AWS Machine Learning Blog
Category: Technical How-to

Deploy large language models for a healthtech use case on Amazon SageMaker
In this post, we show how to develop an ML-driven solution using Amazon SageMaker for detecting adverse events using the publicly available Adverse Drug Reaction Dataset on Hugging Face. In this solution, we fine-tune a variety of models on Hugging Face that were pre-trained on medical data and use the BioBERT model, which was pre-trained on the Pubmed dataset and performs the best out of those tried.

Build a movie chatbot for TV/OTT platforms using Retrieval Augmented Generation in Amazon Bedrock
In this post, we show you how to securely create a movie chatbot by implementing RAG with your own data using Knowledge Bases for Amazon Bedrock. We use the IMDb and Box Office Mojo dataset to simulate a catalog for media and entertainment customers and showcase how you can build your own RAG solution in just a couple of steps.

Train and host a computer vision model for tampering detection on Amazon SageMaker: Part 2
In the first part of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. In this post, we present an approach to develop a deep learning-based computer vision model to […]

Talk to your slide deck using multimodal foundation models hosted on Amazon Bedrock and Amazon SageMaker – Part 1
With the advent of generative AI, today’s foundation models (FMs), such as the large language models (LLMs) Claude 2 and Llama 2, can perform a range of generative tasks such as question answering, summarization, and content creation on text data. However, real-world data exists in multiple modalities, such as text, images, video, and audio. Take […]

Benchmark and optimize endpoint deployment in Amazon SageMaker JumpStart
When deploying a large language model (LLM), machine learning (ML) practitioners typically care about two measurements for model serving performance: latency, defined by the time it takes to generate a single token, and throughput, defined by the number of tokens generated per second. Although a single request to the deployed endpoint would exhibit a throughput […]

Build enterprise-ready generative AI solutions with Cohere foundation models in Amazon Bedrock and Weaviate vector database on AWS Marketplace
This post discusses how enterprises can build accurate, transparent, and secure generative AI applications while keeping full control over proprietary data. The proposed solution is a RAG pipeline using an AI-native technology stack, whose components are designed from the ground up with AI at their core, rather than having AI capabilities added as an afterthought. We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace.

Use mobility data to derive insights using Amazon SageMaker geospatial capabilities
Geospatial data is data about specific locations on the earth’s surface. It can represent a geographical area as a whole or it can represent an event associated with a geographical area. Analysis of geospatial data is sought after in a few industries. It involves understanding where the data exists from a spatial perspective and why […]
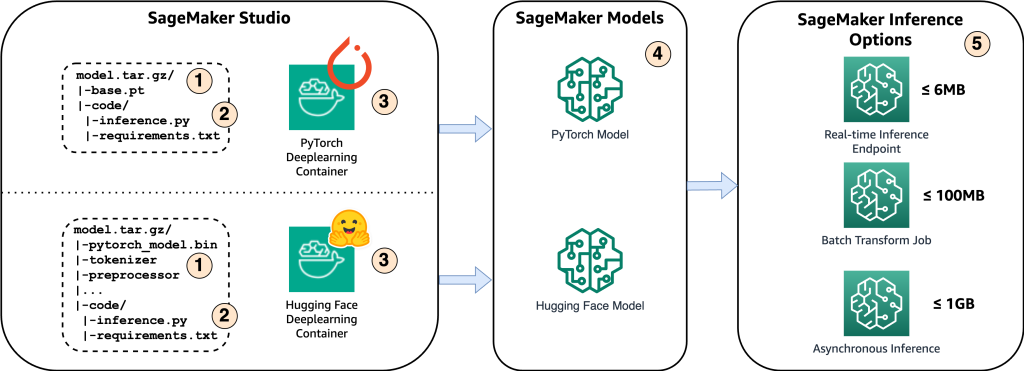
Host the Whisper Model on Amazon SageMaker: exploring inference options
OpenAI Whisper is an advanced automatic speech recognition (ASR) model with an MIT license. ASR technology finds utility in transcription services, voice assistants, and enhancing accessibility for individuals with hearing impairments. This state-of-the-art model is trained on a vast and diverse dataset of multilingual and multitask supervised data collected from the web. Its high accuracy […]

Build financial search applications using the Amazon Bedrock Cohere multilingual embedding model
Enterprises have access to massive amounts of data, much of which is difficult to discover because the data is unstructured. Conventional approaches to analyzing unstructured data use keyword or synonym matching. They don’t capture the full context of a document, making them less effective in dealing with unstructured data. In contrast, text embeddings use machine […]

Build an Amazon SageMaker Model Registry approval and promotion workflow with human intervention
This post is co-written with Jayadeep Pabbisetty, Sr. Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. ML Engineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. Model developers often work together in developing ML models and require a robust […]