Artificial Intelligence
Category: Amazon SageMaker Ground Truth
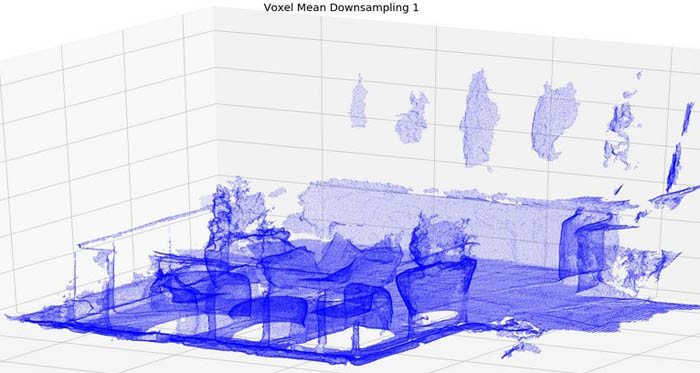
Annotate dense point cloud data using Amazon SageMaker Ground Truth
Autonomous vehicle companies typically use LiDAR sensors to generate a 3D understanding of the environment around their vehicles. For example, they mount a LiDAR sensor on their vehicles to continuously capture point-in-time snapshots of the surrounding 3D environment. The LiDAR sensor output is a sequence of 3D point cloud frames (the typical capture rate is […]

Quality Assessment for SageMaker Ground Truth Video Object Tracking Annotations using Statistical Analysis
Data quality is an important topic for virtually all teams and systems deriving insights from data, especially teams and systems using machine learning (ML) models. Supervised ML is the task of learning a function that maps an input to an output based on examples of input-output pairs. For a supervised ML algorithm to effectively learn […]

Helmet detection error analysis in football videos using Amazon SageMaker
The National Football League (NFL) is America’s most popular sports league. Founded in 1920, the NFL developed the model for the successful modern sports league and is committed to advancing progress in the diagnosis, prevention, and treatment of sports-related injuries. Health and safety efforts include support for independent medical research and engineering advancements in addition […]
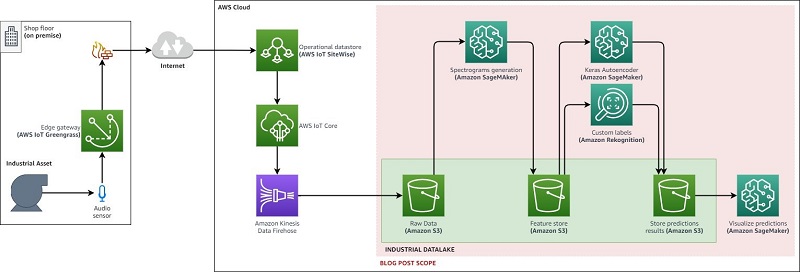
Performing anomaly detection on industrial equipment using audio signals
Industrial companies have been collecting a massive amount of time-series data about operating processes, manufacturing production lines, and industrial equipment. You might store years of data in historian systems or in your factory information system at large. Whether you’re looking to prevent equipment breakdown that would stop a production line, avoid catastrophic failures in a […]
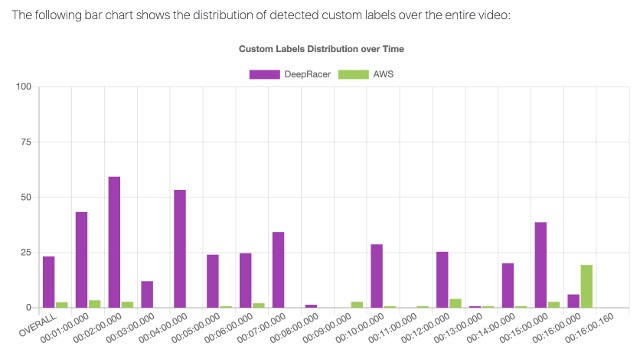
Building your own brand detection and visibility using Amazon SageMaker Ground Truth and Amazon Rekognition Custom Labels – Part 1: End-to-end solution
According to Gartner, 58% of marketing leaders believe brand is a critical driver of buyer behavior for prospects, and 65% believe it’s a critical driver of buyer behavior for existing customers. Companies spend huge amounts of money on advertisement to raise brand visibility and awareness. In fact, as per Gartner, CMO spends over 21% of […]
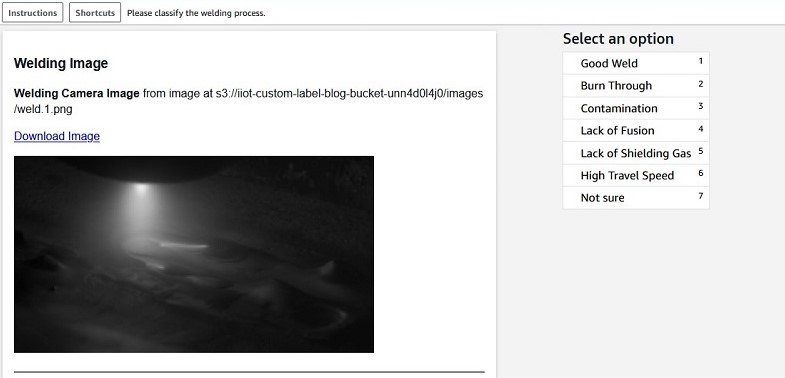
Labeling mixed-source, industrial datasets with Amazon SageMaker Ground Truth
Prior to using any kind of supervised machine learning (ML) algorithm, data has to be labeled. Amazon SageMaker Ground Truth simplifies and accelerates this task. Ground Truth uses pre-defined templates to assign labels that classify the content of images or videos or verify existing labels. Ground Truth allows you to define workflows for labeling various […]

Implementing a custom labeling GUI with built-in processing logic with Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth is a fully managed data labeling service that makes it easy to build highly accurate training datasets for machine learning. It offers easy access to Amazon Mechanical Turk and private human labelers, and provides them with built-in workflows and interfaces for common labeling tasks. A labeling team may wish to use […]

Real-time data labeling pipeline for ML workflows using Amazon SageMaker Ground Truth
High-quality machine learning (ML) models depend on accurately labeled, high-quality training, validation, and test data. As ML and deep learning models are increasingly integrated into production environments, it’s becoming more important than ever to have customizable, real-time data labeling pipelines that can continuously receive and process unlabeled data. For example, you may want to create […]

zomato digitizes menus using Amazon Textract and Amazon SageMaker
This post is co-written by Chiranjeev Ghai, ML Engineer at zomato. zomato is a global food-tech company based in India. Are you the kind of person who has very specific cravings? Maybe when the mood hits, you don’t want just any kind of Indian food—you want Chicken Chettinad with a side of paratha, and nothing […]
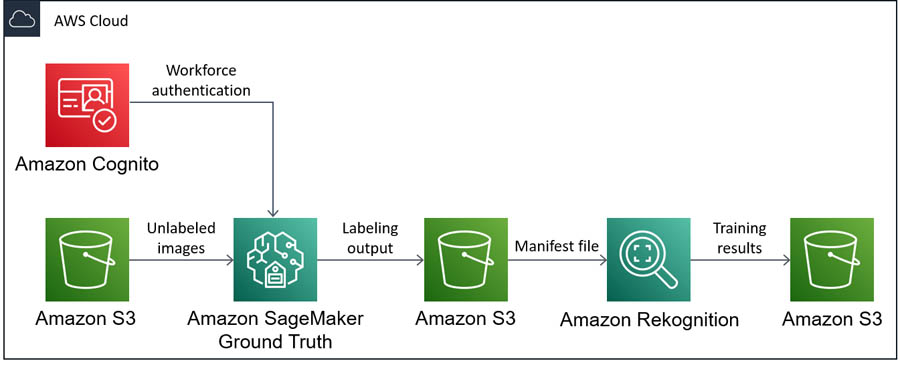
Processing auto insurance claims at scale using Amazon Rekognition Custom Labels and Amazon SageMaker Ground Truth
Computer vision uses machine learning (ML) to build applications that process images or videos. With Amazon Rekognition, you can use pre-trained computer vision models to identify objects, people, text, activities, or inappropriate content. Our customers have use cases that span every industry, including media, finance, manufacturing, sports, and technology. Some of these use cases require […]