AWS Database Blog
Single-table vs. multi-table design in Amazon DynamoDB
This is a guest post by Alex DeBrie, an AWS Hero.
For people learning about Amazon DynamoDB, the idea of single-table design is one of the most mind-bending concepts out there. Rather than the relational notion of having a table per entity, DynamoDB tables often include multiple different entities in a single table.
You can read the DynamoDB documentation, watch re:Invent talks or other videos, or check out my book to learn some of the design patterns with single-table design in DynamoDB. I want to look at the topic at a higher level with a specific focus on arguments both for and against single-table design.
In this post, we’ll talk about single-table design in DynamoDB. We’ll start off with some relevant background on DynamoDB that will inform the data modeling discussion. Then, we’ll discuss when single-table design can be helpful in your application. Finally, we’ll conclude with some instances where using multiple tables in DynamoDB might be better for you.
Relevant background on DynamoDB
Before we get too far into the merits of single- vs. multi-table design, let’s start with some background on DynamoDB. We don’t have room to exhaustively cover everything here, but I want to hit a few points that are relevant to the single- vs. multi-table debate.
As we cover these, there’s one overarching theme that ties them together: DynamoDB wants to expose reality to you, so that you can make the right decision for your application’s needs. Most databases provide an abstraction over the low-level bits. These abstractions make it easier for you to query your data in flexible ways, but they also hide important details from you. Because these details are hidden, these databases can scale in unpredictable ways or make it difficult to understand what your database will cost as usage grows.
With that in mind, let’s review some distinctive features of DynamoDB.
Reliance on two core mechanisms for consistent scaling
Above all else, DynamoDB wants to provide consistent performance as your application scales. No matter the size of your database or the number of concurrent queries, DynamoDB aims to provide the same single-digit millisecond response time for all operations.
To do this, DynamoDB relies on two core mechanisms: partitioning and the B-tree. With these solid foundations, DynamoDB is able to scale tables to petabytes of data and millions of concurrent queries.
Let’s start with partitioning. In a traditional relational database, you store all items on a single node. As your data or usage grows, you might increase your instance size to keep up. However, vertical scaling has its limits, and often you find that the performance of relational databases degrade as data size increases.
To avoid this, DynamoDB uses partitioning to provide horizontal scalability. Each item in your DynamoDB table will include a partition key. Under the hood, DynamoDB is sharding your database into segments called partitions (as shown in Figure 1 that follows), each of which holds a maximum of 10 GB of data.
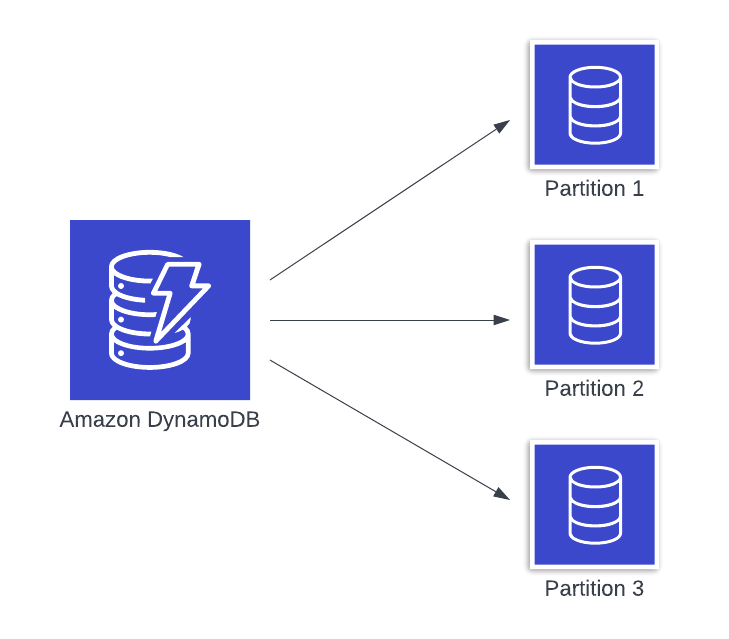
Figure 1: DynamoDB database sharded into three partitions
When a request comes to DynamoDB, the request router layer looks up the location of the partition for the given item and routes the request to the proper partition for processing, as shown in Figure 2 that follows.

Figure 2: Request routed to the appropriate partition for processing
As your table grows, DynamoDB can seamlessly add new partitions and redistribute your data to scale with your workload. The metadata subsystem retains a mapping of partition key ranges to storage nodes and can quickly route your request to the relevant partition.
While partitioning enables horizontal scaling, we often need to fetch a range of related items in a single request. That’s where DynamoDB’s second core mechanism comes in. A B-tree is an efficient way to maintain sorted data. This is useful in many data applications, such as sorting usernames in alphabetical order or sorting e-commerce orders by the order timestamp.
DynamoDB stores the items on each partition in a B-tree that are ordered according to their partition key and (if used by the table) sort key. This B-tree provides logarithmic time complexity for finding a key. This use of a B-tree on subsets of your data allows for highly efficient range queries of items with the same partition key.
Direct access to the data structures with a focused API
Partitioning and B-trees are interesting, but they’re hardly unique to DynamoDB. Every NoSQL database uses some form of partitioning to horizontally scale, and every database under the sun uses B-trees (or close relatives) in indexing operations.
The big difference between DynamoDB and other databases is how natively DynamoDB exposes these data structures to you. There’s no query planner to parse your query into a multi-step process to read, join, and aggregate data from different places on disk. And there are no flexible indexing strategies outside the core partitioning and B-tree setup.
DynamoDB has a focused API that gives you direct access to your items and their foundational data structures. This API is broken into two main categories. There are basic CRUD operations on individual items—PutItem, GetItem, UpdateItem, and DeleteItem. These operations require the full primary key, and you can consider them to be equivalent to a simple lookup in a hash table.
The second category of the DynamoDB API includes the Query operation, a fetch many operation that allows you to retrieve multiple items in a single request. You can use this to fetch all Orders for a particular Customer or to fetch the most recent Readings for an IoT Sensor.
But even the Query operation is locked down, as you must provide an exact match on a partition key so that it can be routed to a single partition to service the request. It combines the fast targeting based on the partition key with the quick search and easy sequential reads of a B-tree to provide an efficient range query as you scale.
Note what isn’t provided by the DynamoDB API. You can’t use the JOIN operation to combine multiple tables, like you can in a relational database. Nor can you use aggregations like count, sum, min, or max to condense a large number of records. These operations are opaque and highly dependent on the number of records affected by the query, which cannot be known in advance. In order to provide consistent performance at any scale, DynamoDB removes higher-level constructs like joins and aggregates that add significant variability.
Transparent billing based on bytes read and bytes written
In the previous section, we saw that DynamoDB makes performance transparent to you by building on key data structures and exposing them directly to you. In doing so, it removes the magic and unpredictability of databases that use opaque query planners.
DynamoDB does the same thing with costs. It costs to write data to disk. It costs to read data back from disk. And both of these costs increase with the size of the data you’re reading or writing. DynamoDB makes these underlying costs legible to you by billing you directly on the bytes you’re writing to and reading from your table.
DynamoDB’s billing is based on write capacity units (WCUs) and read capacity units (RCUs). At a quick glance, one WCU allows you to write 1 KB of data, while one RCU allows you to read 4 KB of data. You can provision read and write capacity units in advance, or you can use on-demand billing to pay for each read or write request as it comes in.
I love this transparency. One thing I always tell people working with DynamoDB is “Do the math.” If you have a rough estimate of how much traffic you’ll have, you can do the math to figure out what it will cost you. Or, if you are deciding between two approaches to model the data, you can do the math to see which one is cheaper.
As we’ll see in the following section, this transparent billing model is one reason to use single-table design principles in your data modeling.
Why and when to use single-table design
So now that we know some basics about DynamoDB, let’s see why you might want to use single-table design in your application.
Before we start, I want to note that the recommendation for single-table design applies to a single service. If you have multiple services in your application, each of them should have their own DynamoDB table. You should think of a DynamoDB table similar to an RDBMS instance—everywhere you would have a separate RDBMS instance, you should have a separate DynamoDB table.
Additionally, if there’s a rule of thumb for when to combine entities in a single table, it’s this: Items that are accessed together should be stored together. If you store data in two different tables in an RDBMS and frequently join these two tables, you should consider storing them in a single, denormalized DynamoDB table. If not, you’re generally fine to separate them if you choose.
There are three functional reasons to use single-table design with DynamoDB, plus one non-functional, bonus reason. Let’s look through them now.
Use single-table design to provide materialized joins in DynamoDB
In the background section, we saw that DynamoDB has a focused API and that it removes common SQL operations like JOINs.
But joins are useful! If I have a one-to-many or many-to-many relationship, I might have an access pattern where I’m fetching one item but also need some information about a related parent item.
When I first started with DynamoDB, I used a multi-table system that was similar to relational databases. Because DynamoDB doesn’t provide joins out of the box, I just implemented joins in my application code. For example, imagine I wanted to fetch both a Customer and the Customer’s Orders for a particular access pattern. To do so, I would fetch the Customer record first, get its primary key, and then fetch the related Orders with a foreign key relationship.

Figure 3: Fetching information from a multi-table design
But this is an inefficient way to handle this use case. The I/O from my application to DynamoDB is the slowest part of my application’s processing, and I’m doing it twice by issuing two, separate, sequential queries, as shown in the preceding Figure 3.
If I know that this will be a common access pattern in my application, I can lean on DynamoDB’s core data structures and API to optimize that. Rather than making separate, sequential requests, I can pre-join related items and materialize the join in advance. If I give the Customer item the same partition key as the related Order items, they’ll be located on the same partition and be ordered according to the sort key. Then, I can use the Query operation to fetch all the items in a single, efficient request, as shown in Figure 4 that follows.

Figure 4: Fetching information from a single-table database
This is the canonical example for using single-table design. We can handle access patterns that involve heterogeneous items while still getting the consistent performance we expect from DynamoDB.
Use single-table design to reduce costs across large items
A second reason to use single-table design principles is to reduce your DynamoDB costs.
In many NoSQL systems, you’re encouraged to create larger, denormalized documents that contain related, nested data. This is in recognition that you often fetch related data together, and it can be more efficient to keep the data together as a single record rather than separate records.
While this strategy can be good advice, be careful not to take it too far. Remember that DynamoDB makes costs legible to you and that read and write costs scale with the size of the item.
It’s common to have a large item with two distinct sets of attributes: some large, slow-moving attributes combined with small, fast-moving attributes. For example, think of an item representing a video on YouTube. There is a lot of data about the video itself, such as the various resolutions available and their locations, the video description, subtitles, and info cards. This is a lot of information, and it rarely changes.
However, a YouTube video also has a counter displaying the number of views for a video. This is a tiny attribute—a few bits of data—but it might increment thousands of times per day. If you stored this counter on the same item as the video metadata, you might be paying multiple WCUs every time you want to increment the view count. This pattern is shown in Figure 5 that follows.
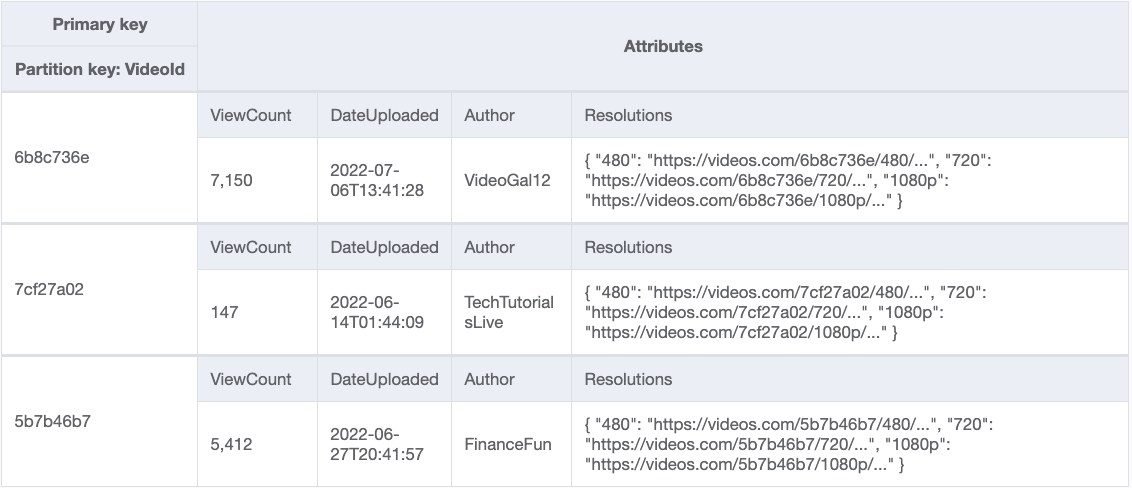
Figure 5: Incrementing the ViewCount attribute as part of the item metadata
Instead, you could break this item into two items: a Video item and a VideoStats item. When recording a view, you would only be incrementing the small VideoStats item. When displaying the video, you could fetch both items using the Query operation, as shown in Figure 6 that follows.
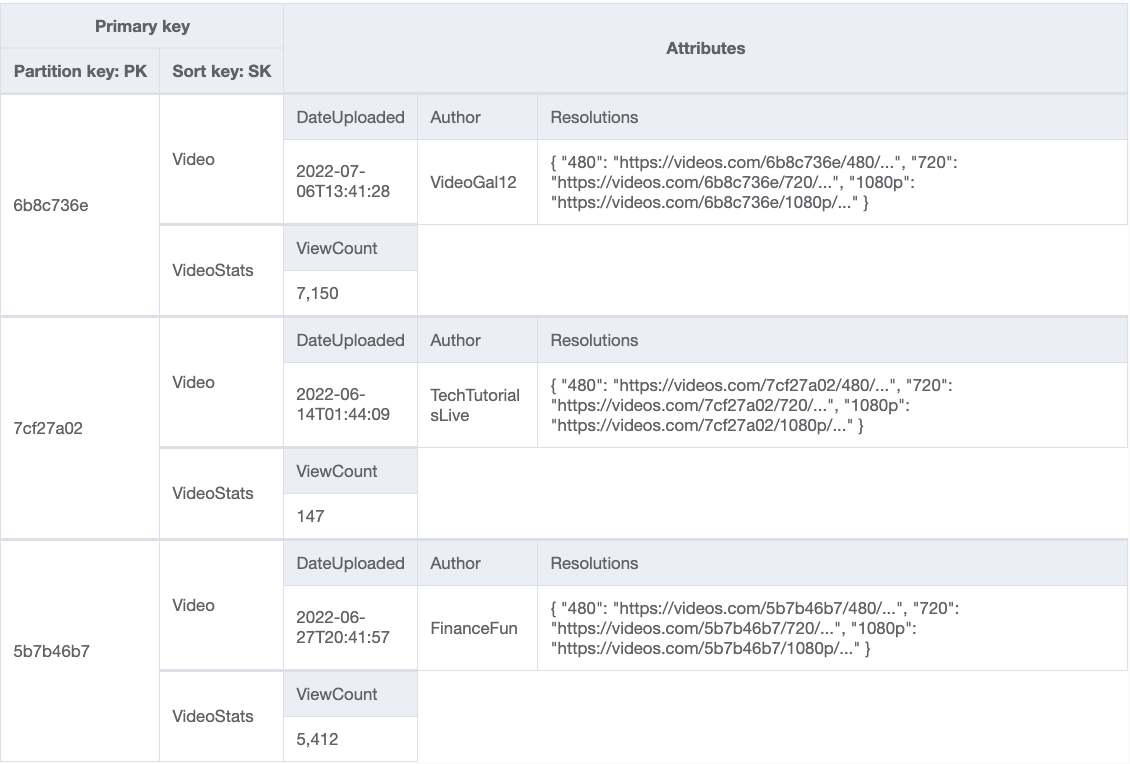
Figure 6: Incrementing the ViewCount attribute separately from the metadata
With this pattern, we can use DynamoDB’s transparency on costs and schemaless nature to optimize for our application needs.
Use single-table design to reduce your operational burden
A third reason to use a single DynamoDB table is to reduce your operational burden. The math here is simple—the fewer things you have, the fewer things you have to monitor! The logic here is a bit more complicated, particularly in light of improvements that AWS has made to DynamoDB.
Let’s start with the strong version of the argument. While a DynamoDB table has some things in common with a table in a relational database, there are a number of differences, too. Most importantly, each DynamoDB table is a separate piece of infrastructure. That infrastructure requires configuration, monitoring, alarms, and backups. If you have 15 different entities in your application and thus 15 different DynamoDB tables, it can become a burden.
By combining your data into a single table, the logic goes, your operational burden is reduced. You only need to monitor one table rather than 15. Additionally, there are AWS limits to the number of tables in an AWS Region plus the number of concurrent control plane operations. If you have a large account or are doing table segmenting by customer, you can hit these limits.
Using a single table for multiple entities can even enhance your general table performance. DynamoDB provides burst capacity on a partition level that allows you to exceed your provisioned throughput for short periods on a best-efforts basis. If you have a larger table, your items will be distributed across more partitions and thus decrease the potential throttling blast radius.
Finally, it’s often true that a small number of your access patterns dominate the read and write capacity of your application. By combining your entities into a single table, your access patterns that are used less frequently can blend into the excess capacity of your core pattern.
That said, I think this argument is a small factor in my consideration. The maintenance on a DynamoDB table is pretty light, and it can mostly be automated via AWS CloudFormation or other infrastructure-as-code tools. You can configure auto-scaling, set up alarms, or enable backups via point-in-time recovery in an automated way.
Further, DynamoDB has made a number of improvements that reduce this argument even further. In 2018, DynamoDB announced adaptive capacity, which spreads your provisioning capacity across your table to the partitions that need it most. Then, in 2019, DynamoDB announced on-demand billing mode. If managing your capacity is a burden, you can switch to on-demand mode and only pay for the resources you need.
Bonus: it forces you to think about DynamoDB correctly
As someone who likes to help people learn DynamoDB and use it well, my last reason is (selfishly) about the learning process rather than any particular application or operational benefits. This argument goes as follows: the emphasis on single-table design in DynamoDB helps to nail home the message that modeling with DynamoDB is different than the modeling you’ve done in a relational database.
So many new DynamoDB users do what I did—lift and shift their relational data model into a bunch of DynamoDB tables. They then write a bad version of a query processor in their application by doing in-memory joins and aggregations. This approach leads to sluggish apps that don’t get the scalability and predictability that can be delivered by DynamoDB.
Telling people that most services can use a single table teaches that a DynamoDB table isn’t directly comparable to a relational database table. Users dig a little deeper and realize they need to focus on access patterns first, rather than an abstracted, normalized version of their data. They learn the key strategies for modeling NoSQL data stores to optimize performance.
On this same point, I think learning DynamoDB makes you a better developer. Because DynamoDB is exposing the foundations to you, you learn that some of the abstractions you were using before aren’t free. Even when going back to a relational database, you look harder at features like joins and aggregations, understanding that the performance profile isn’t the same as selecting a single record by an indexed field.
Reasons to use multiple tables in DynamoDB
In the previous section, we saw the core arguments in support of single-table design in DynamoDB. However, the choice between one table and multiple tables is nuanced, and there are situations where multiple tables might be a good choice for you. Let’s explore some of these below.
You have multiple needs for DynamoDB Streams
Amazon DynamoDB Streams is one of my favorite features of DynamoDB. I can get a fully managed change data capture stream that includes a record of every write operation against my DynamoDB table. Then, I can process that change stream with serverless compute to update aggregations, share events across systems, or feed analytics systems.
One of the downsides of DynamoDB Streams is the limitation on the number of concurrent consumers. DynamoDB limits you to no more than two concurrent consumers on a DynamoDB stream. If you have additional consumers, your stream processing requests will get throttled.
In a single-table design with ten or more entities, it’s not uncommon to exceed this limit. Perhaps a new Order item needs to trigger an AWS Step Functions workflow to process the Order, while a new Customer registration needs to broadcast the registration to other services via Amazon EventBridge. At some point, you need to make some hard tradeoffs, such as adding more logic to a single stream consumer or wiring up a system of FIFO SNS topics (using Amazon Simple Notification Service (Amazon SNS) and Amazon Simple Queue Service (Amazon SQS) queues to provide event fanout while retaining ordering semantics.
If this is the case, it might be easier to split your single table into multiple focused tables. Each table can hold a smaller number of entities and have a more focused DynamoDB stream pipeline.
You want an easier export for analytics
DynamoDB is an online transaction processing (OLTP) system that is designed for a high number of concurrent updates on individual records. Think of common user-facing interactions—placing an order or commenting on a discussion thread. It excels at these workloads, and it allows for atomic operations, low latency, and ACID transactions when working with a small number of records in a request.
Conversely, DynamoDB isn’t great at online analytical processing (OLAP) operations. These are internal analytics operations—think of a business analyst that wants to know the week-over-week sales by category and region or a marketing team that wants to find the most popular social media posts over the past year. These operations don’t need high throughput or low latency, but they do need to efficiently scan large amounts of data and perform computation.
For these OLAP needs, most DynamoDB users export their data to an external analytics system like Amazon Athena or Amazon Redshift that are purpose-built for large-scale aggregations. However, the mechanism for getting your data from DynamoDB to your analytics system can vary depending on the specifics of your data.
Some users use the DynamoDB Streams feature discussed above to stream records into their analytical database. Often, this involves using Amazon Kinesis Data Firehose to buffer the data in Amazon Simple Storage Service (Amazon S3) before loading into Amazon Redshift, or simply using Data Firehose to send to S3 to be queried by Athena. This pattern works better for larger, immutable datasets as a full export of the table can be infeasible and the immutable nature of the data works well with OLAP-type systems.
But some datasets are smaller and more mutable, and they have different needs. Think of the User or Customer entities in an application. These entities will be important in your data warehouse for joining with other, larger, event-like tables to give color to the events. Because these entities are mutable, we want our data warehouse to be regularly updated with the current version. Data warehouses don’t do well with random updates, so it’s usually better to export a full, updated table to load into your system. This usually uses either the Redshift COPY command or the DynamoDB export to S3 operation.
If you have both types of data in a single DynamoDB table, this can make it more difficult for your analytical needs. Doing a full table export will be slower as you’ll be exporting all of the larger, immutable dataset along with your smaller, mutable dataset. By splitting the different data into different tables, you can customize the analytics pipeline to the data’s specific shape and needs.
You don’t need the benefits, and it’s easier to reason about
The last reason to use multiple tables is mostly just a negation of the case for single-table design.
If none of the benefits of single-table design above matter to you—you’re not setting up materialized joins to fetch heterogenous items in a single request, or breaking up items into separate pieces, or intimidated by the operational burden—then it’s fine to skip single-table design if multi-table design is easier for you to reason about.
Let’s look a little deeper at the first benefit I mentioned above about modeling for joins in DynamoDB. It’s absolutely true that you want to avoid a normalized model that relies on in-application joins and multiple, sequential requests to DynamoDB. But that doesn’t necessarily mean we must use single-table design with materialized joins. We could get most of the same benefits by structuring our tables to fetch both sets of data in parallel, rather than sequentially.
Think back to our example above where we needed to make sequential requests to DynamoDB—one to fetch the Customer record by email address and another to fetch the Orders by an assigned CustomerID. When switching to a single-table design model, we gave both entities a partition key of CustomerEmailAddress so we could fetch them with a single Query operation.
This modeling switch doesn’t require two different tables. If our Orders table uses CustomerEmailAddress as the partition key, we can fetch the Orders records at the same time we’re fetching the Customer record.
This is slightly slower than making a single request, as you’ll be waiting for the slowest of the two requests to return. And you’ll pay a bit more, as you’re not getting the aggregation benefits of the Query operation in calculating your RCUs. But it’s likely you’ll need to implement something like this anyway, even in single-table design, for pagination instances where a client is fetching beyond the first page. If these tradeoffs are acceptable to you and your application, then you can opt for a multi-table design.
Note that this isn’t an excuse to avoid learning how DynamoDB works! You shouldn’t model DynamoDB like a relational database, and you should learn DynamoDB data modeling principles. In almost all models I’ve done over the years, we could combine two separate tables into a single table if needed because they focus on access patterns first and design the primary keys to handle those access patterns.
Conclusion
In this post, we learned about single-table design with DynamoDB. First, we started with some relevant background on DynamoDB that is important to the single table discussion. Then, we saw some reasons to use single-table design in DynamoDB. Finally, we looked at some reasons why you might want to use multiple tables in your application.
My final takeaway is this: make sure you understand the principles of modeling with DynamoDB first. DynamoDB isn’t a relational database and you shouldn’t use it like one. The learning curve feels steep, but there are really only three or four key concepts you need to learn, and everything else flows from that. Once you understand these basics, you’ll be able to make more informed decisions about how many tables to use in your application.
If you’re wanting to understand DynamoDB data modeling, there are lots of great resources out there. I wrote The DynamoDB Book, a comprehensive guide to data modeling with DynamoDB that teaches you the underlying concepts as well as examples with practical application. I also highly recommend the DynamoDB developer documentation, as the DynamoDB team has done a great job explaining how to think about DynamoDB correctly. Don’t be afraid to dive in and try it out. The DynamoDB community is a friendly, growing community, and you’ll find plenty of support along the way.
My thanks to Joseph Idziorek, Jeff Duffy, and Amrith Kumar for their input and comments as I wrote this blog post.
About the authors
 Alex DeBrie is an AWS Hero and the author of The DynamoDB Book, a comprehensive guide to data modeling with DynamoDB. He is an independent consultant who works with companies of all sizes to assist with DynamoDB data modeling and serverless AWS architecture implementations. In his free time, he loves sports and spending time with his wife and four children. Follow him on Twitter.
Alex DeBrie is an AWS Hero and the author of The DynamoDB Book, a comprehensive guide to data modeling with DynamoDB. He is an independent consultant who works with companies of all sizes to assist with DynamoDB data modeling and serverless AWS architecture implementations. In his free time, he loves sports and spending time with his wife and four children. Follow him on Twitter.