AWS Database Blog
Running highly available Microsoft SQL Server containers in Amazon EKS with Portworx cloud native storage
In this blog post, we explain the deployment of Microsoft SQL Server on containers using Amazon Elastic Container Service for Kubernetes (Amazon EKS). The same approach and principles discussed here also apply to any other stateful application that needs high availability (HA) and durability combined with a reusable and repeatable DevOps practice. Example use cases include running MongoDB, Apache Cassandra, MySQL, and big data processing.
Support for running SQL Server in containers was first introduced with SQL Server 2017. You can run production SQL Server workloads inside Linux containers using Kubernetes (sometimes called K8s).
Microsoft SQL Server is one of the most popular database engines in use today. Although SQL Server offers a number of attractive features and a robust community, it still needs more maintenance or is more expensive than cloud-based or open-source database solutions. Some organizations try to reduce these costs by moving to an open-source solution and reducing their licensing costs. Others choose to migrate their workloads to managed relational database management system (RDBMS) services, such as Amazon RDS for Microsoft SQL Server or Amazon Aurora.
However, there are times when an organization might not be able (or might not want) to move away from the SQL Server engine. This could be for various reasons, such as unjustifiable rework and consequential costs or scarcity of skills within internal teams of developers, IT admins, and engineers. Some of these businesses also might not be able to use a managed cloud service, again due to various reasons such as their licensing and support agreements or special technical requirements.
In these situations, it is still possible to use the many benefits of the cloud by deploying SQL Server databases on Amazon Elastic Compute Cloud (Amazon EC2) instances. This approach maintains the flexibility needed to satisfy special requirements, while still providing many benefits of the cloud. These benefits include complete abstraction from hardware and physical infrastructure, pay-as-you-go with no upfront commitment, and integration with other services. Although it offers a better alternative than running SQL Server on-premises, the additional DB instance management overhead compared with managed services means that there is room for improvement.
Using Kubernetes to run SQL Server provides several powerful benefits:
- Simplicity: Deploying and maintaining SQL Server workloads in containers is even easier and quicker and needs much less effort than traditional deployment models. This is because deployment is fast, no installation is required, upgrades are as easy as uploading a new image, and containers provide an abstraction layer that can run in any environment.
- Optimizing resource use: Containerizing SQL Server workloads enables high density and allows many internal enterprise workloads to share a common resource pool (memory, CPU, and storage). It therefore reduces unused capacity and improves the efficiency of your infrastructure use.
- Lower licensing costs: There are scenarios in which running SQL Server inside containers, either in high density or low density, can shrink overall licensing costs. We explain this in more detail later in the licensing section.
Available container services
Currently, there are four container services available in AWS:
- Amazon Elastic Container Service (Amazon ECS): A highly scalable, high-performance orchestration service that is natively integrated with several other AWS services.
- Amazon Elastic Container Service for Kubernetes (Amazon EKS): A managed service provided by AWS that makes it easy to deploy, manage, and scale containerized applications using Kubernetes.
- AWS Fargate: A compute engine for Amazon ECS that enables you to run containers without having to manage servers or clusters.
- Amazon Elastic Container Registry (Amazon ECR): A fully managed Docker container registry that makes it easy for you to store, manage, and deploy Docker container images.
One of the core principles of architecting in AWS is Multi-AZ deployments, yielding highly resilient and high-performance workloads. You can use Amazon Elastic Block Storage (Amazon EBS) volumes directly as a storage solution for SQL Server containers, but this would restrict these containers to run in a single Availability Zone. As this post shows, Portworx helps us solve this problem.
Portworx is an AWS Partner and a Microsoft high availability and disaster recovery partner. Portworx enables SQL Server to run in HA mode across multiple AWS Availability Zones as part of your EKS cluster. Portworx can also run in highly available configurations across AWS Auto Scaling groups. When used as a storage tier for SQL Server instances, this capability ensures the availability of storage, which is a necessary condition for high availability of containerized SQL Server instances.
This post shows you how to run SQL Server workloads in production using Amazon EKS and Portworx cloud native storage backed by Amazon EBS volumes. We have provided a sample script that automates the deployment process and enables you to deploy your SQL Server instances in minutes.
Benefits of running SQL Server in containers
The first and most basic benefit of using containers is the simplicity and elegance of the solution. There is no need to install SQL Server or configure a failover cluster. You can deploy SQL Server containers with a single command, and Kubernetes inherently provides high availability for your SQL Server deployments. In some cases, the availability of SQL Server instances in a container deployed on Kubernetes could be even higher than that of a workload deployed on top of a failover cluster. See the “High availability” section later in this post for more details.
However, the main benefit of running SQL Server in containers lies in high-density deployments and resource sharing. A fundamental difference between containers and virtual machines (VMs) is that unlike VMs, containers are not restricted to a fixed amount of resources for the duration that they are running. A shared pool of resources is often thrown at a group of containers running side by side on the same host. This enables each container to consume more or fewer resources at different points in time. As long as the aggregate consumption is less than the amount of resources available in the pool, all containers get all the resources they need.

As shown in the preceding diagram, a VM that runs at 100 percent capacity cannot use any of the idle resources available on the same host. In this example, there are two physical hosts on premises with eight CPU cores. Despite the availability of three idle cores, VM 4 and VM 7 are still running in a resource-constrained state.
Now let’s think of another way that could allow a better use of available resources. Imagine a world where you wouldn’t have to worry about physical hosts anymore. Instead, you could provision only a virtual machine with all the aggregate resources needed to run a group of applications, such as several SQL Server instances. Furthermore, assume that you could somehow allow your applications to share all of these resources, while also ensuring there is no contention between them. You can see this alternative in the right side of the diagram, using containers running on an Amazon EC2 instance.
Using this solution, no container is resource constrained, and the overall number of cores is reduced from eight to six physical cores. The same principle also applies to available memory. Containerization, therefore, can improve both the efficiency and efficacy of your infrastructure. This is especially ideal for SQL Server workloads with spiky utilization patterns.
An often-overlooked benefit of running SQL Server in containers is the opportunity to reduce licensing costs. SQL Server is a commercial product. The usage limitations imposed through licensing terms could hamper your decision-making from a purely technical point of view or significantly push up business costs. The way Microsoft licensing terms are defined for SQL Server containers can sometimes substantially mitigate these problems. For more information, see the “SQL Server containers licensing” section later in this post.
SQL Server on Amazon EKS architecture
Kubernetes is an open-source software that can be used to deploy and manage containerized applications at scale. It’s a centrally managed distributed system that runs and orchestrates containers.
When you have a Kubernetes cluster available, it is fairly straight forward to use it and deploy your workloads on it. But deploying and maintaining a Kubernetes cluster itself can be a new challenge.
Amazon EKS abstracts away many complexities of running a Kubernetes cluster in AWS. It provides a fully managed Kubernetes control plane that you can provision by invoking a single AWS API. In response, you’ll receive an upstream Kubernetes api-server endpoint that enables you to connect to the new Kubernetes cluster and consume it.
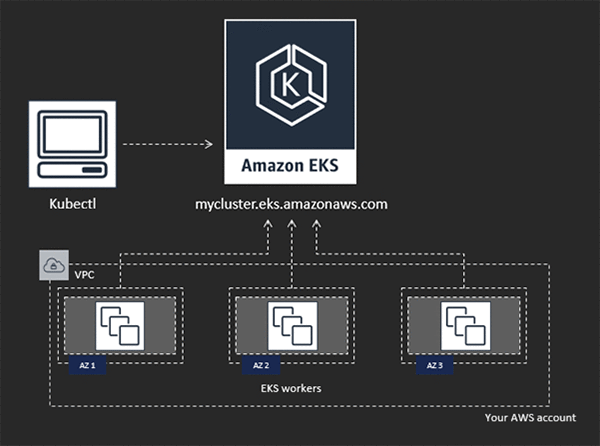
SQL Server is deployed as a single container in each pod (that is, a group of containers that always run together). Multiple instances of SQL Server can be deployed as multiple pods. Kubernetes schedules these pods on any node in the cluster that has sufficient resources available to run it.
To run SQL Server on Kubernetes, you have to create a Kubernetes deployment. This deployment creates a ReplicaSet that is owned and managed by the deployment. The ReplicaSet ensures that a single pod composed of a single SQL Server container will always run on the cluster. Of course, you could also deploy multiple instances of SQL Server on the same cluster to achieve high density.
The storage consumption is also abstracted from storage creation. For Kubernetes, a Persistent Volume (PV) is an object that encapsulates the implementation details of a storage solution. This could be an Amazon EBS volume, a network file system (NFS) share, or other solutions. The lifecycle of a PV is independent from the lifecycle of the pod that uses it.
To consume a PV, another object known as a Persistent Volume Claim (PVC) is created. The PVC is a request to use storage with a specific size and access mode (read/write). A PVC can also specify the Storage Class value. The Storage Class is another abstraction that enables you to define other properties of a storage solution, such as latency and IOPS.
An administrator would have to define a specific Storage Class such as AWS general purpose GP2 EBS volumes or Portworx high or medium I/O volumes. Operators could then create a PV based on that Storage Class or allow users to dynamically create PVs based on PVCs. Applications can then include a PVC that assigns the PV to a particular pod. To make this process easier, you can define a default Storage Class. For example, suppose that an Amazon EBS General Purpose SSD (gp2) volume is defined as the default Storage Class in a Kubernetes cluster. Even if a PVC does not include a specific Storage Class annotation, Kubernetes automatically annotates it with the AWS GP2 EBS Storage Class.

Storage options
Storage is a critical part of any SQL Server deployment. The most common storage option for SQL Server on AWS is using EBS volumes. There are two Storage Classes available for direct use of EBS volumes in a Kubernetes cluster:
- Aws-gp2 provides a solution for balancing cost and performance.
- Aws-io1 is recommended for production workloads that need a consistent IOPS and throughput.
You could directly store SQL Server files on EBS volumes. However, in many cases, a single EBS volume would not satisfy requirements. For example, you might require high availability in a Multi-AZ architecture, storage capacity beyond the single EBS volume limit, or throughput and IOPS more than what you can achieve with single volumes. You could use SQL Server Always On availability groups to address the high-availability problem, but it wouldn’t solve capacity, IOPS, and throughput problems. Also remember that the Always On availability groups feature for SQL Server containers is currently in preview with SQL Server 2019.
You can satisfy all of these requirements (HA, capacity, IOPS, and throughput) by combining several EBS volumes into a storage pool, striping volumes in each EC2 instance, and stretching the storage pool across multiple instances in separate Availability Zones. You can implement a separate storage cluster and then use it in the Kubernetes cluster through the NFS Storage Class. But all of this would introduce additional complexity and overhead.
Portworx cloud-native storage
Portworx is a storage clustering solution that serves applications and deployments in Kubernetes clusters. Furthermore, Portworx is itself deployed on top of Kubernetes. In other words, Portworx uses the power of Kubernetes to abstract away all the complexities of managing a storage cluster. It provides a simple Storage Class that is usable by any stateful application in a Kubernetes cluster.
In AWS, Portworx does this by claiming EBS volumes that are attached to the worker nodes of a Kubernetes cluster (EC2 instances). It then throws all of those volumes into an abstract storage pool and carves logical volumes out of that pool. When an application like SQL Server creates a PVC with a Portworx Storage Class and specifies volume size, a Portworx PV of specified size is assigned to the application.
Portworx can also create live snapshots, called 3DSnaps. With this capability, you can create consistent snapshots from SQL Server volumes without having to stop SQL Server or put it in read-only mode. Another useful feature in Portworx is its ability to import existing EBS volumes into Portworx logical cluster volumes. This makes migrating existing workloads easier. And with Portworx, clusters can be highly dense, meaning that you can run a lot of containers per host. The recommendation from Kubernetes is 100 pods per VM. Portworx has customers who run 200–300 pods per host.
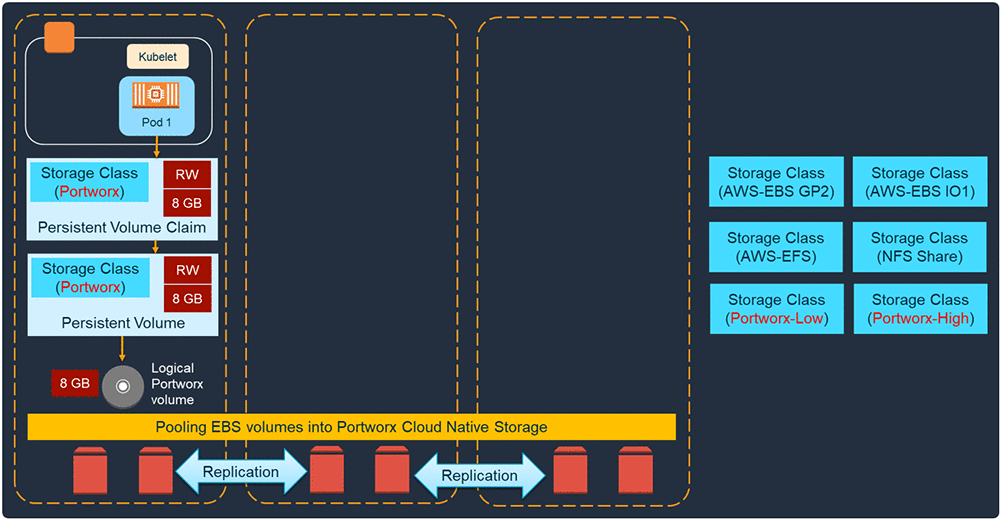
Portworx uses its own fine-grained snapshot layer on top of EBS volumes.
Portworx snapshot creation and restore are instantaneous. This is because Portworx snapshots are re-direct-on-write snaps. In essence, Portworx can instantaneously construct a point-in-time snapshot of the volume through a bookmark. Because the actual storage blocks are not copied, there is no write penalty regardless of the amount of snaps taken. You can take a new snap as frequently as every 15 minutes with no performance degradation. It does all this across multiple EBS volumes, cluster-wide, and with an app-consistent view.
Portworx allows resizing of virtual volumes. You can use this feature in combination with EBS elastic volumes to dynamically expand or shrink storage and avoid the extra costs associated with over-provisioning. Portworx snapshots by nature do not consume extra space. This is because the underlying storage method is redirect-on-write with a B-tree–based file system where Portworx can keep track of multiple versions of data for the same block. Therefore, these snapshots are very space efficient.
You can use Portworx cloud snapshot policy to automatically upload all snaps to an Amazon Simple Storage Service (S3) bucket and clean up the local snapshots. This capability helps prevent the EBS volume space from getting consumed by the lingering snapshots. Portworx also has a local snapshot retention policy that can retain a specified number of snapshots. This policy can be per-volume, and it can be dynamically configured during volume creation time or updated later. Amazon S3 is an object storage service that provides 99.999999999 percent durability. Portworx snapshots that are uploaded to Amazon S3 include actual storage blocks rather than just bookmarks. Therefore, it can act as another layer of protection against data loss.
For local snapshots, restore operations are instantaneous. For cloudsnaps, the restore operations might still be instantaneous, because Portworx only stores the snap-diffs in the Amazon S3 bucket.
In terms of performance and latency, Portworx logical volumes are accessed locally by each pod. In the background, Portworx replicates blocks to other worker nodes in other Availability Zones. This enables pods that fail over to another Availability Zone to immediately access data locally again and resume their operations.
Portworx has customers who run large-scale databases like Cassandra and Elasticsearch with hundreds of terabytes of data on AWS successfully. These customers realize the cost benefits of running Portworx on top of EBS. For more information about all the features that Portworx offers, read about the features on the Portworx website.
We have so far explained how you can use Amazon EKS and Portworx storage together as a reliable and flexible solution for hosting SQL Server workloads. The next section takes you through several steps that help you actually deploy SQL Server on Amazon EKS. You can use these instructions to quickly deploy this solution and examine it in your own environment.
Prerequisites
This solution is based on a PowerShell script. It can run on both Windows PowerShell and PowerShell Core. If you intend to run the script on a Windows 10 or Windows Server 2016, you can use the existing Windows PowerShell. You can also run this script on a MacBook or Linux machine. To do that, first you would have to install PowerShell Core on your target device. Alternatively, Mac users can use the instructions in the ReadMe file to deploy a local Docker container including all the pre-requisites.
The script invokes PowerShell cmdlets available in AWS Tools for PowerShell. Make sure that the latest version of either AWS Tools for Windows PowerShell or AWS Tools for PowerShell Core is installed on your machine.
The script occasionally relies on the AWS Command Line Interface (AWS CLI) tool to invoke Amazon EKS APIs. Make sure that you have installed the latest AWS CLI.
Finally, you need to have the required permissions in your AWS account to run this script. This includes running AWS CloudFormation templates, creating virtual private clouds (VPCs), subnets, security groups, and EC2 instances, and deploying and accessing EKS clusters. You can use an IAM user with a pair of long living programming keys on your computer. In this case, you’ll have to enable AWS profile using your programming keys on both PowerShell and the AWS CLI.
Alternatively, you could also use an IAM role with all the required privileges assigned to an EC2 instance where you would run the script. With this option, no further configuration is required, and both the AWS PowerShell tools and the AWS CLI automatically get temporary credentials from the EC2 instance metadata.
Optionally, the package includes a Dockerfile, which builds the script and all of the above dependencies (AWS CLI, AWS cmdlets, etc.) directly into the microsoft/powershell Docker image. This means that you can just use docker run to set up the environment whether you are on macOS, Linux, or Windows, as long as you have Docker installed.
Deploying SQL Server on Amazon EKS
You can deploy SQL Server by running the included script and passing the required parameters. The script includes many parameters, but most of them have default values defined to make it easier for first-time users. It is also safe to run the script multiple times with the same parameters. It checks whether the underlying resources already exist, and if available, reuses them.
Here is a list of steps that the script performs:
- First, it creates an IAM service role for Amazon EKS. This role is required to allow EKS to provision necessary resources in AWS on your behalf.
- You need a VPC to run your cluster on. The script receives an AWS CloudFormation VPC stack name as a parameter. If the stack already exists, it reuses the same stack. Otherwise, it creates a new stack from a template provided by AWS. The stack includes the VPC, subnets, and security groups needed to run the cluster.
- You configure and interact with Kubernetes through a client tool called kubectl. The script downloads the AWS curated version of kubectl and installs it on your local computer.
- When you use kubectl to query Amazon EKS, the same AWS credentials used by your AWS PowerShell tools are passed to Amazon EKS. This task is performed by another tool called the aws-iam-authenticator, which is downloaded and installed by the script.
- It creates a new EKS cluster. The EKS cluster consists of a managed set of three master nodes in three AWS Availability Zones.
- It configures kubectl to connect with the EKS cluster created in the previous step.
- It launches new EC2 instances and configures them to join the EKS cluster and worker nodes.
- It launches an Etcd cluster for Portworx to communicate with.
- It then downloads a DaemonSet specification and applies that to the EKS cluster. This automatically installs Portworx cloud native storage with GP2 and IO1 EBS volumes, giving the user the option to choose either or both.
- It creates a Storage Class for Portworx volumes with a replication factor of 3 inside the EKS cluster. This is how you maintain a highly available SQL Server cluster in the event of a host failure, even if Kubernetes reschedules your SQL Server pod to another Availability Zone.
- It creates a Storage Class for gp2 EBS volumes inside the EKS cluster.
- It creates a new Persistent Volume Claim (PVC) inside the EKS cluster. The PVC allows Portworx to provision Persistent Volumes (PV) backed by the underlying Amazon EBS volumes.
- It prompts you to enter a password for the SQL Server SA user. Enter a strong password that complies with the default SQL Server SA password policy. The script saves this password as a secret inside the EKS cluster.
- It then creates the SQL Server deployment. The deployment includes a replica set, which in turn creates Kubernetes pods. The pod is composed of a single container that runs SQL Server. The PVC volumes are mounted on this container, and the SA password is used to spin it up.
- In the end, it outputs the endpoint name that can be used in connection strings to connect to your SQL Server instance.
Running the script once deploys the EKS cluster and a single SQL Server instance on top of it. You can deploy additional instances of SQL Server on the same EKS cluster by running the same script again and passing a different name for the appName parameter.
High availability
This script deploys SQL Server using a Multi-AZ Kubernetes cluster and a Storage Class (SC) that is backed by Portworx volumes. Thanks to Portworx protection and replication of data within the SQL Server container, the deployment is resilient against the following:
- Container failures
- Pod failures
- EC2 instance failures
- EC2 host failures
- EBS disk failures
- EC2 network partitions
- AWS Availability Zone failures
If a container or pod fails, Kubernetes immediately schedules another container or pod. Even if the Kubernetes pod is rescheduled to a different Availability Zone, you will not suffer any data loss because Portworx automatically replicates data across Availability Zones.
In the previous section, we noted that the Portworx replication factor was set to 3. This means that in addition to our primary PV, Portworx always maintains two additional copies of the PV elsewhere in the cluster. Because Amazon EBS volumes are highly available only within a single Availability Zone, by default, Portworx spreads these replicas across multiple Availability Zones. The big improvement is that when deployed on premises, usually a SQL Server failover clustering instance (FCI) is deployed in a single data center. However, here the Kubernetes and Portworx clusters are spread across multiple Availability Zones. Therefore, the level of availability and resilience is much higher.
Running SQL Server containers in Kubernetes on top of a clustered storage like Portworx is akin to running SQL Server Always On FCI on top of a Storage Spaces Direct cluster that is spanned across multiple Availability Zones. The result is a Recovery Point Objective (RPO) of zero and a Recovery Time Objective (RTO) of less than 10 minutes with resilience against any possible major Availability Zone failures. The difference is that running containers in EKS is even easier than configuring and maintaining SQL Server on top of a Windows Server Failover Cluster.
If you run SQL Server Standard edition, you can also attain higher levels of availability using containers and Amazon EKS as opposed to a traditional Windows deployment. This is because SQL Server Standard edition FCI is limited to a maximum of two nodes (that is, one secondary node). However, containers can be deployed on a cluster composed of any number of nodes. SQL Server Always On FCI with Enterprise edition can go beyond two nodes. But depending on your licensing agreements, you might have to procure licenses for each additional instance. This is not the case with containers. You only pay for one container, regardless of the number of standby instances in your cluster.
It is also possible to deploy SQL Server containers with Always On availability groups (currently in preview with SQL Server 2019). Such a configuration is similar to deploying Always On availability groups where each participating node is itself an Always On FCI cluster. However, some of the cumbersome limitations of Always On availability groups and FCI are no longer imposed on containers. For example, these limitations include the automatic failover from one node of an availability group to a secondary and the complexity of setting up a distinct FCI for each node.
SQL Server containers licensing
According to the SQL Server 2017 Licensing Datasheet: “SQL Server 2017 offers use rights for virtual machines and containers, to provide flexibility for customers’ deployments. There are two primary licensing options for virtual machines and containers in SQL Server 2017—the ability to license individual virtual machines and containers and the ability to license for maximum densities in highly virtualized or high-density container environments.”
There are opportunities to cut down licensing costs using containerization of SQL Server workloads. You can apply both the per-container licensing model and the per-physical host licensing model (high density) in certain scenarios to reduce the number of licenses required.
If you have several applications running on an EC2 instance and want to run SQL Server side by side with those applications on the same host, you can use per-container licensing. Without containers, if you run SQL Server directly on a virtual machine, including any EC2 instances, you would have to procure licenses for all the vCPUs that are available in that VM. This is regardless of how many of those vCPUs are indeed used by SQL Server. However, if you run SQL Server in a container on the same VM, you can limit the number of vCPUs that are accessible by your container. You can then get licenses only for the number of cores that are accessible. This would be a minimum of four cores with two core increments, that is, four, six, eight, etc.
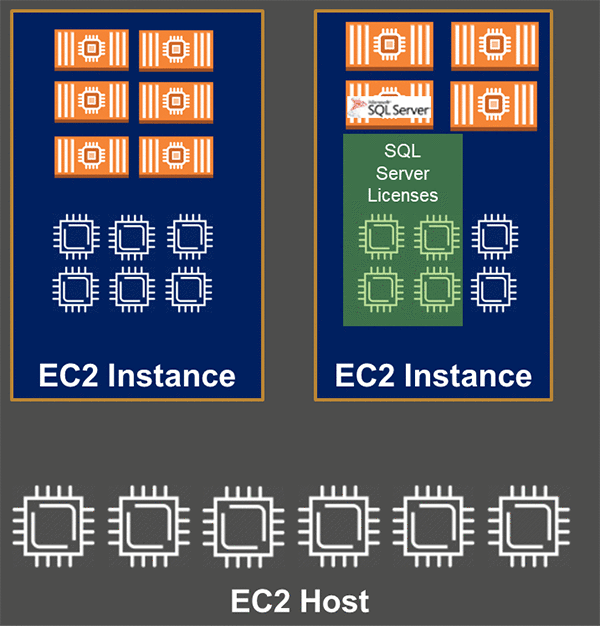
If you have a fleet of SQL Server instances with spiky utilization patterns, you can run them in high density using containers. In this case, you should choose the per-physical host licensing model. As long as all the physical cores are properly licensed, it would allow you to run an unlimited number of containers and any number of vCPUs on top of those physical cores.

In the preceding diagram, there are 12 vCPU cores and 20 containers. But because all of these are running on top of six physical cores, only six core licenses are required. This is particularly useful for those businesses that have overprovisioned their SQL Server virtual machines on premises. EC2 instances have a fixed hyperthreading ratio of two vCPU per one physical core. So moving overprovisioned workloads with a ratio of 3:1, 4:1, 5:1, or higher directly into EC2 instances would introduce a higher total cost as a deterring problem. Containerization not only solves that problem, but also potentially improves the outcome.
Portworx licensing
Portworx supports high-density container environments with a complementary licensing model. Kubernetes itself recommends a maximum of 100 pods per node. So theoretically, you can run up to 100 SQL Server pods per EC2 instance, saving significantly on SQL Server licenses. Portworx only requires one license per EC2 instance, regardless of how many containers are running or how much storage you consume. So for dense clusters, you are not simply trading one license for another. In fact, the more SQL Servers you run per host, the more you save on average license costs. Portworx supports thousands of nodes per cluster and hundreds of stateful containers per node.
When not to use SQL Server containers
With currently released capabilities, not all SQL Server workloads can be containerized. First and foremost, SQL Server containers are currently available only for SQL Server 2017. Any older version of SQL Server cannot be containerized. However, SQL Server 2017 is backward compatible with all versions newer than and including SQL Server 2008. This means that you can restore a database created in SQL Server 2008 or newer inside an instance of SQL Server 2017 (including those that run in a container) and run it in compatibility mode.
Furthermore, although SQL Server on Linux supports integration with Microsoft Active Directory, SQL Server containers currently do not support Active Directory integration.
A commonly used feature of SQL Server is its horizontal read-scaling capability that is available through Always On availability groups. This feature is currently available for containers as a preview and can’t be used in production.
One of the most appreciated possibilities brought about by the cloud is License Included services. For many businesses, managing their procured licenses against their actual software consumption is an onerous overhead. It can lead to discrepancies, in the form of either paying for what they never use or noncompliance with a vendor’s use-terms. SQL Server containers are exclusively available with the Bring Your Own License (BYOL) model. Therefore, you should consider the burden of managing licenses before making a decision.
There are also a few other features that are currently not available, such as Distributed Transaction Coordinator (DTC) and custom CLR user types. If your SQL Server workloads have a fairly consistent static resource utilization pattern, you might find traditional deployment models more reliable.
Conclusion
In this post, we discussed why you should consider running SQL Server with Portworx in containers and described the pros and cons of this approach.
This approach has the following benefits:
- It is simple and can help remove some of your administrative burden.
- It can improve the performance of your applications by unlocking idle resource capacity to those workloads that need it.
- It can improve the data protection and failover capabilities of your deployment.
- It can reduce your infrastructure costs.
- It can reduce your SQL Server licensing costs.
This post shows how easy it is to deploy SQL Server on Amazon EKS with Portworx. You can provision the infrastructure and EKS cluster and run the SQL Server container using a simple script that invokes AWS APIs. Based on your specific requirements, you can choose from mainly two storage options:
- Using Individual EBS volumes as a PVC, providing HA in a single Availability Zone and incurring minimal storage costs.
- Using a clustered storage solution such as Portworx across multiple Availability Zones, providing a level of HA that’s resilient against Availability Zone failures.
About the Authors
 Sepehr is currently a Senior Solutions Architect at AWS. He started his professional career as a .Net developer, which continued for more than 10 years. Early on, he quickly became a fan of cloud computing and loves to help customers utilise the power of Microsoft tech on AWS. His wife and daughter are the most precious parts of his life, and he’s expecting a second baby soon!
Sepehr is currently a Senior Solutions Architect at AWS. He started his professional career as a .Net developer, which continued for more than 10 years. Early on, he quickly became a fan of cloud computing and loves to help customers utilise the power of Microsoft tech on AWS. His wife and daughter are the most precious parts of his life, and he’s expecting a second baby soon!
 Ryan Wallner, Technical Advocate for Portworx focused on the Kubernetes container storage ecosystem. Previously, Ryan was a Technical Member at Athenahealth building a microservices platform on DC/OS, Before that, he worked for ClusterHQ and EMC’s office of the CTO. He has contributed to various open-source projects including Flocker, Amazon ECS Agent, BigSwitch Floodlight, Kubernetes, and Docker-py.
Ryan Wallner, Technical Advocate for Portworx focused on the Kubernetes container storage ecosystem. Previously, Ryan was a Technical Member at Athenahealth building a microservices platform on DC/OS, Before that, he worked for ClusterHQ and EMC’s office of the CTO. He has contributed to various open-source projects including Flocker, Amazon ECS Agent, BigSwitch Floodlight, Kubernetes, and Docker-py.