AWS Database Blog
Reading Amazon S3 Data from Oracle on Amazon EC2
When you’re working with AWS services, Amazon S3 is the first choice to store text data files. In the past, to access S3 data, first you’d download the files and then perform extract, transform, and load (ETL) to load the data into Oracle.
This approach has two drawbacks. It takes time to download and perform ETL. Also, we waste space on the Oracle database by loading the S3 data.
Oracle offers an external table feature in version 11g. With this feature, you can keep data outside the database, in a file system that is locally available to your database instance. In contrast, S3 bucket storage isn’t locally available to your database instance.
To make external tables work in the past, we’d copy files from S3 to storage locally present in a database instance. But recently, AWS introduced the file gateway feature for AWS Storage Gateway. This feature makes S3 buckets available locally to an Amazon EC2 instance as NFS mounts. By using a file gateway with an Oracle external table, we can read S3 data directly from Oracle. This approach saves ETL time, avoids file movements, and saves database space.
Let’s do an example of this setup. The end result will be a service mimicking Amazon Redshift Spectrum. As data to use, we’ll work with the public data of all airline flights’ on-time performance in the US from 1987 to 2008, found on the Statistical Computing Statistical Graphics website.
You can upload all the data (on-time and supplemental data) into a S3 bucket. In this example, we have uploaded into the jvs-publicdata S3 bucket.
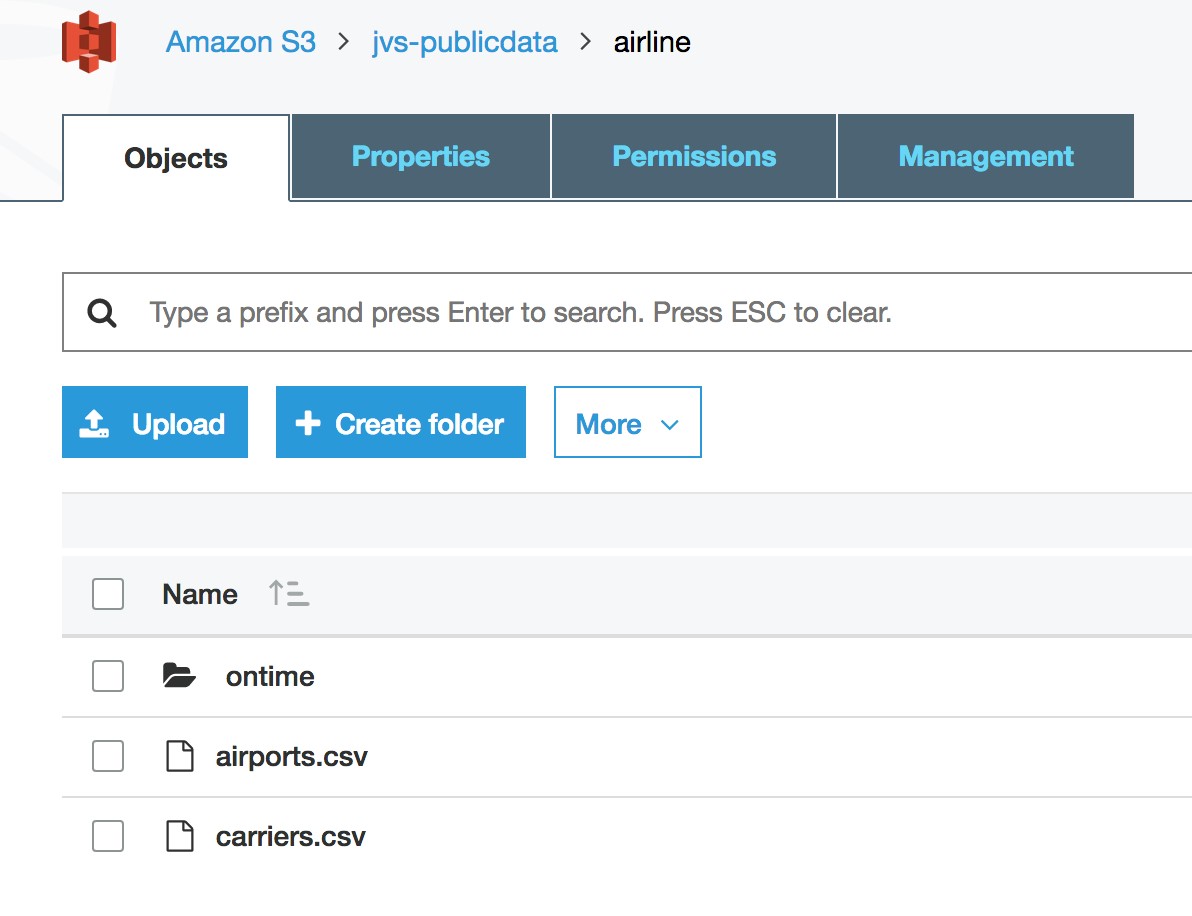
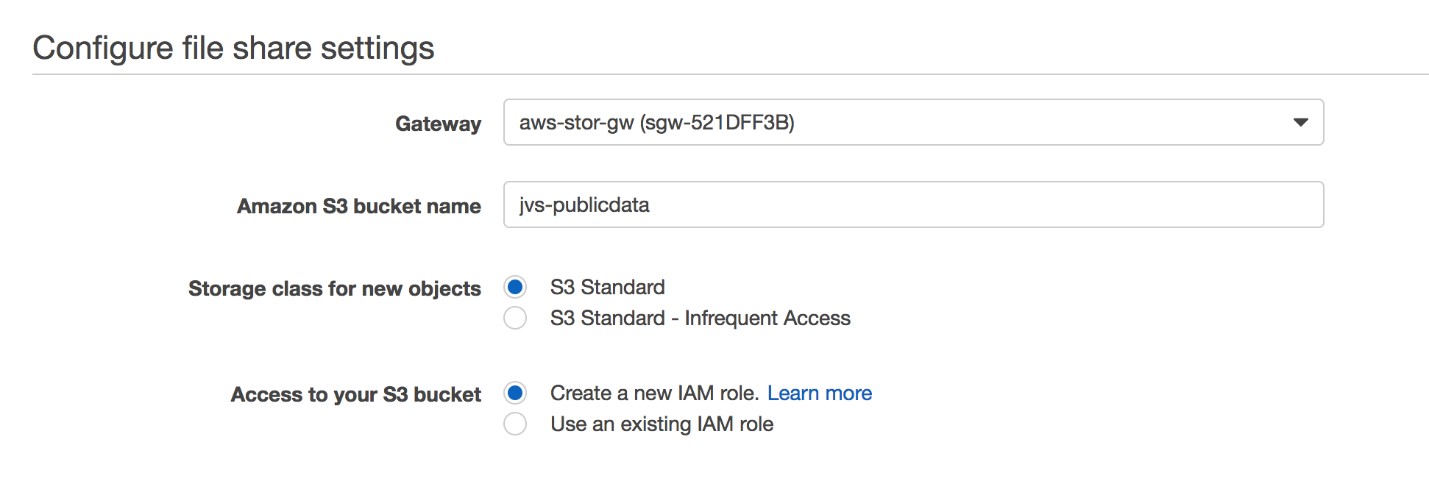
Let’s create a Storage Gateway file share for the jvs-publicdata S3 bucket. If you want to know more about how to set up and configure AWS Storage Gateway, read this blog post by Jeff Barr.

Logging into the EC2 server for the Oracle database, let’s mount the NFS share as shown following.
These airline data files are directly stored in S3. Thus, they don’t have assigned Unix users. Instead, the user nfsnobody appears as the Unix user, because it’s the NFS file share default for Storage Gateway. You can read about NFS file share default values in the Storage Gateway documentation.
As a next step, log in to Oracle database as the database user who needs to read the S3 data. Create a database directory at the SQL prompt as shown.
You need to create a separate Oracle database directory to access every level of the directory path. If CREATE DIRECTORY permissions are missing for the user, ask DBA to grant the following privilege.
Now, let’s go ahead and create external tables in Oracle.
Because each text file contains headers, we skip the header row with the SKIP 1 clause.
The ontime airline .csv files contain “NA” for null values. We use NULLIF at table level to replace text “NA” with null values. This enhancement feature is available in Oracle 12c. If you are using Oracle 11g, define the column as CHAR or VARCHAR2. Later, you can transform the data later while loading it into another table.
Now, run the following SQL queries to read directly from S3.
The performance of the read operations depends on several factors. These factors include the size and number of files, NFS performance, whether the S3 bucket is located in the same AWS Region as the Storage Gateway EC2 instance, and whether caching occurs at the Storage Gateway level.
The size of the database server EC2 instance and the Storage Gateway EC2 instance influence network performance. Each EC2 instance has a defined class of network bandwidth. Choose the correct EC2 instance sizes to optimize read operations on large data files. Read more about optimizing Storage Gateway performance in the AWS documentation.
As we’ve shown, you can use a file gateway in AWS Storage Gateway to save time from ETL loads from S3 to Oracle database, and save Oracle database space.