Artificial Intelligence
Amazon SageMaker now supports PyTorch and TensorFlow 1.8
Starting today, you can easily train and deploy your PyTorch deep learning models in Amazon SageMaker. This is the fourth deep learning framework that Amazon SageMaker has added support for, in addition to TensorFlow, Apache MXNet, and Chainer. Just like with those frameworks, now you can write your PyTorch script like you normally would and rely on Amazon SageMaker training to handle setting up the distributed training cluster, transferring data, and even hyperparameter tuning. On the inference side, Amazon SageMaker provides a managed, highly available, online endpoint that can be automatically scaled up as needed.
In addition to PyTorch, we’re also adding the latest stable versions of TensorFlow (1.7 and 1.8), allowing you to start taking advantage of new features in these versions such as tf.custom_gradient and the pre-made BoostedTree estimators today. The Amazon SageMaker TensorFlow estimator is setup to use the latest version by default, so you don’t even need to update your code.
Supporting many deep learning frameworks is important to developers, since each of the deep learning frameworks has unique areas of strength. PyTorch is a framework used heavily by deep learning researchers, but it is also rapidly gaining popularity among developers due its flexibility and ease of use. TensorFlow is well established and continues to add great features with each release. We’ll continue to invest in these, and other popular engines such as MXNet and Chainer.
PyTorch in Amazon SageMaker
The PyTorch framework is unique. It differs from other frameworks, such as TensorFlow, MXNet, Caffe, etc., because it uses a technique called reverse-mode auto-differentiation, which allows you to build neural networks dynamically. It is also deeply integrated with Python, allowing you to use typical Python control flows in your networks or to write new network layers using Cython, Numba, NumPy, etc. Finally, PyTorch is fast, with support for acceleration libraries like MKL, CuDNN, and NCCL. It recently posted wins in the DAWNBench Competition from the team at fast.ai using PyTorch.
Using PyTorch in Amazon SageMaker is as easy as using the other pre-built deep learning containers. Just provide your training or hosting script, which consists of standard PyTorch wrapped in a few helper functions, and then use the PyTorch estimator from the Amazon SageMaker Python SDK as follows:
Feel free to see our example notebooks, documentation, or follow along with the below example for more detail.
Training and deploying a neural network with PyTorch
For this example we’ll fit a straightforward convolutional neural network on the MNIST handwritten digits dataset. This consists of 70,000 labeled 28×28 pixel grayscale images (60,000 for training, 10,000 for testing) with 10 classes (one for each digit from 0 to 9). The Amazon SageMaker PyTorch container uses script mode, which expects the input script in a format that should be close to what you’d run outside of SageMaker. Let’s start by looking at that code. The full file is based on PyTorch’s own MNIST example, with the addition of distributed training. We’ll just highlight the most important pieces.
Entry point script
Starting with the main guard, we’ll use a parser to read in hyperparameters that we pass to our Amazon SageMaker estimator when creating the training job. The hyperparameters will be made available as arguments to our input script in the training container. Here, we look for hyperparameters like batch size, epochs, learning rate, momentum, etc. If we don’t define their values in our SageMaker estimator call, they’ll take on the defaults we’ve provided. We also use the training_env() method from the custom sagemaker_containers library, which provides container specifics like training and model directories and instance configurations. You can also access them through specific environment variables. For more information, please visit SageMaker Containers GitHub repository.
After we’ve defined our hyperparameters, we pass them to our train() function, which we also define in our input script. The train() function takes on several tasks. First, it sets up resources properly (GPU, distributed compute, etc.).
Then, it loads our datasets.
And it initiates our network, model, and optimizer.
Next, it loops through epochs to train the network. Here we loop through mini-batches, use back-propagation to minimize the model’s negative log likelihood loss, evaluate training loss every 100 mini-batches, and finally evaluate test loss at the end of each epoch.
And finally, we save our model.
We used a number of helper functions and classes within train(). This includes _get_train_data_loader() and _get_test_data_loader() which reads in shuffled mini-batches of our MNIST data, converts the 28×28 matrices to PyTorch tensors, and normalizes the pixel values.
We also have the Net class that defines our network architecture and what a forward pass through the network means. In this case, it’s two convolutional and max pooling layers with rectified linear unit (ReLU) activation, followed by a two fully connected layers with dropout intermixed.
We have another function which is used just while training on distributed CPU instances to average gradients.
And we have a test() function designed to report our accuracy on the hold-out dataset.
Finally, the save_model() function uses built-in PyTorch functionality to serialize the model parameters.
Amazon SageMaker notebook – setup
Now that we’ve written our PyTorch script, we can create a Jupyter notebook that runs it using the Amazon SageMaker pre-built PyTorch container. Feel free to follow along interactively by running the notebook.
Start by setting up the Amazon S3 bucket for storing data and model artifacts, as well as the IAM role for data and Amazon SageMaker permissions.
Now we’ll import the Python libraries we’ll need and create an Amazon SageMaker session.
Next, we’ll download our dataset and upload to Amazon S3.
Amazon SageMaker notebook – training
Now that we’ve prepared our training data and PyTorch script (which we’ll name mnist.py), the PyTorch class in the SageMaker Python SDK allows us to run that script as a training job on Amazon SageMaker distributed, managed training infrastructure. We’ll also pass the estimator our IAM role, the training cluster configuration, and a look-up of hyperparameters and values that we want to set differently than the defaults in our script.
Notice, one of our hyperparameters is “backend”. PyTorch has a number of backends for distributed training. The SageMaker PyTorch container supports TCP and Gloo for CPU instances, and Gloo + NCCL for GPU training. Since we are training with multiple GPU instances, we’ll specify ‘gloo’ here.
After we’ve constructed our PyTorch estimator, we can fit it by passing in the data we uploaded to Amazon S3. Amazon SageMaker makes sure our data is available in the local filesystem of the training cluster, so our PyTorch script can simply read the data from disk.
Amazon SageMaker notebook – deployment
After training, we can use the PyTorch estimator to deploy a PyTorchPredictor. This creates a SageMaker endpoint — a hosted prediction service that we can use to perform inference.
To do this our mnist.py script needs several different functions. Returning to that script, the first is model_fn() which loads the output of save_model() in order to make predictions from it.
model_fn() is the only function we actually need to specify in our mnist.py script. The default versions of the other functions (input_fn(), predict_fn(), and output_fn()) will work for our current use case, so we don’t need to define them. We’ll briefly show their defaults for completeness. input_fn() converts the input payload into a PyTorch Tensor:
predict_fn() generates predictions from the model based on the return value of input_fn().
output_fn() serializes the output from predict_fn() so that it can be returned by the SageMaker endpoint.
For more details on the default implementations, see the SageMaker PyTorch container GitHub repository.
The arguments to the deploy() function allow us to set the number and type of instances that will be used for the endpoint. These do not need to be the same as the values we used for the training job. For example, you can train a model on a set of GPU-based instances, and then deploy the endpoint to a fleet of CPU-based instances However, in that case you need to make sure that you return or save your model as a CPU as shown in mnist.py. Here we will deploy the model to a single ml.m4.xlarge instance.
Amazon SageMaker notebook – prediction and evaluation
Next we can use this predictor to classify hand-written digits. Drawing into the image box loads the pixel data into a data variable in this notebook, which we can then pass to the predictor. This cell requires this input.html file.
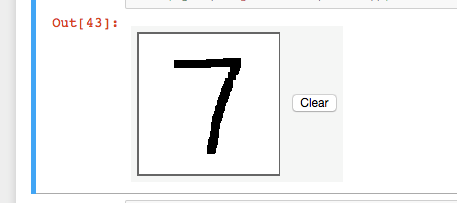

And the prediction of our own handwritten digit is accurate.
Amazon SageMaker notebook – cleanup
After you have finished with this example, remember to delete the prediction endpoint to release the instances associated with it.
Conclusion
In this blog post we show you how to use the Amazon SageMaker pre-built PyTorch container to build a deep learning model on images, but that’s just the beginning. PyTorch unlocks a huge amount of flexibility, and Amazon SageMaker has provided other example notebooks for image classification on CIFAR-10 and sentiment analysis using recurrent neural networks. We also have TensorFlow example notebooks which you can use to test the latest versions. Or, try it out on your own use case!
About the Author
 David Arpin is AWS’s AI Platforms Selection Leader and has a background in managing Data Science teams and Product Management.
David Arpin is AWS’s AI Platforms Selection Leader and has a background in managing Data Science teams and Product Management.
 Nadia Yakimakha is a Software Development Engineer at AWS working on Machine Learning Frameworks in SageMaker.
Nadia Yakimakha is a Software Development Engineer at AWS working on Machine Learning Frameworks in SageMaker.