Artificial Intelligence
DXC Technology automates triage of support tickets using AWS machine learning
DXC Technology is a global IT service leader providing end-to-end services on Digital Transformation to businesses and governments. They also provide service management to their clients on-premises and in the cloud. The incident tickets raised as part of the process need to be resolved quickly to meet their service level agreements (SLA). DXC has goals to reduce human effort, reduce incident resolution time, enhance knowledge management, and enhance consistency of incident resolution. With these goals in mind, DXC developed a knowledge management (KM) article prediction mechanism.
In this blog post, we’ll discuss how DXC uses machine learning on AWS to automatically identify a KM article, which in turn can be automated with the orchestration runbook for ticket resolution to make IT support more efficient.
The DXC solution on AWS
First: Build a data lake on Amazon S3
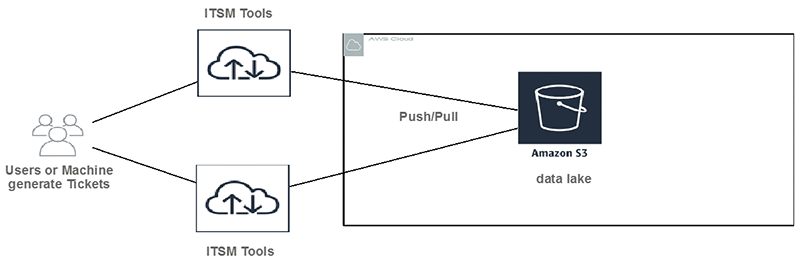
DXC customers submit incident tickets to IT Service Management Tools (ITSM). Tickets can be user generated or machine generated. Then data is pushed or pulled to Amazon S3 buckets. Amazon S3 provides low cost, highly durable object storage that can store any form or format of data.
Second: Choose the right machine learning tool and algorithm
Typically, the problem is how to classify text. AWS offers a variety of choices for customers to do text classifications. DXC evaluated the following AWS services.
- Amazon SageMaker with its built-in algorithm called BlazingText.
- Amazon Comprehend custom classification.
The Amazon Comprehend custom classification API was good choice since it is built ground-up for text classification. With Amazon Comprehend, we didn’t have to pick an algorithm, tune it and re-train our model looking for the highest accuracy – the API did this automatically. We plan to re-evaluate it when it supports synchronous calls (today it provide batch-mode classification).
Amazon SageMaker BlazingText implements the fastText algorithm and keep the right balance between scalability and accuracy.
Third: Train the model
Training data preparations:
Training the model is the most important part of the ML process. Training of supervised models requires labeled data. The DXC team wanted to label a significant amount of historical data for this purpose. In the pre-processing step, the text data was tokenized using NLTK (Python library) and stored in CSV format in Amazon S3 for the training. The training is done once a month with the historical data.
The tokenized training data looks like this. It is used as input to the training job.

Training job with hyperparameter optimization (HPO)
We use the automatic model tuning feature of Amazon SageMaker to automate and accelerate the search of hyperparameters for the BlazingText algorithm.
Initially, we set static hyperparameters that we don’t need to change across training jobs, and we also define ranges for the hyperparameters that need optimizations.
Note: All the parameter values mentioned in the code below are sample values. You need to test and use your own values based on your requirements.
Next, we instantiated the estimator and the HPO tuner. Then we triggered the training job using training data available on Amazon S3.
Fourth: Orchestrate data preparation, model training, and model deployment on Amazon SageMaker using AWS Step Functions
We orchestrated this ML workflow using AWS Step Functions, and we scheduled using an Amazon Cloud Watch Events rule.
AWS Step Functions performs the following steps:
- It checks that the Amazon S3 bucket exists where input data for training is present.
- It pre-processes the data set for model training.
- It starts the training job in Amazon SageMaker with the required parameters.
- It keeps checking the status of training job.
- After the training is successful, it validates the model.
- After the model validated, it deploys the model as Amazon SageMaker endpoints. (If the model endpoint exists, then it updates the model endpoint.)
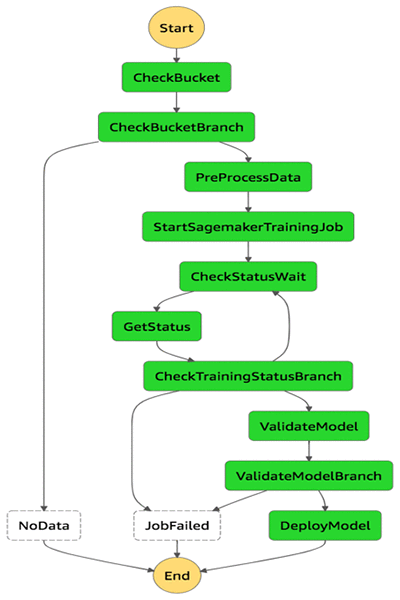
All o f these steps are developed as AWS Lambda functions.
Note: During AWS re:Invent 2018, a new feature was released that allowed Step Functions to be directly integrated with Amazon SageMaker. This feature can be used to develop some of the steps described earlier without writing Lambda functions. However, the feature was not available when DXC developed this solution.
Fifth: Call the inference
As soon as new ITSM tickets get ingested to an Amazon S3 bucket, an AWS Lambda function is triggered to call the inference using Amazon SageMaker endpoints.
The Lambda function reads the ticket number and description from incoming files and creates a payload like the following:

Then, it calls the Amazon SageMaker model endpoint with payload information:
It creates a CSV output and stores it on Amazon S3. The output looks like the following example. It stores the ticket number, the predicted KB document, and confidence level.
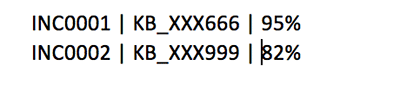
Sixth: Build a CI/CD pipeline to automate the solution deployment
DXC developed a CI/CD pipeline using Ansible, Jenkins, and AWS CloudFormation templates to automate the deployment of the whole solution.
Seventh: Enable it for the support team
After the predictions are generated, they can be accessed using API endpoints based on Incident Identifiers or Incident Descriptions. Incident Descriptions are more suitable for real-time resolution of issues. It’s possible that you don’t even need to create a ticket. The description of an issue when checked against the Amazon SageMaker endpoint results in the output of a KM article identifier that can be referred offline, which might lead to the resolution of the issue. In this scenario, no ticket had to be created.
In the case where ticket has been created, a Service Desk Agent can use a chatbot that makes a call to the API or uses the API directly by providing the Incident Identifier. The output of the Incident Identifier is a KM article identifier. This can be quickly referred to offline for incident resolution, hence reducing the incident resolution time.
And further integration with runbook automation will result in the automation of ticket resolution with little or zero human effort.
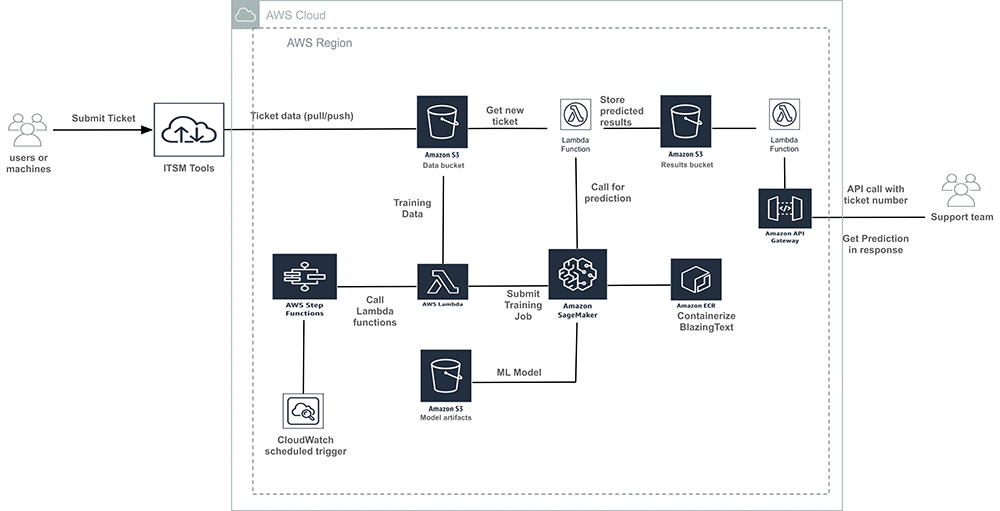
The end-to-end solution
The overall architecture looks like this.
Conclusion – What did DXC achieve?
To summarize, the KM article prediction mechanism realized the following benefits:
- Improved the support team’s efficiency. The support team can almost instantly know which KM article to be looked at for solving the ticket.
- This prediction mechanism also can be used as a self-service tool where users can enter ticket descriptions and get back the KM article to solve their own issue. This will also reduce the number of tickets.
- Integration of this mechanism with runbook automation will help automate resolution of tickets too.
About the Authors

Sougata Biswas is a big data architect at AWS Professional Services. He helps AWS customers in architecting and implementing solutions on AWS to get business value out of data.
 Sofian Hamiti is a data scientist at Amazon ML Solutions Lab. He helps AWS customers across different industries accelerate their AI and cloud adoption.
Sofian Hamiti is a data scientist at Amazon ML Solutions Lab. He helps AWS customers across different industries accelerate their AI and cloud adoption.
Thanks to DXC team who worked on the project. Special thanks to following leaders from DXC who encouraged and reviewed the blog post.
Niladri Chowdhury, Manager of Data Engineering and Analytics Mgr Operations Engineering and Excellence (OE&E) at DXC Tech. He leads a team of Analysts, Data Engineers and Data Scientists to design, build and deploy the best of the class Business Intelligence delivery solutions in cloud
William Giotto, Global Product Owner at DXC Tech. He aligns efforts towards a vision of Intelligent Automation. Full time father, data science enthusiastic and amateur astronomer (www.astrogiotto.com)