AWS for Games Blog
Gain Insights Into Your Player Base Using The AWS for Games Cohort Modeler
This is the first blog post in a series focusing on the AWS for Games Cohort Modeler. The AWS for Games Cohort Modeler is a deployable solution for developers to map out and classify player relationships and identify like behavior within a player base. Within the code sample is a SAM (Serverless Application Module) template to stand up the infrastructure, a sample Sagemaker notebook to visualize the data, and APIs to programmatically interact with the back-end data store.
Our customers regularly ask us to help them understand their own customers better. However, the ask is often more specific: “How can I detect toxic community members?” or “How can I determine which of my users are about to churn?” These questions are behavioral in nature, and can be answered by identifying common factors that are shared between players who engage in similar behaviors. For instance, toxic community members may use foul language in chat, and churners may alter their login patterns just before they stop playing a game. These are patterns that can be detected, analyzed, and measured.
Even when customers collect this data, it is siloed and not aggregated with other behavioral data. However, by retaining and aggregating those behavioral patterns, one can combine them to form a behavioral profile for each player. Ultimately, most profiles have a lot of elements in common – cheaters can only cheat in so many ways! – and those commonalities wind up giving us a common model, or a “cohort,” which we can then identify and operate on.
Today, AWS for Games is introducing the AWS for Games Cohort Modeler: a mechanism accompanied by a code sample demonstrating how to aggregate behavioral patterns to help developers identify and populate different player cohorts within a community. The Cohort Modeler allows our customers to aggregate and categorize player metrics leveraging behavioral science and customer data.
For example, a customer can use the Cohort Modeler to categorize and aggregate the following example metrics into unique individual player groupings:
- In-game metrics and behaviors,
- Financial transactions,
- Marketing campaign interactions,
- Involvement in support cases (both opening and being the subject of)
- Social media shares generated from within the game (screenshots to Twitter, Facebook recruiting, etc)
Bringing these data sets together into a single, consolidated view creates a thorough a behavioral profile which a game studio can use to gain insights into how they interact with a game, how they participate in a game’s community, and how their play can drive the ongoing design and development decisions.
Examples of the cohorts that can be detected include:
- Behavioral cohorts: bad actors and champions
- Financial cohorts: whales, minnows, and churners
- Gameplay cohorts: explorers, socializers, and achievers
The Cohort Modeler implements a graph data model that defines relationships (edges) between players, events, and activities (vertices) to power insights and visuals. In a graph data model, “vertexes” represent data entity types, and “edges” represent the relationships between those entities. In the sample version of the Cohort Modeler, there are three kinds of data entity types:
- Players
- The activities they engage in,
- The marketing campaigns they may be interacting with.
Edges indicate when players interact with each other, or engage in activities or marketing material as shown in the following relationship diagram:
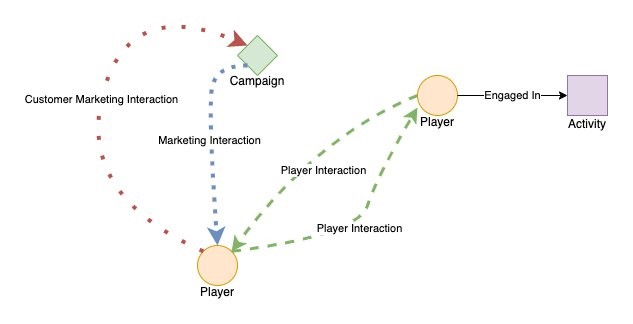
The AWS for Games Cohort Modeler is a deployable solution for game studios to map out and classify player relationships and behavior within a player base. Within the code sample, we are releasing an AWS Serverless Application Model (SAM) template to deploy the Amazon Neptune database, a sample Amazon Sagemaker notebook to visualize the data, and an Amazon API Gateway to programmatically interact with the graph. The Cohort Modeler deploys several APIs to interact with and better understand your player cohorts.

The AWS for Games Cohort Modeler uses Amazon Neptune, a fully managed Graph database, as the back-end store to house the identity graph. AWS Lambda and AWS API Gateway have been configured to allow for an abstract data loading platform allowing any team to load a data onto a vertex or edge. These components constitute the base requirements to build out the cohort graph and understand your game community through in game, out of game and monetary transactions for a single or multiple titles.
To deploy the Cohort Modeler, go to the aws-samples github page and download the template to deploy in your account. The readme in the repository has all the instructions on how to deploy and get started. Once you have deployed the code sample you can use the Sagemaker notebook is preloaded with a notebook to load and explore a player community sample dataset.
Resources:
Guidance for the Game Tech Cohort Modeler on AWS
Post authors: Daniel Whitehead, Will Kalescky, Chris Finch