Artificial Intelligence
Category: Amazon SageMaker

Use Snowflake as a data source to train ML models with Amazon SageMaker
May 2023: This blog post has been updated to include a workflow that does not require building a custom container. Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. […]

How Marubeni is optimizing market decisions using AWS machine learning and analytics
This post is co-authored with Hernan Figueroa, Sr. Manager Data Science at Marubeni Power International. Marubeni Power International Inc (MPII) owns and invests in power business platforms in the Americas. An important vertical for MPII is asset management for renewable energy and energy storage assets, which are critical to reduce the carbon intensity of our […]
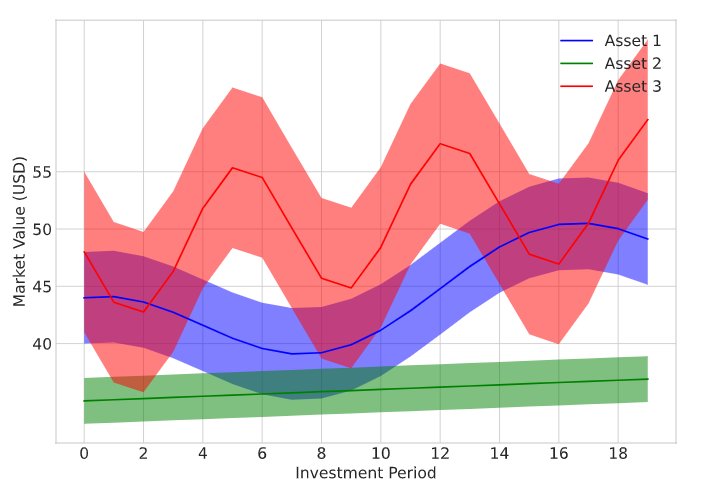
Portfolio optimization through multidimensional action optimization using Amazon SageMaker RL
Reinforcement learning (RL) encompasses a class of machine learning (ML) techniques that can be used to solve sequential decision-making problems. RL techniques have found widespread applications in numerous domains, including financial services, autonomous navigation, industrial control, and e-commerce. The objective of an RL problem is to train an agent that, given an observation from its […]

Hosting YOLOv8 PyTorch models on Amazon SageMaker Endpoints
Deploying models at scale can be a cumbersome task for many data scientists and machine learning engineers. However, Amazon SageMaker endpoints provide a simple solution for deploying and scaling your machine learning (ML) model inferences. Our last blog post and GitHub repo on hosting a YOLOv5 TensorFlowModel on Amazon SageMaker Endpoints sparked a lot of interest […]

Four approaches to manage Python packages in Amazon SageMaker Studio notebooks
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. A public GitHub repo provides hands-on examples for each of the presented approaches. Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, […]

Training large language models on Amazon SageMaker: Best practices
Language models are statistical methods predicting the succession of tokens in sequences, using natural text. Large language models (LLMs) are neural network-based language models with hundreds of millions (BERT) to over a trillion parameters (MiCS), and whose size makes single-GPU training impractical. LLMs’ generative abilities make them popular for text synthesis, summarization, machine translation, and […]

Achieve rapid time-to-value business outcomes with faster ML model training using Amazon SageMaker Canvas
Machine learning (ML) can help companies make better business decisions through advanced analytics. Companies across industries apply ML to use cases such as predicting customer churn, demand forecasting, credit scoring, predicting late shipments, and improving manufacturing quality. In this blog post, we’ll look at how Amazon SageMaker Canvas delivers faster and more accurate model training times enabling […]

Virtual fashion styling with generative AI using Amazon SageMaker
The fashion industry is a highly lucrative business, with an estimated value of $2.1 trillion by 2025, as reported by the World Bank. This field encompasses a diverse range of segments, such as the creation, manufacture, distribution, and sales of clothing, shoes, and accessories. The industry is in a constant state of change, with new […]

How Kakao Games automates lifetime value prediction from game data using Amazon SageMaker and AWS Glue
This post is co-written with Suhyoung Kim, General Manager at KakaoGames Data Analytics Lab. Kakao Games is a top video game publisher and developer headquartered in South Korea. It specializes in developing and publishing games on PC, mobile, and virtual reality (VR) serving globally. In order to maximize its players’ experience and improve the efficiency […]

Extract non-PHI data from Amazon HealthLake, reduce complexity, and increase cost efficiency with Amazon Athena and Amazon SageMaker Canvas
In today’s highly competitive market, performing data analytics using machine learning (ML) models has become a necessity for organizations. It enables them to unlock the value of their data, identify trends, patterns, and predictions, and differentiate themselves from their competitors. For example, in the healthcare industry, ML-driven analytics can be used for diagnostic assistance and […]