Artificial Intelligence
Dive Deep into AWS DeepLens Lambda Functions and the New Model Optimizer
| April 2023 Update: Starting January 31, 2024, you will no longer be able to access AWS DeepLens through the AWS management console, manage DeepLens devices, or access any projects you have created. To learn more, refer to these frequently asked questions about AWS DeepLens end of life. |
Today we launched a new Model Optimizer for AWS DeepLens, which will optimize your deep learning models to run on the DeepLens GPU efficiently, with a single line of Python. The Model Optimizer is available in AWS DeepLens software version 1.2.0.
To access the GPU for inference, AWS DeepLens uses the Cl-DNN, Compute Library for Deep Neural Networks. To run your models on AWS DeepLens, you have to convert them into Cl-DNN format. Model Optimizer does this conversion for you in 2-10 seconds, depending on the size of your model, with a single line of code:
You can access the Model Optimizer by including this line of code in your inference Lambda function. An inference Lambda function allows AWS DeepLens to access the models that you have just deployed. In this post, we show how to create an inference Lambda function, and provide a template that you can customize to suit your requirements.
The inference Lambda performs three key functions: pre-processing, inference, and post-processing.
To create an inference Lambda function, use the AWS Lambda console and follow the steps below
- Choose Create function. You customize this function to run inference for your deep learning models.
- Choose Blueprints
- Search for the greengrass-hello-world blueprint.
- Give your Lambda function the same name as your model.
- Choose an existing IAM role: AWSDeepLensLambdaRole. You must have created this role as part of the registration process.
- Choose Create function.
- In Function code, make sure the handler is greengrassHelloWorld.function_handler.
- In the GreengrassHello file, remove all of the code. You will write the code for inference Lambda function in this file.
Start by importing the required packages:
Importing the os lets you access the operating system for AWS DeepLens. Importing awscam allows you to access the AWS DeepLens inference API. mo lets you access the Model Optimizer. cv2 lets you access the open CV library, which contains common tools for image pre-processing and importing. thread lets you access Python’s multi-threading library. You use a separate thread to send the inference results to mplayer, where you can view the model output.
Next, create a Greengrass Core SDK client that allows you to send messages to the cloud with AWS IoT using MQTT. The Greengrass core SDK is already loaded on the device, so you didn’t need to import it.
Next, create an AWS IoT topic for the Lambda function to send the messages to. You can access this topic on the AWS IoT console.
To enable viewing the output locally with mplayer, declare a global variable containing the jpeg image to put into the FIFO file, results.mjpeg. You can also turn off streaming to the FIFO file by changing Write_To_FIFO to False. This terminates the thread, so you cannot access the image with mplayer to view the output.
Next, create a simple class that runs on its own thread so that you can publish the output images to the FIFO file and view it with mplayer. This is standard code for viewing the output over mplayer, and is common to all inference Lambda functions. For your own projects, you can copy and paste this code into your inference Lambda function.
Now define the inference class in the Lambda function. Start by defining a Greengrass inference function.
The input_width and input_height parameters define the input parameters for the model. To perform inference, the model expects frames of the same size. You can customize these parameters for the model that you are deploying to AWS DeepLens.
In the next line, define the name of the model. This name has to match the prefix of the params and json files of the trained model. For example, if the params and json files are squeezenet_v1.1-0000.params and squeezenet_v1.1-symbol.json, respectively, the model name is the prefix squeezenet_v1.1. This is important. If model names do not match the prefix to these two files, inference will not work and will generate an error.
Now, initiate the Model Optimizer. This converts the deployed model into Cl-DNN format, which can be accessed in the AWS DeepLens GPU. This returns the path to the post-optimized artifacts.
Load the model into the inference engine. This is where you provide code to access the GPU. To access the CPU, simply code the “GPU” = 0. For deep learning models, however, we recommend that you access the GPU for the sake of efficiency and speed.
You can send a message to AWS IoT to inform it that the model has loaded.
Next, define the type of model that you are running. For example, the model type for a neural style transfer is segmentation, and for object localization is ssd (single shot detector). For image classification, it is classification. Because you are deploying a squeezenet model that classifies images, define the model type as classification.
Because squeezenet_v1.1 has 1,000 classifiers, it’s not practical to write out a python list to define a map of the numeric label to a human-readable label. Instead, we add a text file that has the index and labels represented in order. You can find the text file for this example here.
To add the text file to your lambda function:
- In the Function code block, choose File. Then choose New File
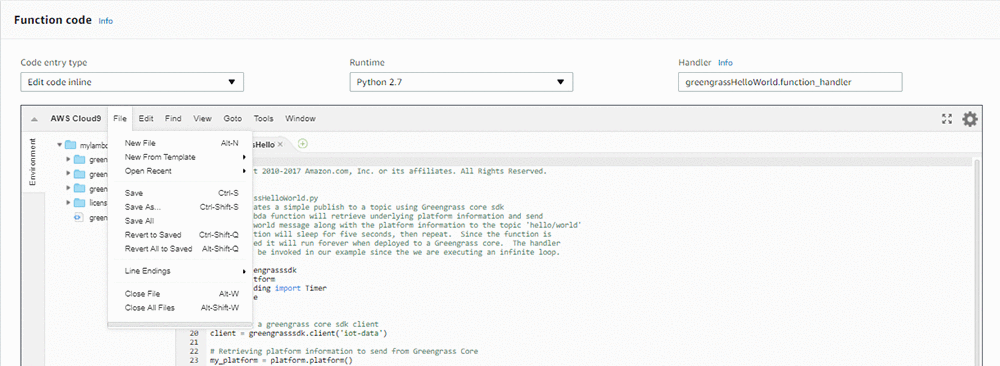
- Copy paste the data in the text file into the new file you just created
- Choose File and then Save
- Provide the filename as sysnet.txt and choose Save
Your file with the relevant index and labels is added to the lambda function package.
Now return to your python code by choosing the greengrassHelloWorld.py from the left menu. The next step is to open the ‘sysnet.txt’ we just added.
Define the number of classifiers that you want to see in the output. By specifying 5, the output result returns the top 5 highest probability values in descending order. You can specify any number that is supported by the model.
Now start the FIFO thread to view the output locally with mplayer.
Publish the Inference is starting message to the AWS IoT console. In the next few lines, you will code the inference loop.
The following code allows AWS DeepLens to access the latest frame on the mjpeg stream. This is the input stream from the AWS DeepLens camera. awscam.getLastFrame captures the last or latest frame from the stream to parse and perform inference. raise Exception allows the function to raise an exception if it fails to get the frame from the stream.
Now for image pre-processing. The input frame from the camera is different from the input dimensions that the model is trained on. You defined the input parameters of the model earlier. In this step, resize the input frame from the camera to the input dimensions of the model. In this example, you only need to downsample the frame to fit the model input parameters. Depending on the model that you have trained, you might need to perform other pre-processing steps, such as image normalization.
Now the frame from the pre-processed step is ready for inference. The preceding code outputs the results of the model as a dictionary with the last layer’s name. The output data is not parsed into a human-readable format. If you use this output as is, you have to implement your own parsing algorithm. AWS DeepLens provides an easy interface to parse the network outputs for supported model types. The following method returns a dictionary with the model_type as its key and a second dictionary as its value. The second dictionary has label and probability keys to allow you to retrieve the non-human readable label and the associated probability.
You can customize the code to display only the top ‘n’ results from the output. In this example, we have customized it to display the top 5 entries. Entries are displayed in descending order, starting with the entry with the highest probability.
Now that you have the results, send it to the cloud. Notice that we put the results in json format so that other Lambda functions on the cloud can subscribe to this IoT topic and perform an action when they detect a particular event of interest. For example, at the re:Invent workshops, we deployed a Lambda function in the cloud that sent an SMS message every time a hot dog was detected. Also notice how you used the labels list that you constructed before entering the loop to convert the labels that the network outputs into human-readable labels.
Now that the message is in json format, send it to the cloud with AWS IoT.
Now that the data is in the cloud, post-process the image to view it on mplayer. In this case, do simple post- processing to add a label to the original 4 megapixel image by using openCV. You can customize this step to suit your requirements.
After post-processing, update the global jpeg variable so that you can view the results using mplayer.
Optionally, you might want to add code that catches the exceptions if something goes wrong and sends them to the cloud. Use the following code for this.
Now, run the function and view the results!
Be sure to save the code and publish it. If you do not publish the function, you will not be able to view the inference Lambda function in your AWS DeepLens console.
Congratulations! You just created a Lambda function that you can use for inference with a squeezenet model. And you used the Model Optimizer.
You can access the squeezenet model here.
If you have any questions or looking for help, see the AWS DeepLens forum.
About the Authors
 Jyothi Nookula is a Senior Product Manager for AWS DeepLens. She loves to build products that delight her customers. In her spare time, she loves to paint and host charity fund raisers for her art exhibitions.
Jyothi Nookula is a Senior Product Manager for AWS DeepLens. She loves to build products that delight her customers. In her spare time, she loves to paint and host charity fund raisers for her art exhibitions.
 Eddie Calleja is a Software Development Engineer for AWS Deep Learning. He is one of the developers of the DeepLens device. As a former physicist he spends his spare time thinking about applying AI techniques to modern day physics problems.
Eddie Calleja is a Software Development Engineer for AWS Deep Learning. He is one of the developers of the DeepLens device. As a former physicist he spends his spare time thinking about applying AI techniques to modern day physics problems.