AWS Database Blog
MYCOM OSI Service Impact Engine migration to Amazon ElastiCache for Redis
This is a guest post by Dirk Michel, SVP, SaaS Technology & Solutions Architecture at MYCOM OSI, in partnership with AWS Solutions Architect Specialist, Zach Gardner.
MYCOM OSI offers assurance, automation, and analytics software as a service (Saas) applications for the digital era. The Assurance Cloud Service provides critical end-to-end performance, fault and service quality management, and supports AI and machine learning (ML)-driven closed-loop assurance for hybrid, physical, and virtualized networks, across all domains, within a SaaS model.
MYCOM OSI’s SaaS assurance applications are Cloud Native Computing Foundation (CNCF) technology based services that are designed to be resilient, scalable, and distributed across AWS Regions as well as edge locations via AWS Outposts. Our SaaS tenants are data ingestion and analytics-heavy applications that handle hundreds of billions of incoming data records per hour, in order to serve up smart data to mission-critical network and service command-and-control centers that own the incident management process.
Redis is used for a variety of use cases such as caching real-time events and service-impact datasets, application caches, as well as session management authentication tokens and queues.
In this post, we detail why MYCOM OSI chose to migrate their application to Amazon ElastiCache for Redis. We discuss details such as drivers for moving from self-managed Redis, including the benefits achieved, the migration journey, and the architectures involved.
Challenges and decisions made
At MYCOM OSI, we were using a container-based Redis as our in-memory data store and caching system to accelerate hot data processing and web application content. Hot data processing is by far the most active workload on Redis. Incoming events and time series data streams are evaluated, correlated, and propagated within our Service Impact Engine, which generates and updates state changes for service-impacting events and likely root cause identification. For data isolation, each microservice stores data in their own specific indexes on a non-clustered Redis deployment.
Before we adopted ElastiCache for Redis, we ran our non-clustered Redis database in a primary replica configuration within our self-managed Kubernetes cluster. The Redis database is spread across multiple Availability Zones, and we used Redis Sentinel for our resilience and failover handling architecture. Our applications that access the Service Impact dataset access the Redis primary nodes directly. The following diagram illustrates our self-managed Redis in primary/replica mode (non-clustered) on self-managed Kubernetes.
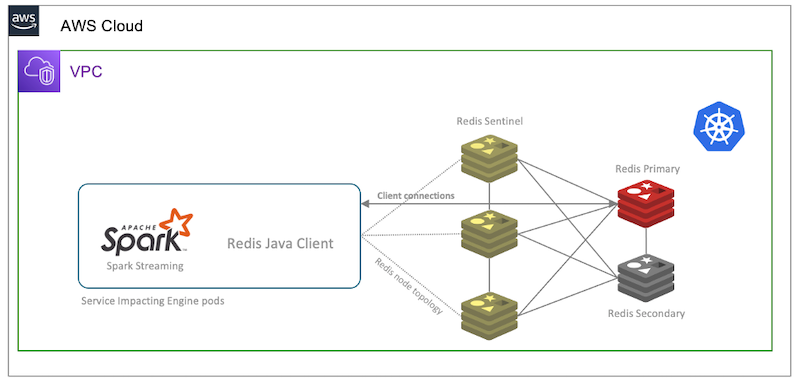
Although this setup worked reasonably well for us, we couldn’t efficiently scale our Redis cluster. Vertical scalability only took us so far, and we faced cluster stability constraints when approaching certain memory capacity and transaction operations on our Redis setup. Manual horizontal scaling of the cluster was possible, but required development as well as operational overhead and involvement of our key developers because of high implementation complexity, in-depth knowledge requirements of Redis, and handling of unforeseen challenges. Ideally, these developers should be focusing on customer-facing features and services. We needed an efficient path and pragmatic approach towards a large-scale clustered architecture.
Given the use of a self-managed Redis environment, we also needed to invest time into undifferentiated work towards software release patching, manual configuration and horizontal scaling, backup definition and rotation, custom monitoring, capacity management, and alerting, as well as defining operating and recovery procedures for our support teams, including fast error detection and remediation workflows.
We identified improvements in total cost of ownership and cost optimization: We needed a path towards adopting AWS Graviton2 instances as well as reducing any over-provisioning to a minimum.
As part of our investigation of options, we identified two possibilities early on: a drop-in replacement with a managed Redis setup, or an improved self-managed deployment architecture. The following diagram compares these options.

We tested the ElastiCache for Redis managed service to validate simple adoption, client library compatibility, and scaling to the capacity sizes we needed while maintaining stability. With the test results in hand, we decided to side-step the redesign of our self-managed Redis clusters and adopt ElastiCache for Redis.
ElastiCache for Redis also helps us realize a set of supplementary objectives, such as data encryption at rest, moving to fine-grained role-based access control, as well as the option to use cross-Region replication with Global Datastore, in cases where very specific targets for recovery time and point objectives are to be designed for.
Migration journey
Our adoption of ElastiCache for Redis had two building blocks. First, we added ElastiCache into the service as part of our updated AWS CloudFormation based deployment pipeline for new tenant provisioning. All new tenants are directly activated with the improved architecture. The second was migrating existing production tenants from the self-managed Redis implementation to the ElastiCache for Redis managed service.
Our migration strategy for existing production tenants consisted of parallel provisioning of the ElastiCache for Redis cluster and defining the indexes for our in-memory caches and data stores. The web and token caches were cut over directly to the new endpoints as part of a planned maintenance window, with minimal impact to the serving application users. The migration of our in-memory data store for the Service Impact engine datasets was more involved. We decided to use an open-source Redis logical replication tool to replicate the active dataset from the legacy Redis nodes into the new ElastiCache for Redis configuration endpoint with live replication enabled. The following diagram illustrates our migration process.

When the data replication is complete and change data capture (CDC) is keeping the new target updated, the applications are reconfigured and cut across towards the new endpoints. When the online migration is complete, we validate the new cluster with our observability overlay during a soak period prior to scaling back the self-managed cluster. We also created an offline migration option of tenants that don’t require uninterrupted replication with CDC.
Conclusion
ElastiCache for Redis offers fully managed Redis that lets you easily operate and scale your deployment, and is integrated to wide range of AWS services. As part of our strategic relationship with AWS, we efficiently collaborated and arrived at our production-grade design and migration strategy. ElastiCache for Redis improves on the observability, manageability, reliability, scalability, and efficiency of our self-managed option. It simplified our security compliance, opened up the option to easily move into cross-Region replication architectures, and helped us realize cost-optimization targets by moving into AWS Graviton2 instances.
About the authors
Dirk Michel is a Solutions Architecture and SVP of SaaS Technology at MYCOM OSI
Zach Gardner is a Solutions Architect Specialist at AWS.