AWS Database Blog
Deploy a high-performance database for containerized applications: Amazon MemoryDB for Redis with Kubernetes
More and more organizations are building their applications using microservices for operational efficiency, agility, scalability, and faster time to market. Microservices and containers have emerged as building blocks for modern applications, and Kubernetes has become the de facto standard for managing containers at scale. Applications running on Kubernetes need a database that provides ultra-fast performance, high availability and durability, security and manageability. Provisioning and integrating databases with containerized applications is often complex. Customers who are using Kubernetes to automatically deploy, scale, and manage their containerized applications are looking to do the same for their database.
In August 2021, we launched Amazon MemoryDB for Redis, which is purpose-built for modern applications with microservices architectures. MemoryDB is ideal for applications that need high performance, security, availability, durability, and scalability. Recently, we have launched a developer preview of the MemoryDB service controller for AWS Controllers for Kubernetes (ACK), which helps developers define and use MemoryDB resources directly from a Kubernetes cluster.
In this blog post, we first explain why MemoryDB is the right database for microservices applications. We then walk through deploying a sample gaming leaderboard application into a Kubernetes cluster provided by Amazon Elastic Kubernetes Service (Amazon EKS). We use MemoryDB as the database and ACK to create and manage a MemoryDB cluster using native Kubernetes APIs.
Why use Amazon MemoryDB for microservices
Modern applications with microservices architecture require massive scale, low read and write latencies, and high throughput performance. Developers like building microservices applications with Redis since it provides performance and scale, and because it provides a number of built-in data structures and commands that simplify performing common application tasks. As these developers deploy more business-critical applications using microservices architectures, they look for their database layer to provide not only high performance but also high durability. Developers often use Amazon ElastiCache for Redis, a fully managed in-memory caching service, as a low latency cache alongside a durable AWS database service such as Amazon Aurora or Amazon DynamoDB. However, this requires custom code to manage data between two independent data stores and additional costs for running two services. Developers want to build durable applications using Redis with less application complexity.
Amazon MemoryDB is a Redis-compatible, durable, in-memory database that makes it simple to build modern applications that require microsecond read and single-digit millisecond write performance, data durability, and high availability. MemoryDB durably stores data using a Multi-AZ transactional log, enabling fast recovery in the face of a failure event. MemoryDB is Redis-compatible, and customers can build applications quickly using Redis’s flexible and friendly data structures and APIs. Instead of using a low latency cache with a durable database, customers can now simplify their architecture and use MemoryDB as a single, primary database for the most demanding, business-critical applications that require low latency, high throughput, and durability.
Traditional approach to building microservices
Modern/simpler approach to building microservices

ACK for MemoryDB
ACK is a collection of Kubernetes custom resource definitions (CRDs) and custom controllers working together to extend the Kubernetes API and manage AWS resources on your behalf. ACK for MemoryDB enables you to provision and manage MemoryDB clusters as part of your Kubernetes applications using your normal infrastructure management workflows.
ACK can be installed on Kubernetes clusters using Helm Charts (available on Amazon ECR). Once installed, the MemoryDB cluster can be created as a Kubernetes custom resource using native Kubernetes tooling (example: kubectl).
The following diagram provides an overview of installing the ACK MemoryDB controller using Helm Charts under the “ack-system” namespace on a Kubernetes cluster. It results in the ACK MemoryDB controller running inside a pod on a Kubernetes worker node and MemoryDB custom resources definitions for the following resources:
- cluster
- user
- acl
- parametergroup
- subnetgroup
- snapshot
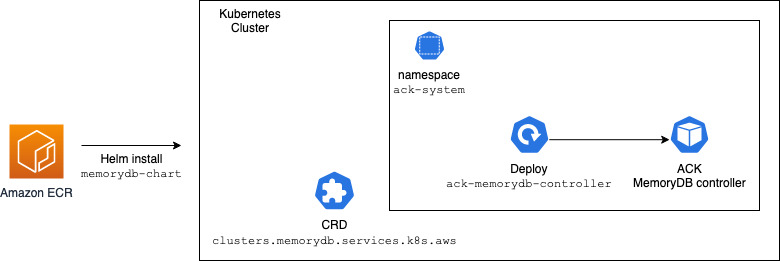
Define and use MemoryDB resources directly from Kubernetes
The ACK MemoryDB controller enables application developers to create a namespaced custom resource (MemoryDB cluster, in this case) in any of their Kubernetes clusters. The MemoryDB service controller installed by cluster admins can create, update, or delete MemoryDB resources based on the intent found in the custom resource.
In the following diagram, the application manifest is applied to the Kubernetes cluster. It contains specifications for a MemoryDB cluster, a Kubernetes ConfigMap, and a microservice application. It results in the ACK MemoryDB controller creating the MemoryDB cluster. The MemoryDB cluster endpoint details are available to the microservice application as container environment variables via the Kubernetes config map.
The containerized microservice app on Kubernetes then connects to the MemoryDB Cluster.
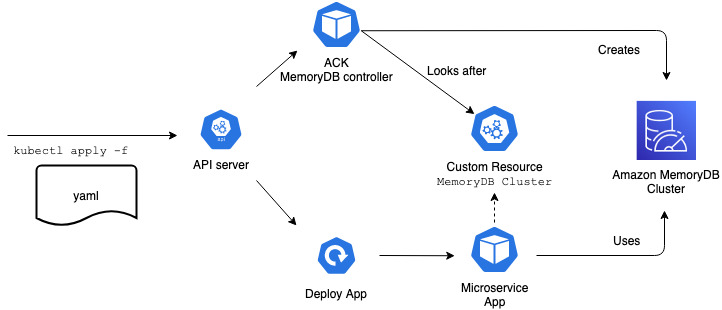
Example gaming leaderboard application using MemoryDB
Let’s walk you through an example gaming leaderboard that uses MemoryDB.
Prerequisites
For a detailed tutorial on installing ACK MemoryDB controller on your Kubernetes cluster, review the documentation at AWS Controllers K8s GitHub.
This example assumes that you have:
- Installed the following tools on the client machine used to access your Kubernetes cluster:
- AWS Identity and Access Management (IAM) permissions to create roles and attach policies to roles.
Setting up Amazon EKS cluster
We will be using eksctl to create a Kubernetes cluster with Amazon EKS. Here we create the cluster with Linux-managed nodes. Please refer to Getting started with Amazon EKS – eksctl for detailed steps.
When the EKS cluster is available, set up the Amazon VPC Container Network Interface (CNI) plugin for Kubernetes for the EKS cluster.
Install ACK MemoryDB controller
You can deploy the ACK service controller for MemoryDB using the memorydb-chart Helm Chart. You can download it to your workspace using the following command:
You will need to decompress and extract the Helm Chart. You can do so with the following command:
You can now use the Helm Chart to deploy the ACK service controller for MemoryDB to your EKS cluster. At a minimum, you need to specify the AWS Region to execute the MemoryDB API calls.
For example, to specify that the MemoryDB API calls go to the US East (N. Virginia) region, you can deploy the service controller with the following command:
For a full list of available values for the Helm Chart, please review the values.yaml file.
Configure IAM permissions
Once the service controller is deployed, you will need to configure the IAM permissions for the controller to query the MemoryDB API. For full details, please review the AWS Controllers for Kubernetes documentation for how to configure the IAM permissions. If you follow the examples in the documentation, use the value of MemoryDB for SERVICE.
Create MemoryDB cluster
You can create MemoryDB clusters using the cluster custom resource. The examples below show how to create it from your Kubernetes environment. For a full list of options available in the cluster custom resource definition, you can use the kubectl explain cluster command.
This example creates the MemoryDB cluster in the same VPC as the EKS cluster using the same subnets and security groups. It creates a MemoryDB SubnetGroup custom resource and then uses it to create a MemoryDB cluster.
The following example creates MemoryDB subnet group:
If you observe that the ACK.Terminal condition is set for the SubnetGroup, and the error is similar to the following:
Then update the subnetIDs in the input YAML and provide the subnet IDs that are in a supported Availability Zone.
The following example creates a MemoryDB cluster. It uses the db.t4g.small node type for the MemoryDB cluster. Please review the MemoryDB node types to select the most appropriate one for your workload.
You can track the status of the provisioned database using kubectl describe on the Cluster custom resource:
When the Cluster Status says available, you can connect to the database instance.
Connect gaming leaderboard application to MemoryDB cluster
The Cluster status contains the information for connecting to a MemoryDB cluster. The host information can be found in status.clusterEndpoint.address, and the port information can be found in status.clusterEndpoint.port. For example, you can get the connection information for a cluster created in one of the previous examples using the following commands:
Set up ConfigMap for MemoryDB cluster endpoint information
The MemoryDB cluster endpoint information can be made available to application pods via ConfigMap using a FieldExport resource. The following example makes the MemoryDB cluster endpoint and port available as ConfigMap data:
Confirm that the MemoryDB endpoint details are available in the config map by running the following command.
Deploy container example and access MemoryDB cluster endpoint
The MemoryDB cluster endpoint details (Address, Port) can be injected into a container either as environmental variables or files. For example, here is a snippet of a deployment definition that will add the MemoryDB cluster connection info into an example leaderboard app:
Confirm that the leaderboard application container has been deployed successfully by running the following:
Verify that the Pod Status is “Running.”
Get a shell to the running leaderboard container.
In the running leaderboard container shell, run the following commands and confirm that the MemoryDB cluster host and port are available as environment variables.
Add gaming leaderboard scripts to running application container
For the steps in this section, execute the commands from the shell running in the leaderboard container.
Install dependencies for the example leaderboard scripts.
Create example leaderboard scripts:
This script connects to the MemoryDB cluster by discovering its endpoint address and port from the container environment variables.
game_latest_scores.py– This script writes example scores for players into the MemoryDB cluster using Redis API.Game_latest_scores.py– This script reads top-ranked players by highest scores for the leaderboard from the MemoryDB cluster using Redis API.
Create a directory to place leaderboard scripts:
Create game_latest_scores.py script:
Create game_leaderboard.py script:
Run gaming leaderboard application
Load game scores into the MemoryDB cluster by running game_latest_scores.py script:
Note: If you are unable to connect to the MemoryDB cluster from the Kubernetes pod, then ensure that the Amazon VPC Container Network Interface (CNI) plugin for Kubernetes has been set up for the EKS cluster, and also review Access Patterns for Accessing a MemoryDB Cluster in an Amazon VPC, based upon the MemoryDB cluster VPC subnet groups and security groups.
Get the latest leaderboard printed on the console by running game_leaderboard.py script:
Observe an output similar to the following list:
Exit the shell running in the leaderboard container:
Cleanup
- To delete the sample gaming leaderboard application, use the following command:
- To delete the ConfigMap and FieldExport, use the following command:
- To delete the MemoryDB cluster subnet group, use the following command:
- To delete the MemoryDB cluster, use the following command:
- To uninstall the ACK service controller for MemoryDB, refer to Uninstall an ACK Controller. Following the example, set the value of
SERVICEtomemorydb. - To delete your Amazon EKS cluster, refer to Deleting an Amazon EKS cluster.
Conclusion
We demonstrated how ACK lets you deploy a MemoryDB cluster directly from your Amazon EKS environment and connect a sample gaming leaderboard application to it. To learn more, visit the Amazon Memory DB for Redis Features page and the AWS Controllers K8s GitHub documentation. Let us know your feedback. ACK is open source; you can request new features and report issues on the ACK community GitHub repository.
About the Authors
 Kumar Gaurav Sharma is a Senior Software Development Engineer at Amazon Web Services. He is passionate about building large-scale, distributed, performant systems.
Kumar Gaurav Sharma is a Senior Software Development Engineer at Amazon Web Services. He is passionate about building large-scale, distributed, performant systems.
 Shirish Kulkarni is an In-Memory DB Specialist Solution Architect for the APAC region and is based in Sydney, Australia. He is passionate about distributed technologies and NoSQL databases. In his free time, you can see him playing with his twin kids.
Shirish Kulkarni is an In-Memory DB Specialist Solution Architect for the APAC region and is based in Sydney, Australia. He is passionate about distributed technologies and NoSQL databases. In his free time, you can see him playing with his twin kids.
 Karthik Konaparthi is a Senior Product Manager on the Amazon In-Memory Databases team and is based in Seattle, WA. He is passionate about all things data and spends his time working with customers to understand their requirements and building exceptional products. In his spare time, he enjoys traveling to new places and spending time with his family.
Karthik Konaparthi is a Senior Product Manager on the Amazon In-Memory Databases team and is based in Seattle, WA. He is passionate about all things data and spends his time working with customers to understand their requirements and building exceptional products. In his spare time, he enjoys traveling to new places and spending time with his family.