AWS for Industries
Demand Forecasting using Amazon SageMaker and GluonTS at Novartis AG (Part 4/4)
This is the fourth post of a four-part series on the strategic collaboration between AWS and Novartis AG, where the AWS Professional Services team built the Buying Engine platform.
In this series:
- Part 1: How Novartis brought SMART into Smart Procurement with AWS Machine Learning
- Part 2: Novartis AG uses Amazon SageMaker and Amazon Neptune to build and enrich a knowledge graph using BERT
- Part 3: Novartis AG uses Amazon OpenSearch Service K-Nearest Neighbor (KNN) and Amazon SageMaker to power search and recommendation (September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service)
- Part 4: Demand forecasting using Amazon SageMaker and GluonTS at Novartis AG (this post)
This post focuses on the demand forecasting component in the Buying Engine, specifically on the usage of Amazon SageMaker and MXNet GluonTS library. SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning models quickly. The combination with GluonTS unlocks state-of-the-art, deep learning-based forecasting algorithms and streamlines the processing pipelines, which shorten the time from ideation to production.
Project motivation
Holistic optimization of the procurement chain for all goods and services is a core building block as Novartis works towards its larger goal to build an automated replenishment engine driven by demand and forecasting. Being able to predict demand for each Stock Keeping Unit (SKU) at particular geography several months in advance allows Novartis to make faster data-driven decisions, plan better, and negotiate contracts and discounts as well as save costs.
The motivation to use MXNet GluonTS was that it provides a toolkit to work with time series data in a simpler fashion, and many state-of-the-art custom models to be trained and benchmarked under the same API. We were able to create a baseline model, train DeepAR and DeepState, as well as experiment with other models much quicker with only parametric changes to the code.
This reminder of this blog guides you through the following steps: (1) notebook setup; (2) prepare dataset; (3) training; and (4) inference.
Notebook Setup
- Create an Amazon S3 bucket. This will be used throughout the notebooks to store files generated by the examples.
- Create a SageMaker notebook instance. Please observe the following:
- The execution role must be given an additional permission to read/write from the S3 bucket created in step 1.
- If you put the notebook instance inside a Virtual Private Cloud (VPC), make sure that the VPC allows access to the public Pypi repository and
aws-samples/repositories. - Attach the Git repository amazon-sagemaker-gluonts-entrypointto the notebook, as shown in the following screenshots, then click the Create notebook instance
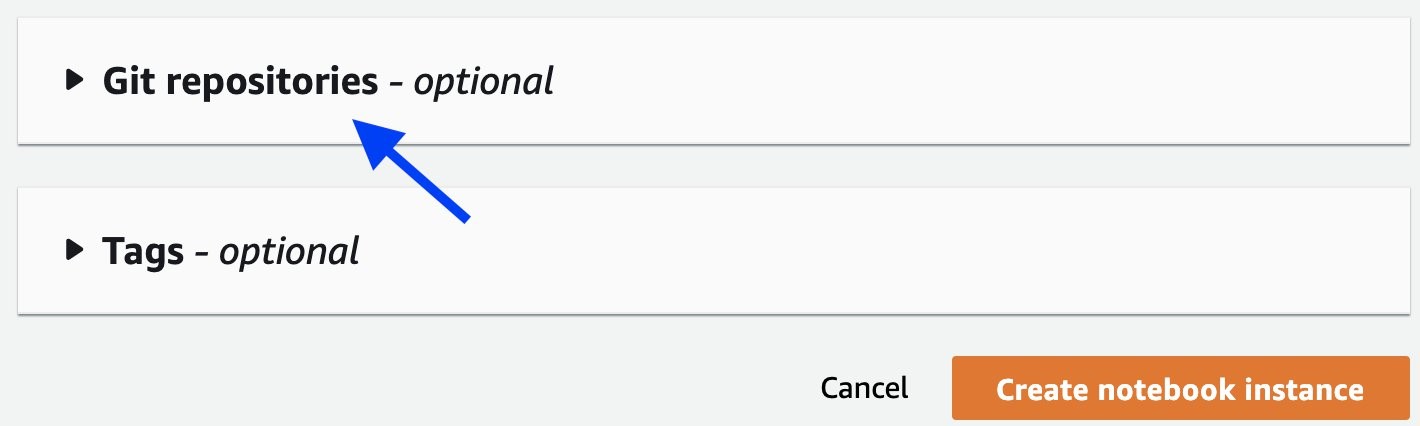
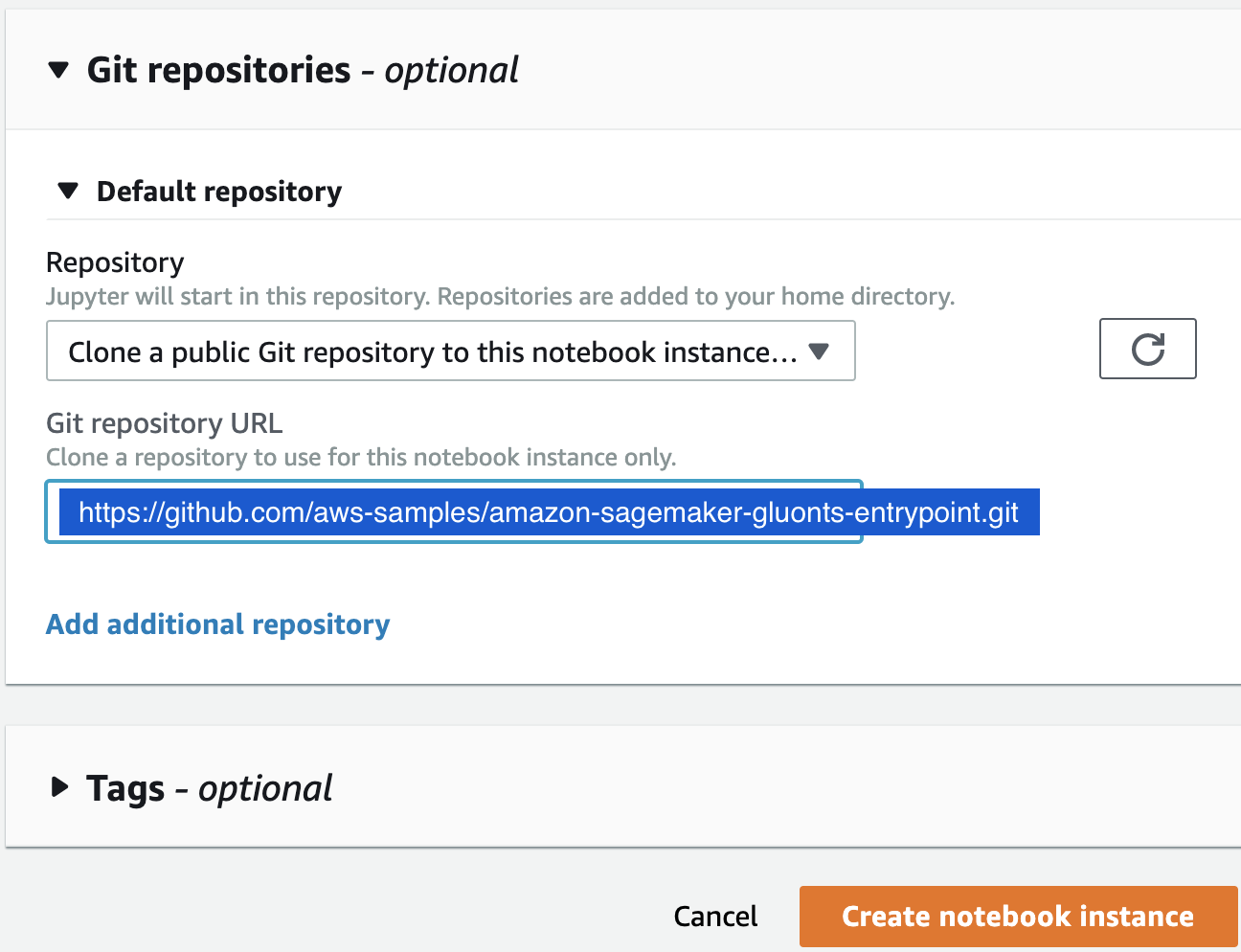
When the notebook instance is ready, you can work with the familiar JupyterLab interface with the workspace defaults to the amazon-sagemaker-gluonts-entrypoint folder. The next screenshot illustrates the key content in the folder.
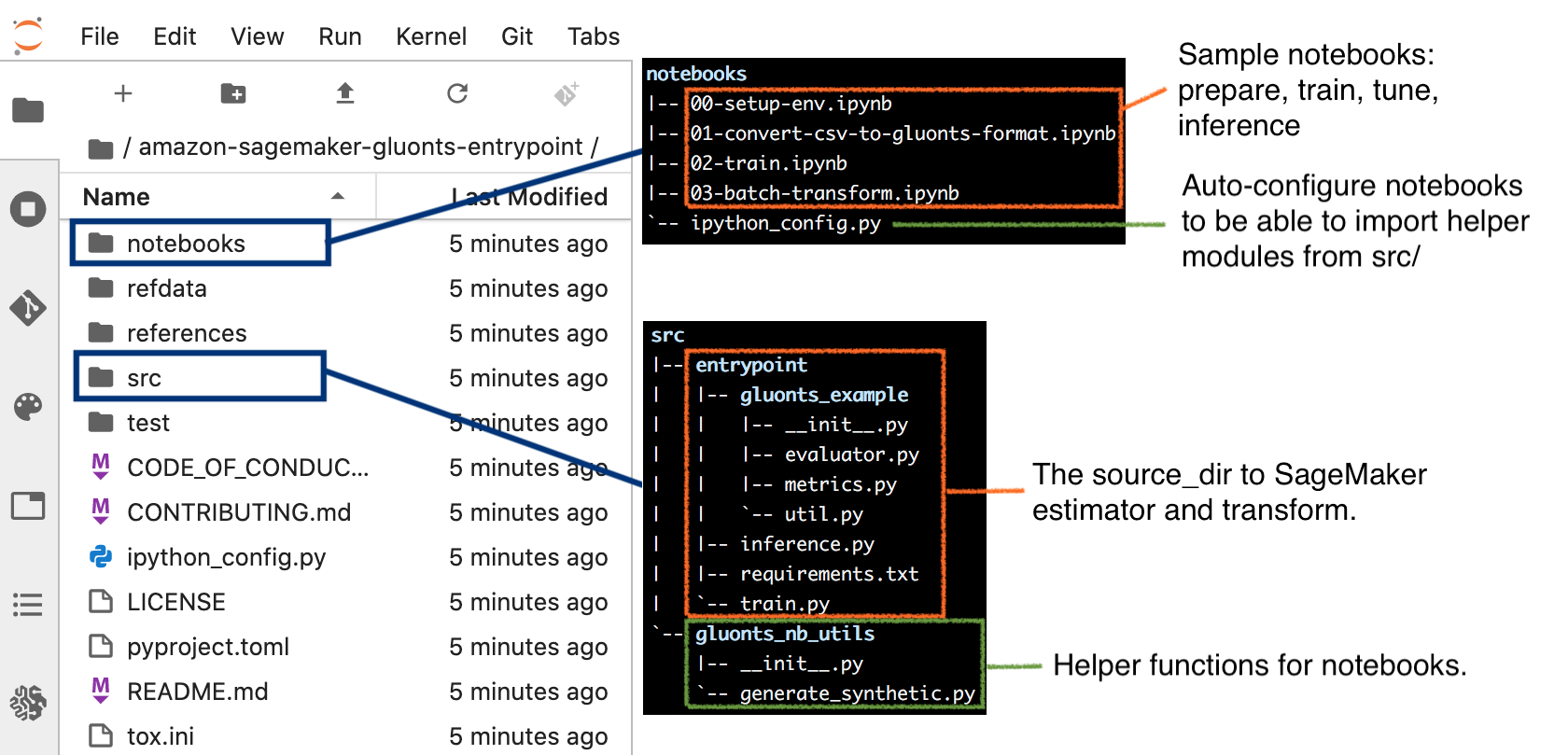
To complete this step, open notebooks/00-setup-env.ipynb and make sure the selected kernel is conda_mxnet_p36. Run this notebook to install additional modules required by subsequent steps, and to generate a synthetic data in the CSV format.
Prepare dataset in GluonTS format
Out of 3 million products in the Novartis Buying Engine product catalog, a few thousands are high-frequency SKUs, each of which is represented as a time series describing historical demand over the last several years. For the purpose of this blog, we describe how we used deep learning models with GluonTS to generate weekly forecasts for 3-months, and daily forecasts for 14-days in advance.
Let’s convert the CSV data to the GluonTS format. We start by using ListDataSet to hold the train and test splits. Then, we utilize GluonTS’s TrainDataSets and save_datasets() APIs to save those ListDataSet to files. The TrainDataSets provides an abstraction of a container of metadata, train split, and test split. The TrainDataSets will later on become a single data channel for a SageMaker training job. Having metadata for datasets is crucial for reproducibility and to be able to track what a dataset is about and how it was created, especially for prolonged usage across cross-team collaboration.
The following stanza shows how the APIs work. Please refer to notebooks/01-convert-csv-to-gluonts-format.ipynb in the sample Git repository aws-samples/amazon-sagemaker-gluonts-entrypoint for the complete code. First, use ListDataSet to convert your Pandas dataframe to an in-memory structure that’s compatible with GluonTS.
Next, we’ll manage the train split, test split, and an additional metadata as a single construct called TrainDataSets, then save to local disk. See the next stanza.
You can then upload the dataset to S3.
Training
Please refer to notebooks/02-train.ipynb for the complete code of model training and tuning. Here, we focus straightaway on hyperparameter tuning. For additional information, see SageMaker documentations on model training and model tuning.
The following stanza shows a helper function that starts a tuning job. Each tuning job spawns one or more training jobs, and each training job uses the same entrypoint train script from the sample Git repository. In our example, training jobs utilize the Managed Spot Training for Amazon SageMaker, a feature based on Amazon EC2 Spot Instances that will help you lower ML training costs by up to 90% compared to using on-demand instances in SageMaker.
We can then submit multiple tuning jobs, one for a different algorithm. Our example of a single entrypoint train script supports four different models: DeepAR, DeepState, DeepFactor, and Transformer. All these algorithms are already implemented in GluonTS; hence, we simply tap into it to quickly iterate and experiment over different models. Please refer to src/entrypoint/train.py on the implementation details. For more details of the four algorithms, and additional algorithms not covered here, please refer to gluonts model documentation.
The following stanza show to submit a Hyperparameter Tuning job for DeepAR (please refer to the notebook for the DeepState example). The key novelty of the entrypoint train script is to passthrough the hyperparameters it receives as command line arguments, directly to the specified estimator, yet the entrypoint train script does not need to explicitly declare all those hyperparameters in its body. The passthrough mechanic simplifies the overhead of supporting new estimator in future.
The tuning job runs, and on completion will show the best training job. You can follow through the best training job, then go to the output location, which contains two files: model.tar.gz and output.tar.gz. The former is the model artifact, the later contains the training information produced by our entrypoint train script.
To facilitate rapid experiment, the entrypoint train script outputs all the test metrics, and in addition, the test forecasts, and automatically render the plots of forecast-vs-groundtruth as montages and as individual charts. As such, data scientists can simply download the output and start making post-mortem analysis and reasoning without having to write additional boiler-plate, tedious codes. When data scientists observe interesting phenomena, then they can follow-up with further deep-dive. Please refer to src/entrypoint/train.py and src/entrypoint/gluonts_example/evaluator.py on the implementation details, in particular class MyEvaluator from src/entrypoint/gluonts_example/evaluator.py which customizes the GluonTS backtesting with the wMAPE metric and plots.
To download the training output from the console, first go to your training job, then scroll down until the Output section. Click the Amazon S3 model artifact to go to the S3 output area.
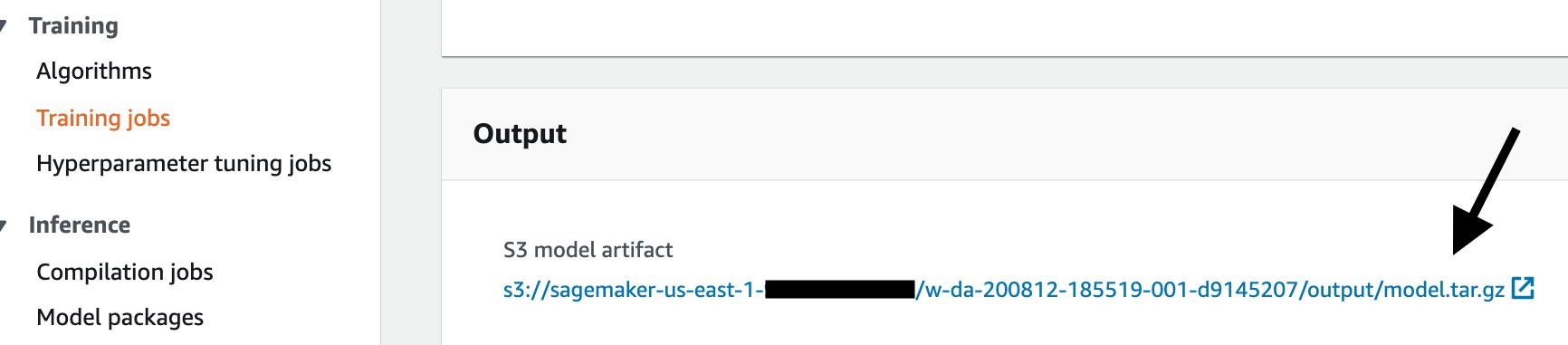
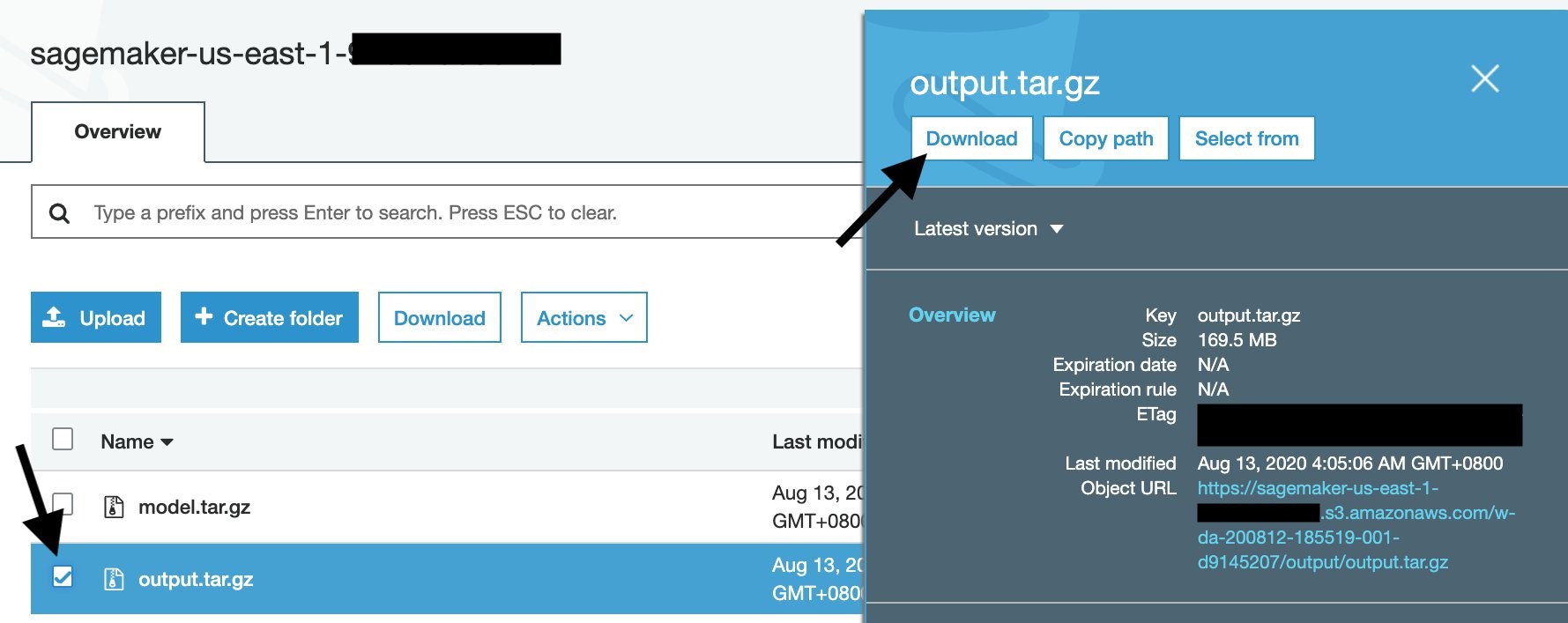
Once you download the output.tar.gz, open or extract it with your un-archiver, and you’ll see this structure:
An example montage is shown here (zoomed-out for illustrative purpose). Each montage is 10×10 SKUs to provide bird-eye view for data scientists. The montage size is 5024 x 3766 pixels (100 dpi), thus 502 x 376 pixels per subplots.

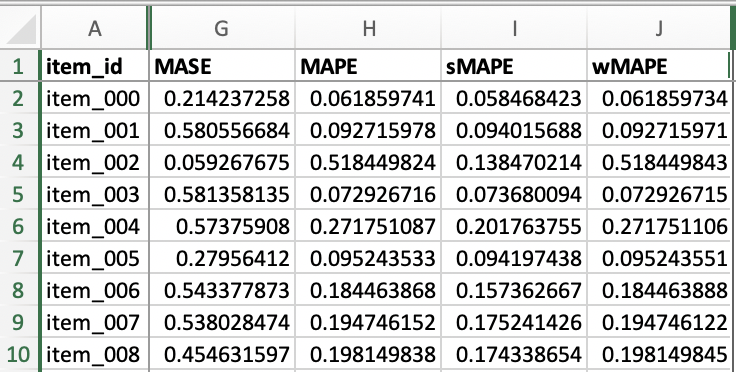
File item_metrics.csv contains the backtest performance of invidual SKUs, with an example shown below. Since forecasts are probabilistic, the specific metric of each SKU is the expected value of that metric out of a number of sample paths. Different metrics define their own expectation function, e.g., MASE, MAPE, sMAPE and our custom wMAPE use median, whereas MSE uses mean. Refer to get_metrics_per_ts() method of the MyEvaluator class in src/entrypoint/gluonts_example/evaluator.py for per-SKU wMAPE, and the get_metrics_per_ts() method in the gluonts.evaluation.Evaluator class for the built-in metrics.
File agg_metrics.json contains the aggregated backtest performance across all timeseries. Each metric may use a different function to aggregate per-SKU metrics. Our custom wMAPE uses mean as you can see from the get_aggregate_metrics() method of the MyEvaluator class in src/entrypoint/gluonts_example/evaluator.py). For the built-in metrics, please refer to get_aggregate_metrics() in the gluonts.evaluation.Evaluator class.
The rest of the training output files are self-explanatory, and we invite you inspect those files.
Create SageMaker model
Once you have decided on the best performing training job, you need to register the model artifact as a SageMaker model, as shown in the next stanza. The entrypoint inference script is located at src/entrypoint/inference.py. Please refer to the first-half of notebooks/03-batch-transform.ipynb for the complete code example on registering your model artifact into a SageMaker model.
Batch Inference
The following stanzas show detail implementations of the inference script src/entrypoint/inference.py, which will run on a SageMaker MXNet framework container. The script must adhere to the protocol defined here, hence our script provides model_fn() and transform_fn().
First, take a look on its model_fn() .
Next, take a look at transform_fn() shown in the next stanza. The key philosophy is to represent each timeseries as a JSON line, and this format is compatible with how SageMaker inference works (for both endpoints and batch transform), where each record must be a complete dataset. For text input format, each line corresponds to one record also known as time-series. It’s important to note that in the SageMaker inference construct, each record must be independent from each other, such that the model or inference script must not assume dependencies among different records.
Therefore, with text format, the GluonTS representations is suitable not only for GluonTS-based model, but also for other models. In fact, Novartis standardizes on this format across multiple models they’ve developed in-house, such as LSTM-on-PyTorch and XGBoost models. These different inference scripts share the same serialization and deserialization logics, and differ only in model_fn() and the prediction function. Please note that the format used in GluonTS differs with SageMaker first-party DeepAR: although both uses JSON lines, but the member keys are different. For readers looking for the inference input format of the SageMaker first party DeepAR, please check out this link.
With the inference script, we’re now ready to perform batch inference. Do note that real-time inference via endpoints also leverage the same inference script, hence easing to real-time inferences in the future.
The next stanza is taken from notebooks/03-batch-transform.ipynb and shows how to programmatically start a batch transform job.
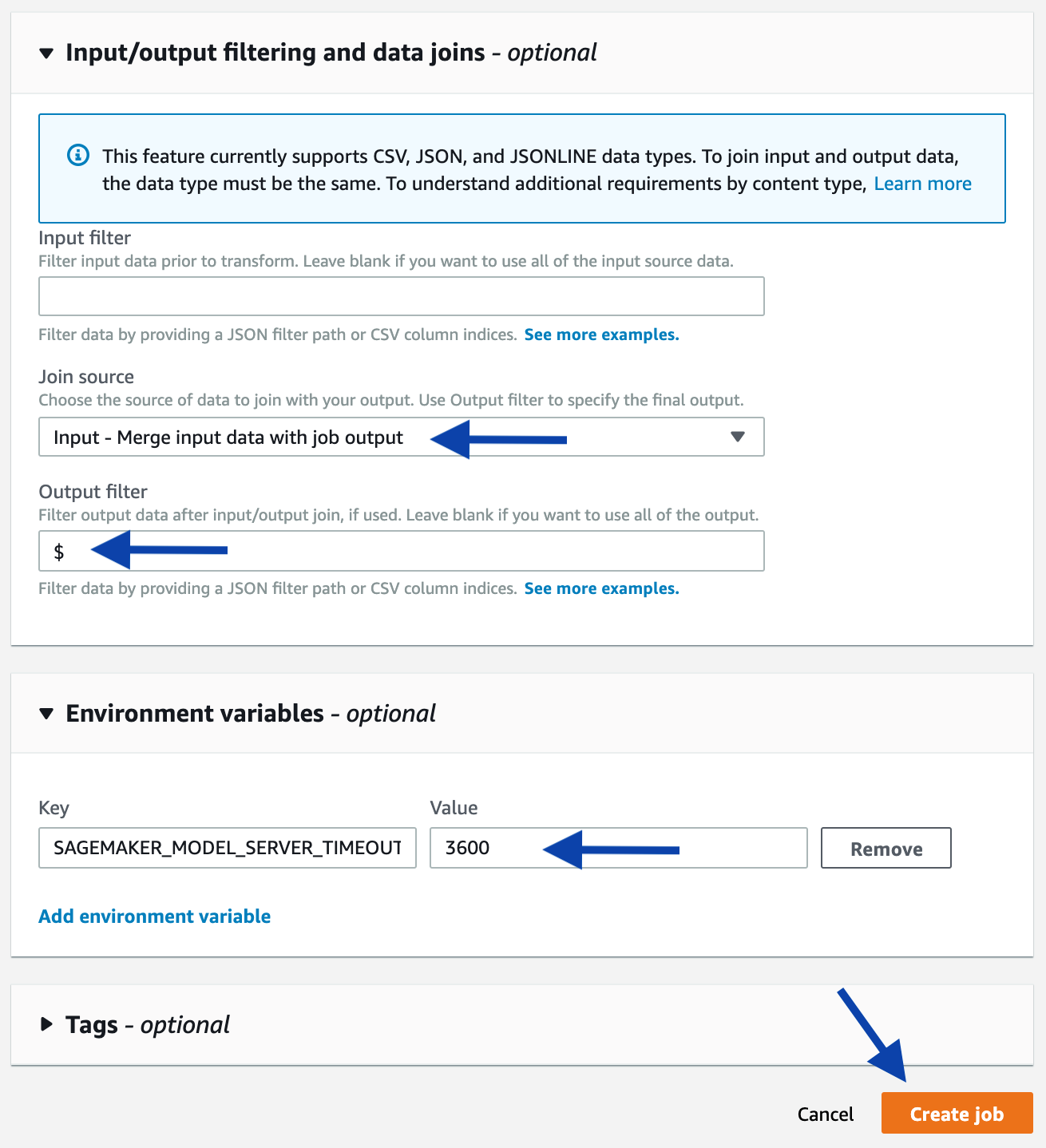
As an alternative, you can start a batch transform job using the console. Starting from the console of the selected model, click the Create batch transform job button. On the next page, provide the same information used in the above-mentioned programmatic example, such as the input path, output path, and input/output filter. Refer to the following screenshots as a guidance.
![]()
![]()
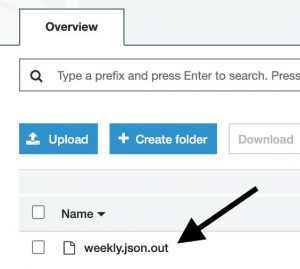
A forecast for an SKU will be a JSON structure in a JSON-line formatted file. You can quickly sample some results from the console: starting at the page of a completed Batch Transform job, follow the link to the output Amazon S3 location, then sample some lines.


Next, we show an annotated output line, which denotes the forecast for a specific SKU. The comments facilitate understanding of the forecast output structure; however, they do not appear in the actual output file.
Cleaning up
When you finish this exercise, remove your resources with the following steps:
- Delete your notebook instance
- Optionally, delete registered models
- Optionally, delete the SageMaker execution role
- Optionally, empty and delete the S3 bucket, or keep whatever you want
Conclusion
You have learned how to use GluonTS advanced APIs to implement dataset preparation, training (with hyperparameter tuning) and inferences using GluonTS and SageMaker. Learn more about SageMaker and kick off your own machine learning solution by visiting the Amazon SageMaker console.
The AWS Professional Services team provides assistance through a collection of offerings which help customers achieve specific outcomes related to enterprise cloud adoption. With this model, the team was able to deliver the production-ready ML solution previewed in this post. The Novartis AG team was also trained on best practices to productionize machine learning so that they can maintain, iterate, and improve future ML efforts.
AWS welcomes your feedback. Feel free to leave us any questions or comments.
Many thanks to Novartis AG team who worked on the project. Special thanks to following contributors from Novartis AG who encouraged and reviewed the blog post.
- Srayanta Mukherjee: Srayanta is Director Data Science in Novartis CDO’s Data Science & Artificial Intelligence team and was the data science lead during the delivery of the Buying Engine.
- Abhijeet Shrivastava: Abhijeet is Associate Director Data Science in Novartis CDO’s Data Science & Artificial Intelligence team and was the lead for the delivery of Forecasting & Optimization system of Buying Engine.
- Pamoli Dutta: Pamoli is Senior Expert Data Scientist in Novartis CDO’s Data Science & Artificial Intelligence team and was the co-lead for the delivery of Forecasting & Optimization system of Buying Engine.
- Shravan Koninti: Shravan is Senior Data Scientist in Novartis NBS’ Technology Architecture & Digital COE team and was member of the Forecasting & Optimization delivery team.