Artificial Intelligence
Building a Reliable Text-to-Speech Service with Amazon Polly
| Listen to this post
Voiced by Amazon Polly |
This is a guest post by Yiannis Philipopoulos, a Software Developer at Bandwidth. In Yiannis’ words: “Bandwidth’s solutions are shaping the future of how we connect with voice and messaging for mobile apps and large-scale, enterprise-level solutions. At the core of Bandwidth’s business-grade Communications Platform as a Service (CPaaS) offering are communication APIs that allow companies to launch and scale next-generation apps and solutions using the nation’s largest VoIP network.”
Text-to-speech (TTS) technology is evolving rapidly. Thanks to machine learning, computers’ ability to disambiguate text and combine individual sounds into natural-sounding whole words has improved dramatically. Although Amazon Polly provides excellent TTS at low cost, many still use older TTS technologies because they believe that upgrading to a new system isn’t worth the effort.
Bandwidth’s customers use TTS primarily to vocalize menus, reminders, and order information. Bandwidth’s API lets customers quickly purchase telephone numbers, send texts, make calls, and, create static or dynamic voice messages. In this post, I show how Bandwidth integrated Amazon Polly to provide on-demand TTS capabilities. I also offer some simple suggestions for leveraging Amazon Polly’s ability to cache results.
I explain how to use Amazon Polly to most effectively meet our customer’s needs. To illustrate, I have provided TTS sample service demo code that you can run right out of the box. The demo code calls Amazon Polly using many of the improvements I discuss in this blog. For caveats for using the demo service, see the README file.
The service
The workflow for the Bandwidth API is straightforward. When the Bandwidth API receives a request for TTS, it directs the request to our new internal service. The internal service will check for a cached response, then direct the request to Amazon Polly, or, if Amazon Polly can’t complete the request for any reason, to a lower-priority TTS vendor. Finally, we store the successful speech result in our cache.
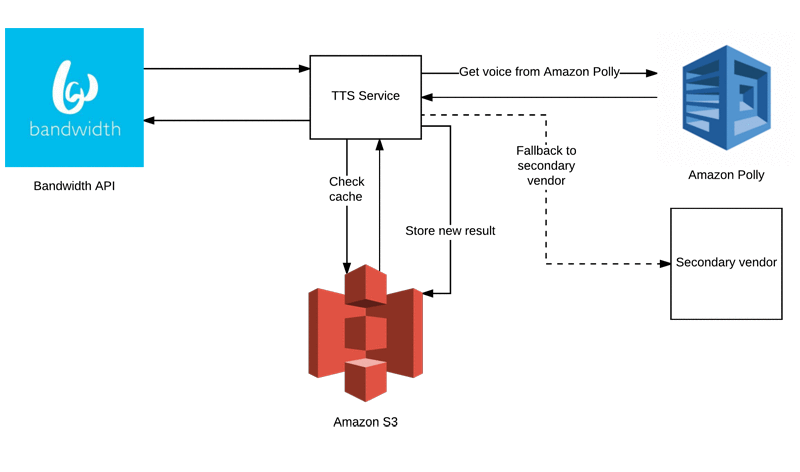
Why (primarily) Amazon Polly?
Why did we decide to use Amazon Polly as our primary TTS engine? We reviewed the most important requirements for our use case: uptime, choice of voices, speed, interpretation, cost, and caching. Amazon Polly delivers on all these requirements.
Of course, uptime is an important requirement for any vendor. Issues with our previous vendor’s uptime drove us to investigate new solutions, and made building a redundant system extremely important.
With our previous (now secondary) vendor, we gave customers access to a variety of voices. Our new vendor had to match our previous selection of voices. Amazon Polly offers at least one male and female voice in every language we support, and has a variety of voices in English.
Speed was another important factor. Because menus and the exchange of live information are a big part of our use case, the ability to start streaming a response back to customers as soon as possible is critical. Nobody likes waiting on a phone menu.
When dealing with text generated by customers, contextual interpretation of input is also important. Although Amazon Polly’s option to use SSML to guarantee outcomes is an excellent feature, it’s impossible to know the intent all of the text that our customers send us. Having a service that can successfully disambiguate English, for example, to properly read “live” in the text “I live at this address,” as opposed to “we broadcast live,” considerably improves the user experience. This is a feature that Amazon Polly diligently supports. In our testing, we found a single case where Amazon Polly did not generate the expected speech in response to input. The Amazon Polly team was eager to hear about that case. Now the audio plays as expected.
Cost and caching go together. Caching is another feature that made Amazon Polly very appealing. Although providing customers the ability to quickly convert dynamic messages to voice is important, many messages are frequently repeated. Our previous vendor did not allow caching of responses, which required our API to call for every request. Being able to cache static messages can reduce cost significantly. At Bandwidth, we’re seeing a 78% cache hit rate, resulting in far fewer requests.
Integrating Amazon Polly
Integrating Amazon Polly into your service requires getting the audio stream from Amazon Polly. I will show you how to get that audio stream from Amazon Polly and some lessons learned from the integration.
Getting audio from Amazon Polly
Adding a new vendor to a multi-vendor TTS system is a surprisingly small part of the development effort required to build a full system. The following Java code is all that’s required to get an audio stream from Amazon Polly:
How do you use the audio stream best? We have two objectives to fulfill with our stream:
- To start streaming the audio back as soon as possible
- To cache the response
You have options for streaming the InputStream from Amazon Polly to the OutputStream for your clients. The simplest is to use IOUtils.copy(). However, one of our requirements, which is probably a common requirement for TTS, is to make sure clients get their voice results back as quickly as possible. We ended up opting for a more explicit approach, as shown in the following code:
This code flushes the relatively small buffer every time that it fills. This ensures that the bytes are available to the client as soon as possible, which makes a huge difference with longer texts.
Lesson learned: reuse your client
While working with Amazon Polly, we hit one major roadblock that might also trip up other developers. Your most important, and perhaps least obvious, task is to make sure that your Amazon Polly client is being reused. In our initial implementation, which used code similar to the preceding example, we generated a new default client with each request, grabbed the stream, and threw it away. This approach is tempting. Client creation is so quick, why have the state?
During testing, we saw that with larger strings, our stream would abruptly terminate. We mistakenly created the client, grabbed the stream, and then lost all references to the client. For sufficiently large streams with a lot of traffic, the garbage collector came along, cleaned up the client, and broke the stream. Make sure that your client stays alive until the stream is fully processed. Without thorough testing, we might have missed this issue.
Note: If your service needs to process very large strings (over the 1500 character Amazon Polly limit), check out this blog post on batching Amazon Polly requests.
Caching
We set up our cache in Amazon Simple Storage Service (Amazon S3). There’s lots of information on using Amazon S3, so I will highlight the key points needed for this service.
Setting up the S3 bucket
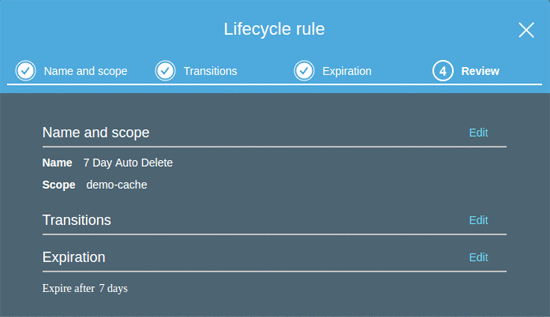
After you have an S3 bucket, set up a cache directory. For our demo, we call it demo-cache. In the Amazon S3 console, choose the bucket, then choose Management, Lifecycle, and Add Lifecycle rule. Then add a new Delete rule on the demo-cache prefix. We settled on a 7-day auto-delete rule. We didn’t arrive at this number scientifically. We felt that it balanced storing the expected volume of cache hits with the pressure of storing unnecessary or stale data. Setting up your S3 bucket is one of the only setup tasks that our demo requires.

Writing the cache to S3
Writing to an S3 bucket is simple and well documented. However, it is worth noting that it’s important to make sure that all of your cache writes are valid. The simplest way to make sure that your writes are corruption-free is to use the Amazon S3 MD5 capabilities. Although this method is much more verbose than simply calling putObject(), the process in the code below will use Amazon S3’s MD5sum capabilities to verify your files were stored accurately.
Fallback
Because this post is about setting up a resilient service, it would incomplete if we didn’t provide information on setting up a fallback vendor. The good news is that there are many opportunities to reuse code. Because all vendors will, at some point, need to give you an InputStream, it’s easy to abstract most of the business logic that you want to apply around your vendors. To see how little code is required per vendor, see our repository.
To control vendor failover, we decided to go with Netflix’s Hystrix. Although our code still iterates over vendors on failure, by adding a few simple ConfigurationManager properties per vendor and breaking code into HystrixCommand classes, our service can respond to poor vendor health almost effortlessly.
After a vendor fails to service a specified number of requests, the vendor is removed from rotation. After a specified period of time, Hystrix retries the vendor. If the vendor still fails to service requests, it is removed again.
Here’s a taste of how little effort is needed. We simply add the following properties for each vendor:
Then we break our work into HystrixCommand objects:
For brevity, I omitted details on how the class runs. You can see the full classes in the repository. Adding the preceding properties and using this simple runnable class structure allows our service to gracefully take vendors in and out of rotation as they experience issues without developer intervention. This simple framework, which abstracts a lot of state and developer effort, simplifies managing multiple vendors.
Conclusion
Migrating to a new service can be daunting. In this post, I show how Bandwidth built a small, reliable, and fast TTS application that is backed by Amazon Polly. We are now using high-quality voices at low cost. The developer effort required to build this new service was surprisingly minimal.
I’ve also shown how to build your own service and provided a demo service that you can use out of the box to start. If you’re still using older TTS software with low-quality voices, I hope you’re now asking yourself “Why?”
Additional Reading
Take your skills to the next level. Learn how to build your own text-to-speech applications with Amazon Polly.
