AWS Database Blog

How to encrypt Amazon Aurora using AWS KMS and your own KMS key
When selecting a relational database engine, customers look at many different aspects, including management, performance, reliability, automation, and more recently, the ability to natively encrypt data at rest. Amazon Aurora provides a highly available, optimal, and scalable relational database engine that supports both MySQL and PostgreSQL. Amazon Aurora also supports native encryption of data at […]

Tune sorting operations in PostgreSQL with work_mem
Sorting is one of the most fundamental operations in databases, and optimizing this process is vital to the performance of applications. Sorting involves arranging records in a database table into some meaningful order to make it easier to understand, analyze, and visualize the data. For example, you might want to sort orders by their delivery […]

Optimize Amazon DynamoDB transaction resilience
Amazon DynamoDB transactions help developers perform all-or-nothing operations by grouping multiple actions across one or more tables. These transactions provide ACID (atomicity, consistency, isolation, durability) compliance for multi-item operations in applications. The following scenarios are common use cases for DynamoDB transactions: Financial transactions where an all-or-nothing operation is required. For example, transactions can be used […]

Understand replication capabilities in Amazon Aurora PostgreSQL
Critical workloads with a global footprint, such as financial, travel, or gaming applications, have strict availability and disaster recovery requirements and may need to tolerate a Region-wide outage. Traditionally, this requires difficult trade-offs between performance, availability, cost, and Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO). In some situations, routine maintenance tasks like database […]
Remove bloat from Amazon Aurora and RDS for PostgreSQL with pg_repack
Do you have a database where the size of relations on disk is larger than you expect? Did you observe this size increasing every time you ran several UPDATE and DELETE operations on the relations? Did you observe adverse effects on performance of the database as a result of this? This might be a result […]
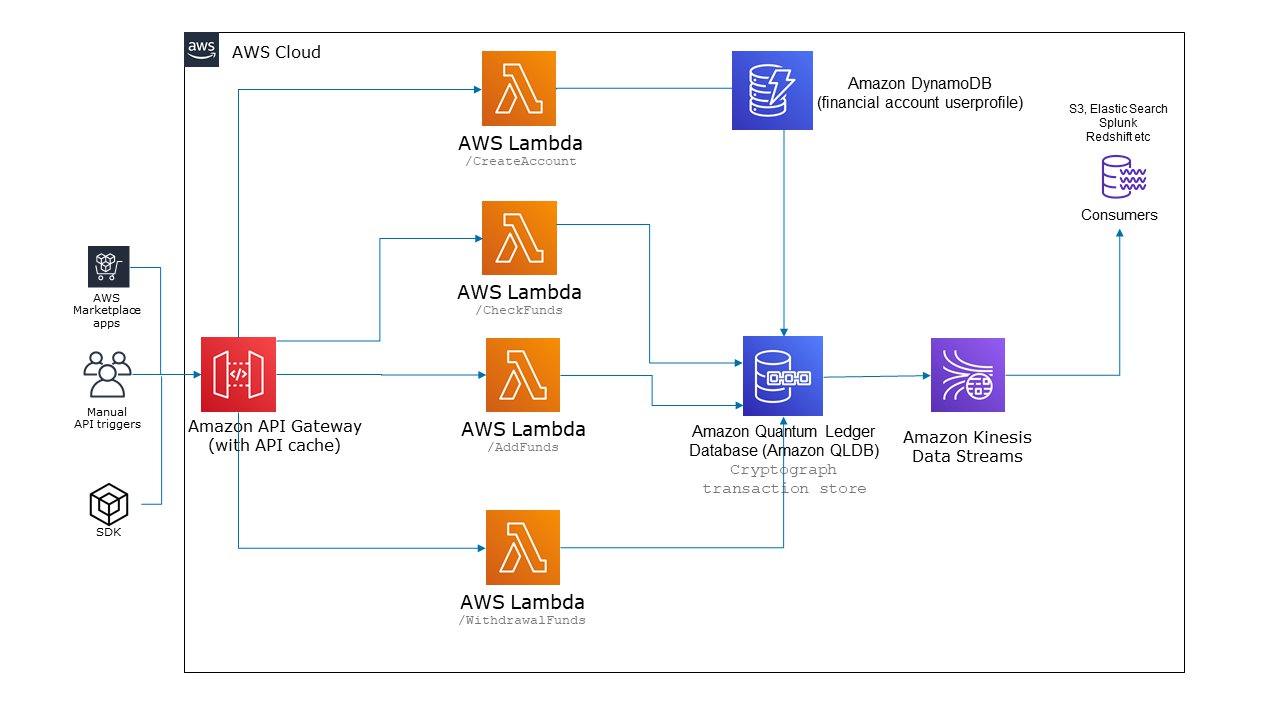
Build a simple CRUD operation and data stream on Amazon QLDB using AWS Lambda
In the financial services industry, efficient data lineage and audit capabilities are highly sought after. This is particularly true for database transaction processing that facilitates the movement of currency and management of sensitive customer account information. This is a challenge for customers because although all financial service providers generally have a means of moving money […]

How Liberty Mutual built a highly scalable and cost-effective document management solution
With more than 45,000 employees in 29 countries, Liberty Mutual is the sixth largest global property and casualty insurer, and currently ranks 71st on the Fortune 100 list of largest corporations in the US. The expectations of customers continue to increase as the pace of change accelerates, the nature and magnitude of risk change, and […]

Implement active/active replication between Amazon Aurora clusters using Oracle GoldenGate
Enterprises both large and small, across diverse industries and with varying levels of cloud maturity, recognize the importance and value of deploying active/active database configurations. An active/active system is a network of independent processing nodes, each having access to a common replicated database so all nodes can participate in a common application. Some enterprises are […]

Replicate and transform data in Amazon Aurora PostgreSQL across multiple Regions using AWS DMS
Global organizations that operate and do business in many countries need to be compliant with data sovereignty and other compliance rules like GDPR. For example, you may want to replicate data to other Regions while at the same time removing certain columns to adhere to privacy laws within a country. In this post, we demonstrate […]

Automate Amazon Aurora Global Database endpoint management for planned and unplanned failover
This blog post was last reviewed or updated April, 2022 to include unplanned failover feature. Important note: This solution relies on Route 53 control plane, which is only available in N.Virginia region (us-east-1). For an unplanned failover, if your primary Region is us-east-1 we don’t advise using this solution as it takes a dependency on the […]