Artificial Intelligence
Category: Advanced (300)

Fine-tune and host SDXL models cost-effectively with AWS Inferentia2
As technology continues to evolve, newer models are emerging, offering higher quality, increased flexibility, and faster image generation capabilities. One such groundbreaking model is Stable Diffusion XL (SDXL), released by StabilityAI, advancing the text-to-image generative AI technology to unprecedented heights. In this post, we demonstrate how to efficiently fine-tune the SDXL model using SageMaker Studio. We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances, unlocking superior price performance for your inference workloads.
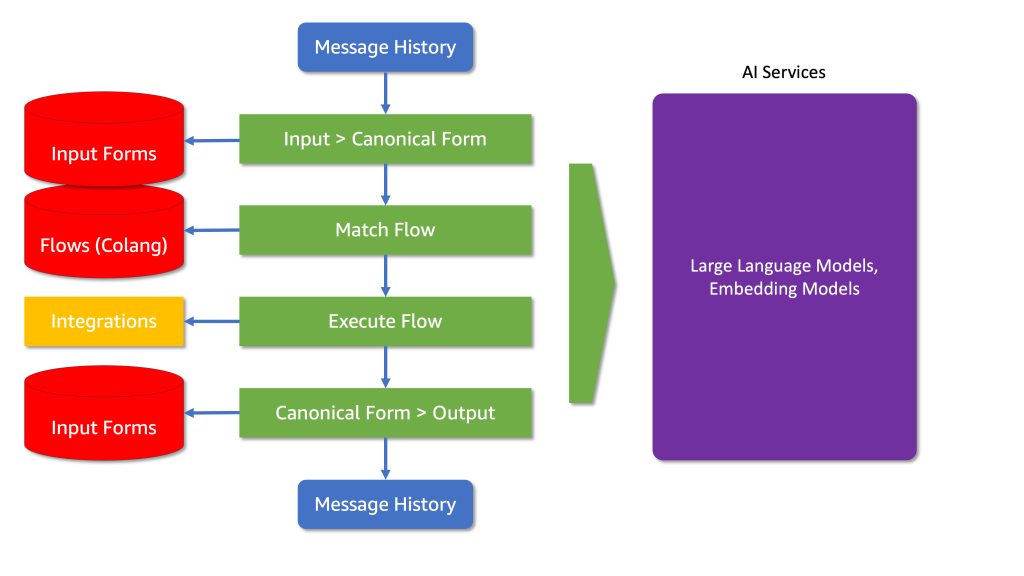
Enhancing LLM Capabilities with NeMo Guardrails on Amazon SageMaker JumpStart
Integrating NeMo Guardrails with Large Language Models (LLMs) is a powerful step forward in deploying AI in customer-facing applications. The example of AnyCompany Pet Supplies illustrates how these technologies can enhance customer interactions while handling refusal and guiding the conversation toward the implemented outcomes. This journey towards ethical AI deployment is crucial for building sustainable, trust-based relationships with customers and shaping a future where technology aligns seamlessly with human values.

DeepSeek-R1 model now available in Amazon Bedrock Marketplace and Amazon SageMaker JumpStart
DeepSeek-R1 is an advanced large language model that combines reinforcement learning, chain-of-thought reasoning, and a Mixture of Experts architecture to deliver efficient, interpretable responses while maintaining safety through Amazon Bedrock Guardrails integration.

Develop a RAG-based application using Amazon Aurora with Amazon Kendra
RAG retrieves data from a preexisting knowledge base (your data), combines it with the LLM’s knowledge, and generates responses with more human-like language. However, in order for generative AI to understand your data, some amount of data preparation is required, which involves a big learning curve. In this post, we walk you through how to convert your existing Aurora data into an index without needing data preparation for Amazon Kendra to perform data search and implement RAG that combines your data along with LLM knowledge to produce accurate responses.

Enabling generative AI self-service using Amazon Lex, Amazon Bedrock, and ServiceNow
In this post, we show how you can integrate Amazon Lex with Amazon Bedrock Knowledge Bases and ServiceNow to provide 24/7 automated support and self-service options.

HCLTech’s AWS powered AutoWise Companion: A seamless experience for informed automotive buyer decisions with data-driven design
This post introduces HCLTech’s AutoWise Companion, a transformative generative AI solution designed to enhance customers’ vehicle purchasing journey. In this post, we analyze the current industry challenges and guide readers through the AutoWise Companion solution functional flow and architecture design using built-in AWS services and open source tools. Additionally, we discuss the design from security and responsible AI perspectives, demonstrating how you can apply this solution to a wider range of industry scenarios.

How TUI uses Amazon Bedrock to scale content creation and enhance hotel descriptions in under 10 seconds
TUI Group is one of the world’s leading global tourism services, providing 21 million customers with an unmatched holiday experience in 180 regions. The TUI content teams are tasked with producing high-quality content for its websites, including product details, hotel information, and travel guides, often using descriptions written by hotel and third-party partners. In this post, we discuss how we used Amazon SageMaker and Amazon Bedrock to build a content generator that rewrites marketing content following specific brand and style guidelines.

Talk to your slide deck using multimodal foundation models on Amazon Bedrock – Part 3
In Parts 1 and 2 of this series, we explored ways to use the power of multimodal FMs such as Amazon Titan Multimodal Embeddings, Amazon Titan Text Embeddings, and Anthropic’s Claude 3 Sonnet. In this post, we compared the approaches from an accuracy and pricing perspective.

Accelerating ML experimentation with enhanced security: AWS PrivateLink support for Amazon SageMaker with MLflow
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker, users want a seamless and secure way to experiment with and select the models that deliver the most value for their business. In the initial stages of an ML […]

Search enterprise data assets using LLMs backed by knowledge graphs
In this post, we present a generative AI-powered semantic search solution that empowers business users to quickly and accurately find relevant data assets across various enterprise data sources. In this solution, we integrate large language models (LLMs) hosted on Amazon Bedrock backed by a knowledge base that is derived from a knowledge graph built on Amazon Neptune to create a powerful search paradigm that enables natural language-based questions to integrate search across documents stored in Amazon Simple Storage Service (Amazon S3), data lake tables hosted on the AWS Glue Data Catalog, and enterprise assets in Amazon DataZone.