AWS Database Blog
How Near reduced latency by four times and achieved 99.9% uptime by migrating to Amazon ElastiCache
This is a guest post by Ashwin Nair, Director, Product Engineering at Near, in partnership with AWS Senior Solutions Architect, Kayalvizhi Kandasamy.
For several years, Near operated multiple Kyoto Tycoon clusters for its real-time bidding (RTB) platform. To improve availability and reduce latency, Near migrated to Amazon ElastiCache, a fully managed in-memory caching service.
In this post, we discuss why Near chose to migrate to Amazon ElastiCache for Redis. We also explain the migration process and show how Near optimized its platform to reduce latency and improve availability.
About Near
Near, a global leader in privacy-led data intelligence, curates the world’s largest source of intelligence on people, places, and products. Near processes data from over 1.6 billion monthly users in 44 countries to empower marketing and operational data leaders to confidently reach, understand, and market to highly targeted audiences and optimize their business results.
ID unification at Near
One of the fundamental challenges in ad-tech data integration is the use of different unique identifiers like cookies on a browser or ad identifiers on a mobile device for users and individuals. As the datasets convene from heterogeneous sources like internal sources, external data brokers, partners, and public sources, it becomes more challenging to get a 360 degree view of the individuals having no common identifiers across the system.
Near’s proprietary ID unification method, CrossMatrixTM, resolves user identity across devices and places in real time, which anchors its data enrichment platform for marketing needs like managing segmentation, engaging audience and offline attribution by helping businesses curate and target audiences, measuring campaign effectiveness, and much more.
Why is latency business critical for Near?
With real-time bidding (RTB), impressions are bought and sold programmatically through auctions. To understand why latency is business critical at Near, let’s take a closer look at the various processes and parties involved in RTB.

First, real-time bidding starts as soon as a user is about to open a mobile app or visit a website. This triggers a bid request from the publisher, which includes various details like the user’s device, operating system, location, and browser. Next, the publisher’s request (with accompanying data) passes to the ad exchange to various advertisers via the ad networks. The ad networks bid on a real-time basis to place ads.
Near’s RTB platform plays a key role with an SLA of 100 milliseconds to bid on the requests received from many of its ad exchange partners across the globe. The entire process, from an app user triggering an ad request to the bidding process to the placement of the ad, happens in just 200 milliseconds.
Near’s RTB platform
Near built its RTB platform using open-source frameworks like Kafka, Apache Nifi, and Apache Flink, previously deployed on a bare-metal cloud infrastructure from another cloud provider. The company migrated to the AWS Cloud and streamlined its big data processing with a data lake on AWS in 2019.
Architecture
Let’s look at the initial architecture of Near’s RTB platform post migration to AWS.
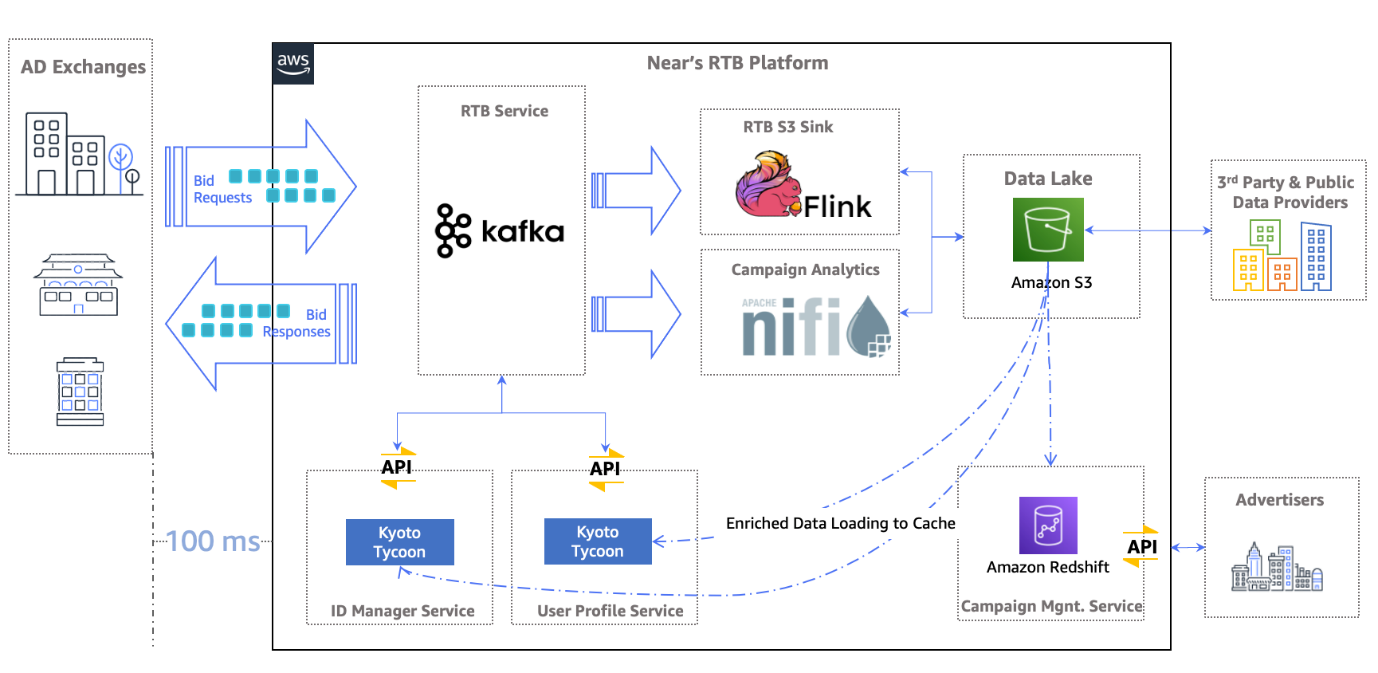
The architecture has three key components: the RTB service, analysis traffic, and campaign management service.
The RTB service is the bid traffic ingestion and processing service that decides whether to bid on an impression or not. It’s primarily based on the knowledge about the user—how well the user matches a set of predetermined advertising campaigns with specific budget objectives. For that purpose, it uses the ID manager and user profile microservices, which were backed by a low-latency, persistent key-value datastore, Kyoto Tycoon. After the decision is made, it decides on how much it can bid and then responds to the ad exchanges.
At the backend, Apache Flink and Apache Nifi ingest the traffic to Amazon Simple Storage Service (Amazon S3). With a data lake built on Amazon S3, Near preserves and processes the historical data for transformation, enrichment, and preparation for rich analytics. This data is critical for future bid traffic because it helps make the decision on how much a given impression is worth to the advertiser and how likely it is that this impression will stick with the app or website user.
Analysis traffic also comes from various third-party and public data providers. Sometimes, the data comes directly from content publishers through tracking pixels, though the scale is low. Later, all this enriched and analyzed data is fed back to the low-latent data store via APIs.
The campaign management service provides advertisers a software as a service (SaaS) platform for managing their advertising campaigns and getting detailed insights of the campaigns. It uses Amazon Redshift for analytics.
The challenges
Now that we understand Near’s RTB platform, let’s take a close look at the challenges Near had with its low-latency data store using the Kyoto Tycoon (KT) server, which powered the platform for years before the migration to ElastiCache. KT is a handy cache and storage server written in C++, and is a lightweight open-source database server. It is a package of network interface to the DBM called Kyoto Cabinet.
When Near started to build its RTB platform, it explored various solutions for caching its user profiles data and originally chose KT for a couple of reasons:
- KT can run 1 million queries in 25 seconds, and supports 40,000 queries per second (QPS)
- KT supports high availability via hot backup, asynchronous replication, and dual master topology
By that time, Near had around 200 million IDs and had to support 500 million requests each day, or 8,000 QPS. With the KT dual primary server setup on Amazon Elastic Compute Cloud (Amazon EC2) instances across Availability Zones, Near was able to meet the business requirements for years.
When Near started expanding and operating in Singapore, India, Australia, and other Southeast Asian countries, its user profile data started growing rapidly—200 million unique users per day. Consequently, its RTB platform was expected to perform much higher than what KT could support (more than 40,000 QPS). Near started facing challenges with its KT setup, which prompted the team to invest in changing its RTB platform cache storage solution.
Increased operational cost
Because the previous KT server was set up on EC2 instances, Near’s DevOps team had to do the heavy lifting of provisioning, backups, sharding, scaling, bringing up the new primary in case of primary node failure, and more. All these manual operations increased the total cost of ownership for Near.
In addition, the open-source development of Kyoto Tycoon seemed to have halted around 2012. From the dates of the articles, Stack Overflow answers, client repos, and presentations, Near found it difficult to operate with its KT server setup with no support from its author or user community.
Performance challenges when scaling
Today, Near has more than 1.6 billion user IDs and profiles, and supports over 10 billion requests per day (120,000 QPS). The KT dual primary server setup, which initially supported Near’s expectations, couldn’t support this business scale.
Also, monitoring the KT server performance didn’t come easily, although ktremotemgr (a KT database client utility) exposes a few metrics. Near had to monitor mostly the EC2 instances that hosted the KT servers.
Read-after-write consistency
As the data volume grew, Near observed replication lag with its secondary because it couldn’t keep up with the updates occurring on the primary. Unapplied changes got accumulated in the secondary’s update logs. This resulted in data inconsistencies when failover happened, though it didn’t affect the RTB service.
Increased RTO
As a hot-fix, Near went ahead with a single KT primary with a hot backup and updated logs configuration for its data durability and availability requirements. This was working out well even when the primary node failed, because it had the golden Amazon AMI of its KT server and hot backups to bring back the primary, satisfying its Recovery Time and Recovery Point Objectives (RTO and RPO).
In the last 7 years, around 10 such hardware issues happened with its KT primary instance. And the last couple of incidents happened in 2019 itself, where the recovery time spiked up to 4 hours. This prompted the need for an architectural change and eventually the replacement of its cache datastore, the KT server, with a highly available, high performant cache server with minimal operational cost.
Migration journey to ElastiCache
When Near started exploring options to replace its cache data store, we found Amazon ElastiCache for Redis to be the best match for the RTB platform.
Redis is an open-source project supported by a vibrant community, including AWS. It’s also Stack Overflow’s most loved database for the past 5 years.
ElastiCache for Redis is a fully managed, highly scalable, secure in-memory caching service that can support the most demanding applications requiring sub-millisecond response times. It also offers built-in security, backup and restore, and cross-Region replication capabilities.
Near chose to replace its KT server setup on EC2 instances with ElastiCache for Redis to accomplish the following:
- Lower the Total Cost of Ownership (TCO)
- Improve performance and operational excellence
- Achieve highly availability
Let’s take a closer look at Near’s migration journey to ElastiCache.
Choosing the right node size
Choosing the right node size and instance type play a key role while designing the solution. We used the size of an item to be cached and the number of items, to arrive at an estimate:
- Size of an item = 50 characters = 50 * 4 Bytes = 200 Bytes (A)
- Number of items = 1 billion Keys (B)
- Memory requirements = (A) * (B) = 200 GB
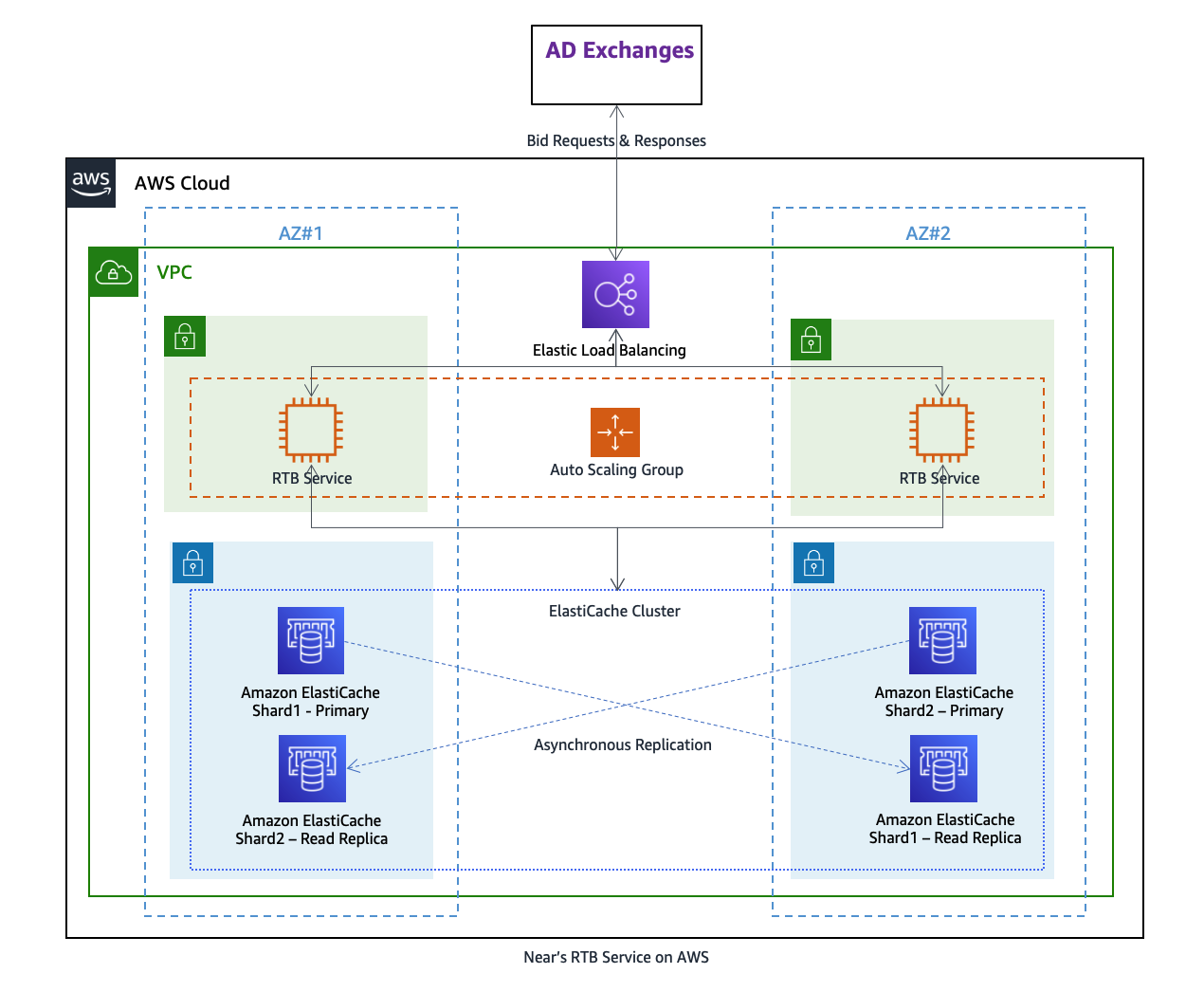
We estimated that 200 GB of memory was required for Near’s data, and chose cache.r6g.8xlarge (32 vCPUs 209.55 GB), the current generation Graviton2 memory-optimized instances. The following diagram shows the architecture that we came up with: having two shards and one read replica per shard considering availability, performance, and backup process requirements.
Application preparedness
The RTB service was updated to perform API invocations on the ElastiCache cluster using the Java Redis client Jedis and the AWS SDK for Java.
Data migration
To seed the ElastiCache for Redis storage, we used the long-term data stored in Amazon S3.
First, we scoped the latest 4 months of data and cleansed it to remove any duplicates. Next, we wrote a Spark job using the aws-sdk-java and hadoop-aws libraries to read the data from Amazon S3 and transform it to a specific format as follows:
Lastly, we used Redis mass insertion to load the data into the ElastiCache clusters using the pipe mode:
Switchover
After testing various use cases, along with the application code changes deployment, the internal-facing KT cluster IP was replaced with the ElastiCache cluster DNS name to switch over to the new caching server.
Decommissioning the KT server
After a month’s time observing the new cache server performance in the production environment, the EC2 instances that hosted the KT servers were decommissioned.
The outcome
In this section, we discuss the outcome of this new architecture.
Total Cost of Ownership
The Near DevOps team no longer needs to perform heavy lifting operations like hardware provisioning, software patching, setup, configuration, monitoring, failure recovery, and backups. ElastiCache, as a fully managed in-memory service, scales out and in based on application requirements.
Performance
Data resides in memory with ElastiCache for Redis so it doesn’t require access to disk. The result is lightning-fast performance with average read and write operations taking less than a millisecond, with support for millions of operations per second.
After migrating to ElastiCache, Near saw close to four times faster read and write performance on its user profile and ID management services—reducing latency from 15 milliseconds to 4 milliseconds post migration.
Operational excellence
Monitoring is vital in maintaining the reliability, availability, and performance of the Redis cache server. And ElastiCache exposes metrics like cache hits, cache misses, concurrent connections, latency, replication lag, and more via Amazon CloudWatch. With the data and insights, Near has set CloudWatch alarms to set thresholds on metrics and trigger notifications when preventive actions are needed.
High availability
With two shards spanning across Availability Zones, a read replica enabled per shard, and automatic failover, Near’s low-latency cache becomes highly available.
Thanks to the failover feature of ElastiCache, we simulated failure of a primary node in the ElastiCache cluster and verified how the read replica gets automatically promoted as a new primary node in a few seconds and a new replica gets launched transparently.
Near also scheduled automated backups that use Redis’s native strategy, generating .rdb files, exported to an S3 bucket. This yields an RPO of 1 day (automatic backup) and RTO based on the backup size to help Near against cache data loss in case of a Regional failure.
Next step: Cost optimization
Unlike traditional databases, all the data is in memory with ElastiCache for Redis, which provides low latency and high throughput data access. And it comes with a cost.
Now Near’s ElastiCache cluster stores more than a billion records, with 3 months’ retention capacity (attribution window), which doubled their spend on AWS compared to its KT server setup on EC2 instances. To optimize the spend, Near has planned the next step: keeping only the hot data, the last 24 hours of data, in the cache. This is roughly around a few millions records in the ElastiCache cluster. From there, Near will move the cold data to a persistent key-value data store to cut costs.
Conclusion
Near was able to reduce latency by four times and achieve 99.9% uptime of its critical RTB platform applications by moving to ElastiCache. Before migration, Near’s DevOps and development engineers had to spend around 4 hours when they faced issues with their self-managed Kyoto Tycoon deployment. Now, Near’s engineers are able to dedicate more time to innovation and building new features rather than spending their valuable time in heavy lifting, infrastructure-related operations. While we work on optimising the cost, Near continues to explore adopting additional ElastiCache for Redis features such as Auto Scaling and Global Datastore considering future scalability needs.
About the Authors
 Ashwin Nair is the Director of Product Engineering at Near. He is a hands on technologist with focus on building highly scalable low latency systems. Ashwin handles the Real Time Bidding system at Near in addition to contributing and leading Near’s product offerings – Allspark, CARBON and Engage. He also leads a team of GIS Engineers building Near’s geo data repository – Near Places. Based out of Bangalore, Ashwin is an avid traveller and has covered 19 countries.
Ashwin Nair is the Director of Product Engineering at Near. He is a hands on technologist with focus on building highly scalable low latency systems. Ashwin handles the Real Time Bidding system at Near in addition to contributing and leading Near’s product offerings – Allspark, CARBON and Engage. He also leads a team of GIS Engineers building Near’s geo data repository – Near Places. Based out of Bangalore, Ashwin is an avid traveller and has covered 19 countries.
 Kayalvizhi Kandasamy works with digital native companies to support their innovation. As a Senior Solutions Architect (APAC) at Amazon Web Services (AWS), she leverages her experience to help people bring their ideas to life, focusing primarily on micro-services architectures and cloud native solutions leveraging AWS products and services. Outside of work, she likes playing chess, she is a FIDE rated chess player, she also coaches her daughters the art of playing chess, and prepares them for various chess tournaments.
Kayalvizhi Kandasamy works with digital native companies to support their innovation. As a Senior Solutions Architect (APAC) at Amazon Web Services (AWS), she leverages her experience to help people bring their ideas to life, focusing primarily on micro-services architectures and cloud native solutions leveraging AWS products and services. Outside of work, she likes playing chess, she is a FIDE rated chess player, she also coaches her daughters the art of playing chess, and prepares them for various chess tournaments.