Artificial Intelligence
Category: Amazon SageMaker
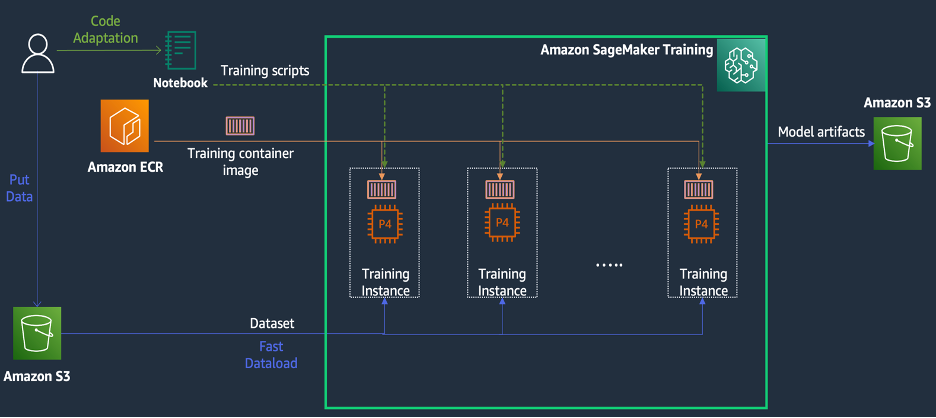
KT’s journey to reduce training time for a vision transformers model using Amazon SageMaker
KT Corporation is one of the largest telecommunications providers in South Korea, offering a wide range of services including fixed-line telephone, mobile communication, and internet, and AI services. KT’s AI Food Tag is an AI-based dietary management solution that identifies the type and nutritional content of food in photos using a computer vision model. This […]

Retrieval-Augmented Generation with LangChain, Amazon SageMaker JumpStart, and MongoDB Atlas Semantic Search
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to […]

Philips accelerates development of AI-enabled healthcare solutions with an MLOps platform built on Amazon SageMaker
This is a joint blog with AWS and Philips. Philips is a health technology company focused on improving people’s lives through meaningful innovation. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care. It partners with […]

Fine-tune Whisper models on Amazon SageMaker with LoRA
Whisper is an Automatic Speech Recognition (ASR) model that has been trained using 680,000 hours of supervised data from the web, encompassing a range of languages and tasks. One of its limitations is the low-performance on low-resource languages such as Marathi language and Dravidian languages, which can be remediated with fine-tuning. However, fine-tuning a Whisper […]

Use foundation models to improve model accuracy with Amazon SageMaker
Determining the value of housing is a classic example of using machine learning (ML). In this post, we discuss the use of an open-source model specifically designed for the task of visual question answering (VQA). With VQA, you can ask a question of a photo using natural language and receive an answer to your question—also in plain language. Our goal in this post is to inspire and demonstrate what is possible using this technology.

Implement a custom AutoML job using pre-selected algorithms in Amazon SageMaker Automatic Model Tuning
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model. It plays a crucial role in every model’s development process […]

Best prompting practices for using the Llama 2 Chat LLM through Amazon SageMaker JumpStart
Llama 2 stands at the forefront of AI innovation, embodying an advanced auto-regressive language model developed on a sophisticated transformer foundation. It’s tailored to address a multitude of applications in both the commercial and research domains with English as the primary linguistic concentration. Its model parameters scale from an impressive 7 billion to a remarkable […]

Foundational vision models and visual prompt engineering for autonomous driving applications
Prompt engineering has become an essential skill for anyone working with large language models (LLMs) to generate high-quality and relevant texts. Although text prompt engineering has been widely discussed, visual prompt engineering is an emerging field that requires attention. Visual prompts can include bounding boxes or masks that guide vision models in generating relevant and […]

Fine-tune and Deploy Mistral 7B with Amazon SageMaker JumpStart
Today, we are excited to announce the capability to fine-tune the Mistral 7B model using Amazon SageMaker JumpStart. You can now fine-tune and deploy Mistral text generation models on SageMaker JumpStart using the Amazon SageMaker Studio UI with a few clicks or using the SageMaker Python SDK. Foundation models perform very well with generative tasks, […]

Model management for LoRA fine-tuned models using Llama2 and Amazon SageMaker
In the era of big data and AI, companies are continually seeking ways to use these technologies to gain a competitive edge. One of the hottest areas in AI right now is generative AI, and for good reason. Generative AI offers powerful solutions that push the boundaries of what’s possible in terms of creativity and […]