure 1).
The following is a high-level walkthrough of the solution architecture:
- Restore a table with the Amazon DynamoDB PITR process using either the console or the AWS CLI.
- Amazon EventBridge reacts to PITR API Call
- The EventBridge rule routes the DynamoDB PITR API Call to the Amazon SQS queue
- The event is polled by the Lambda table sync function.
- The Lambda function checks whether the target DynamoDB table is in ACTIVE state.
- If the target table isn’t in ACTIVE state, the event is pushed back to the dead-letter queue (DLQ).
- The process retries with an exponential backoff strategy until the target table either becomes active or it exceeds a specific number of retries.
- If it exceeds the number of retries, the process stops gracefully and is sent to the secondary DLQ, which indicates that the target table wasn’t created for unknown reasons (further troubleshooting is required).
- If the target table reaches the ACTIVE state, the Lambda table sync function deploys the CloudFormation stack to import the target table.
- The table sync function creates and runs the CloudFormation change sets for each setting to be configured for the target table.
Figure 1 that follows illustrates the solution architecture.
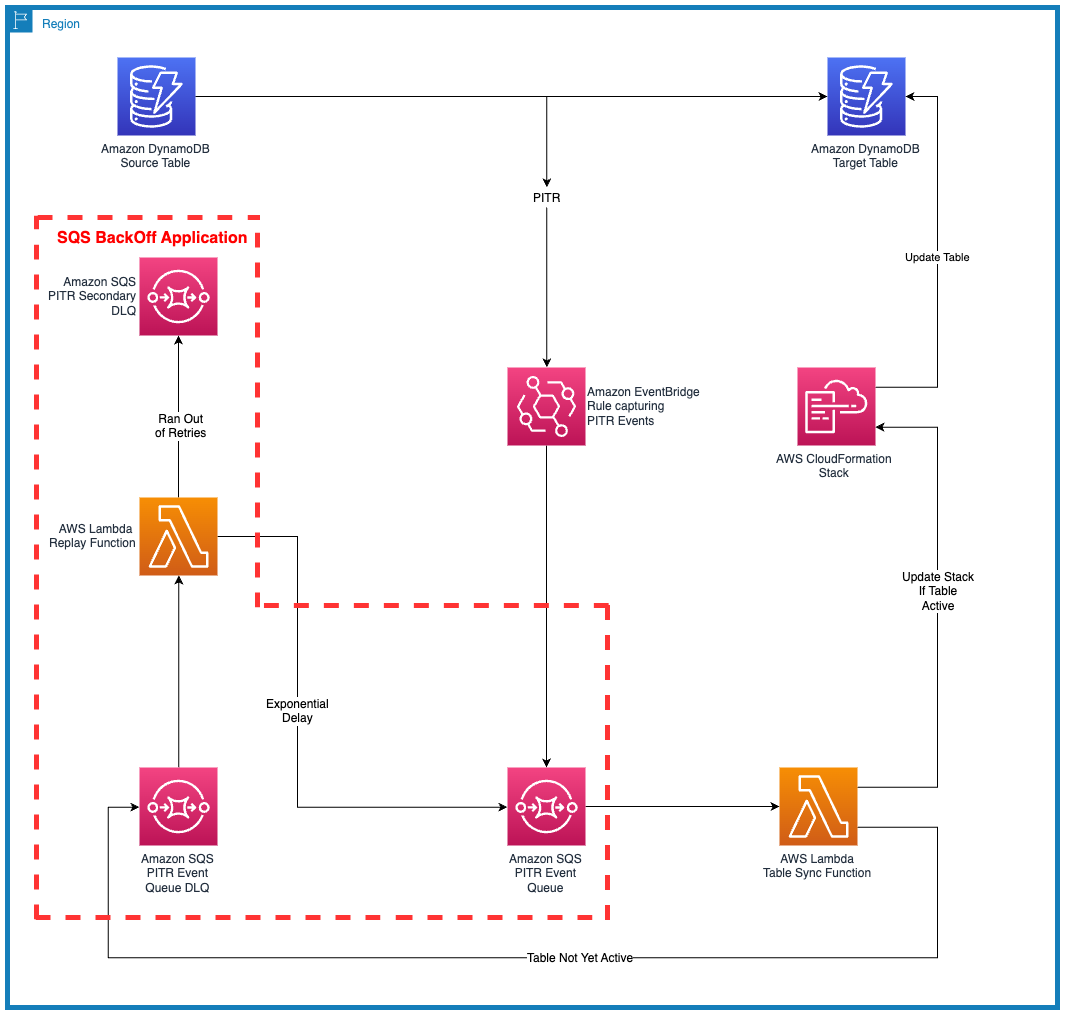
Figure 1 : Solution architecture showing components and process flow
You can find the entire solution in the GitHub repository. It includes an AWS Serverless Application Model (AWS SAM) template that you can use to deploy the entire stack.
Prerequisites
To complete this walkthrough, you must have the following prerequisites:
- An active AWS account. To sign up, see Set Up an AWS Account and Create a User.
- The GitHub repository, cloned and configured on your local machine.
- The AWS CLI installed.
- The AWS SAM CLI for your host environment installed.
- Python installed (Python 3.7).
- The GIT CLI installed.
- The visual editor of your choice, for example Visual Studio Code.
- A web browser, such as Chrome or Firefox.
- Permissions to create AWS resources.
- A DynamoDB table with PITR enabled along with additional table settings enabled, such as Amazon Kinesis Data Streams, TTL, and tags.
Deploy the PITR AWS SAM application stack
Use your visual editor to set up a new workspace and then run the following commands in your shell or terminal window to build and deploy the example application used in this post :
These commands go to the project directory and clone the Git repository that implements the Amazon SQS backoff functionality and is used as a nested resource in the AWS SAM template.
- The sam build command builds the source for the application.
- The sam deploy –guided command packages and deploys the application to AWS, with a series of prompts:
- Stack Name – The name of the stack to deploy to CloudFormation. This should be unique to your account and Region; a good starting point would be the name you’re using for this project.
- AWS Region – The Region you want to deploy the application to.
- Confirm changes before deploy – If set to yes, any change sets are shown to you for review before running. If set to no, the AWS SAM CLI automatically deploys application changes.
- Allow SAM CLI IAM role creation – Many AWS SAM templates, including this example, create the AWS Identity and Access Management (IAM) roles required for the Lambda functions to access AWS services. By default, these are scoped down to the minimum required permissions. To deploy a CloudFormation stack that creates or modifies IAM roles, you must provide the CAPABILITY_IAM value for these capabilities. If permission isn’t provided through this prompt, you must explicitly pass –capabilities CAPABILITY_IAM to the sam deploy command to deploy this example.
- Save arguments to samconfig.toml – If set to yes, your choices are saved to a configuration file inside the project, so that in the future you can rerun sam deploy without parameters to deploy changes to your application.
To verify that the deploy command is successful, open the CloudFormation console, select your stack name, navigate to the events tab, and verify that the CloudFormation stacks have been created and their state is either CREATE_COMPLETE (for new stacks) or UPDATE_COMPLETE (for updated stacks). Shown in Figure 2 that follows.

Figure 2 : Verify the deploy command is successful
Verify PITR is enabled on the source table
Run the following AWS CLI command (replacing SourceTableWithKDS with the name of the table from the prerequisites) to verify whether PITR is enabled on the source DynamoDB table:
The preceding command should display the following JSON:
Verify the settings on your source table
You can verify the settings on your source DynamoDB table either on the console or by running AWS CLI commands.
For example, to verify the Kinesis Data Streams settings on the source table via the AWS CLI, use the following code:
The command should display the following JSON, which shows that Kinesis Data Streams is enabled on the source table:
Restore a Amazon DynamoDB table to a point in time
Restore your DynamoDB table to a point in time either on the console or through AWS CLI commands. For steps to restore your table, refer to the service documentation. In the following code, replace SourceTableWithKDS and TargetTableWithKDSRestore with your source and target table names, respectively:
This command initiates the PITR process with a new table name as TargetTableWithKDSRestore.
The parameters in the command (for example, table names and restore-date-time) might vary based on your use case. Additionally, the time to restore a DynamoDB table from backups can vary depending on factors such as the size of the table and if there is a global secondary index (GSI).
Validate table settings on the target table
Verify the settings in the target (restored) table either on the console or by using AWS CLI commands.
For example, use the following code in the AWS CLI to verify the Kinesis Data Streams settings on the target table:
You should get the following result, which shows that Kinesis Data Streams is automatically enabled on the target table:
You can use the same approach to verify and validate other table settings.
You can further validate the deployment of the solution by using the console to review the CloudFormation Events tab for the template. The status should be UPDATE_COMPLETE, as shown in Figure 3 that follows.
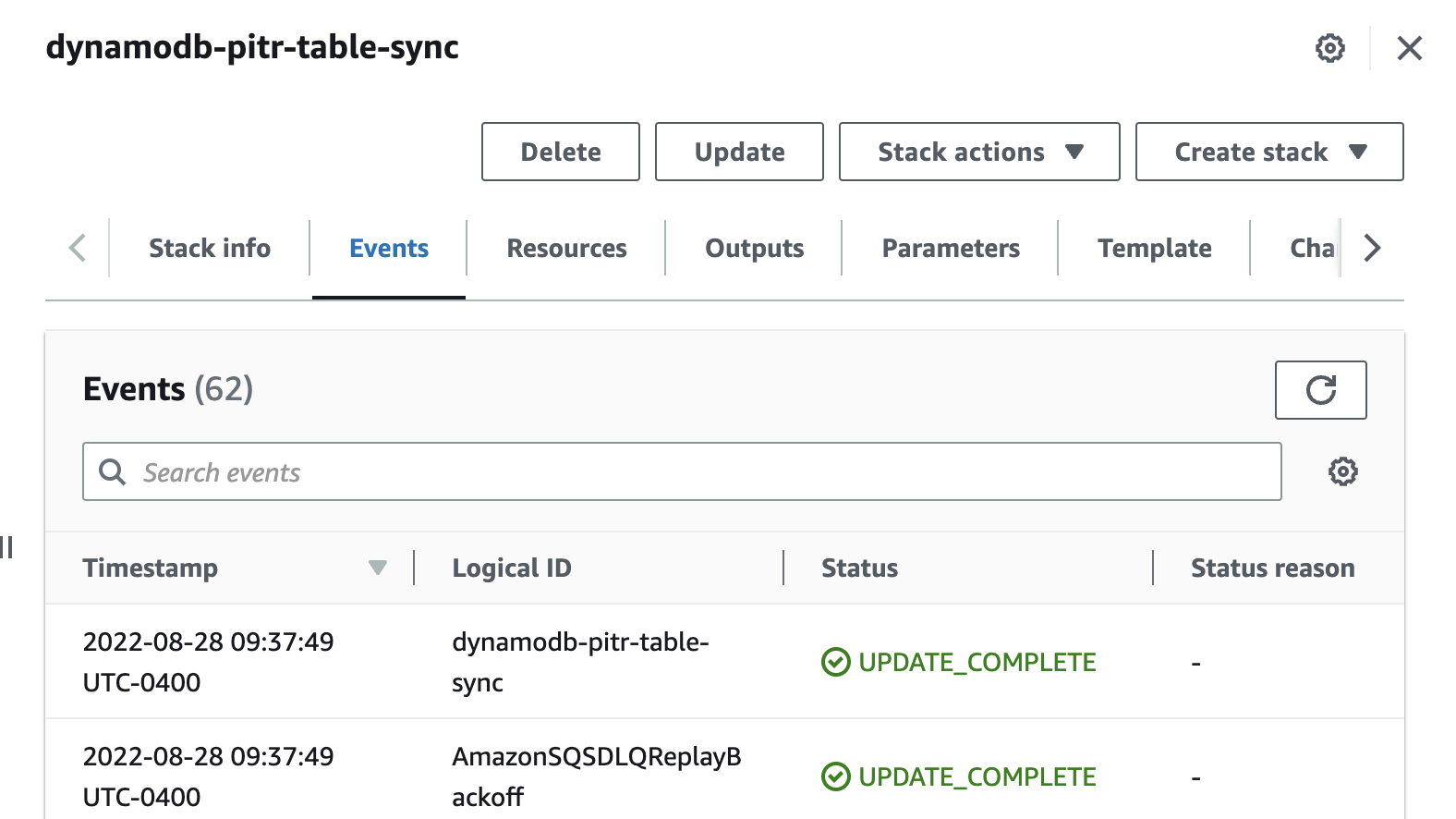
Figure 3: Verify that the CloudFormation events updates successfully
Clean up
To avoid incurring ongoing costs, delete the sample application that you created by using the AWS SAM CLI. You can run the following command, replacing the stack name with your project name if it differs:
Unless needed for other projects, you can delete the source DynamoDB table that you created as mentioned in the prerequisites.
Limitations
The serverless application deployed in this post clones a subset of the DynamoDB source table settings to the target table.
In addition to the settings that are automatically copied over by DynamoDB during the table restoration, the following table settings from the source table are automatically copied to the target table:
- Tags
- Kinesis Data Streams settings
- Amazon DynamoDB Streams settings, along with triggers
- PITR settings
- Auto scaling policies for both the table and index
- TTL settings
The following table settings from the source table are not automatically copied to the target table, but you can add them as extensions to the code base:
- Amazon CloudWatch metrics
- CloudWatch alarms
Additional things to note:
- While setting up the AWS SAM application, you can choose the settings to be cloned from the source table to the target table .
- Settings chosen as part of setting up the AWS SAM application will be applied to all Amazon DynamoDB point-in-time recovery (PITR) API Calls that occur in the AWS account. This automation currently doesn’t provide any capability to control this at the level of an individual PITR API Call.
Things to consider
The following are some of the questions you might have about implementing PITR.
Does Amazon SQS backoff guarantee Amazon DynamoDB point-in-time recovery (PITR) event processing?
Amazon SQS backoff doesn’t guarantee Amazon DynamoDB point-in-time recovery (PITR) API Call processing. However, it guarantees retention of the API Call if the table doesn’t transition into ACTIVE state.
The exponential backoff to retry the events in Amazon SQS is configurable using parameters for the AWS SAM template. The parameters in this solution are set for 50 retries, and the time consumed to exhaust all retries is in the range of 90–120 minutes as every delay before every retry is computed using exponential backoff and jitter.
If the table is large (for example, 100 TB) it might not be fully restored before the retries are exhausted. To avoid this, you can update the parameters to increase either the number of retries by changing the MaxAttempts, the delay between retries by changing the backoff rate, or both. This will delay the exhaustion of application retries until the DynamoDB table has been restored.
Do I have to poll the DynamoDB table status using the Amazon SQS backoff application?
As of this writing, DynamoDB doesn’t emit an event when a table changes status. Therefore, you have to rely on the PITR API Calls recorded by AWS CloudTrail and poll the table status until the table is in ACTIVE state.
Can I choose which settings to clone?
Yes. While deploying the application, the AWS SAM template prompts you to choose true or false for the settings to be cloned between tables.
This automation applies settings to all of the DynamoDB tables that go through the PITR recovery process for a given AWS account.
How can I handle events in the secondary DLQ?
When you configure a DLQ, you can retain any messages that weren’t successfully delivered. You can resolve the issue that resulted in the failed event delivery and process the events at a later time.
In this design, messages that land in the secondary DLQ have to be handled with manual intervention. These messages have landed in the secondary DLQ in spite of all the retries and error handling mechanisms. Therefore, these messages need to be investigated to find the root cause behind the unsuccessful processing.
For example, a notification Lambda function could read messages from the secondary DLQ and publish them to an Amazon Simple Notification Service (Amazon SNS) topic for sending notifications using email, push notifications, SMS, or other methods. Note that Amazon SNS notification is just an example, the architecture of DLQ event processing depends on your business needs and processes.
Does this mean I don’t have to make any settings changes when I restore my table?
It’s better to remove GSIs and local secondary index (LSIs) that aren’t needed, as they increase the time needed to restore the table. Moreover, LSIs can’t be removed after a table is restored. The remaining settings (except LSIs and table name) can be changed after the table is restored.
Conclusion
In this post, you learned how to automatically clone a DynamoDB table’s settings to the restored table using CloudFormation templates with an event-based mechanism. We encourage you to use this post and the associated code as the starting point to clone your DynamoDB table’s settings.
About the authors
 Julia DeFilippis is a Senior Engagement Manager at AWS. She works with customers and stakeholders to ensure business outcomes are met and the AWS team delivers results. She enjoys building relationships with her customers and earning trust through working backward from the customer’s needs and problem statements. See Julia’s LinkedIn profile to connect.
Julia DeFilippis is a Senior Engagement Manager at AWS. She works with customers and stakeholders to ensure business outcomes are met and the AWS team delivers results. She enjoys building relationships with her customers and earning trust through working backward from the customer’s needs and problem statements. See Julia’s LinkedIn profile to connect.
 Priyadharshini Selvaraj is a Data Architect with AWS Professional Services. She works closely with enterprise customers building data and analytics solution on AWS. In spare time, she volunteers for an NPO that serves local communities, and enjoys cake decorating, reading biographies, and teaching piano lessons for kids.
Priyadharshini Selvaraj is a Data Architect with AWS Professional Services. She works closely with enterprise customers building data and analytics solution on AWS. In spare time, she volunteers for an NPO that serves local communities, and enjoys cake decorating, reading biographies, and teaching piano lessons for kids.
 Naresh Rajaram is a Cloud Infrastructure Architect with Amazon Web Services. He helps customers solve complex technical challenges and enables them to achieve their business needs. In his spare time, he loves to spend time with his friends and family. See Naresh’s LinkedIn profile to connect.
Naresh Rajaram is a Cloud Infrastructure Architect with Amazon Web Services. He helps customers solve complex technical challenges and enables them to achieve their business needs. In his spare time, he loves to spend time with his friends and family. See Naresh’s LinkedIn profile to connect.
 Paritosh Walvekar is a Cloud Application Architect with AWS Professional Services, where he helps customers build cloud-native applications. He has a master’s degree in Computer Science from the University at Buffalo. In his free time, he enjoys watching movies and is learning to play the piano.
Paritosh Walvekar is a Cloud Application Architect with AWS Professional Services, where he helps customers build cloud-native applications. He has a master’s degree in Computer Science from the University at Buffalo. In his free time, he enjoys watching movies and is learning to play the piano.